
Merge remote-tracking branch 'upstream/dygraph' into dy3
Showing
doc/doc_en/inference_en.md
100644 → 100755
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}

129 KB
{kind=link}

94 KB
{kind=link}

236 KB
{kind=link}

81.7 KB
{kind=link}

147 KB
{kind=link}
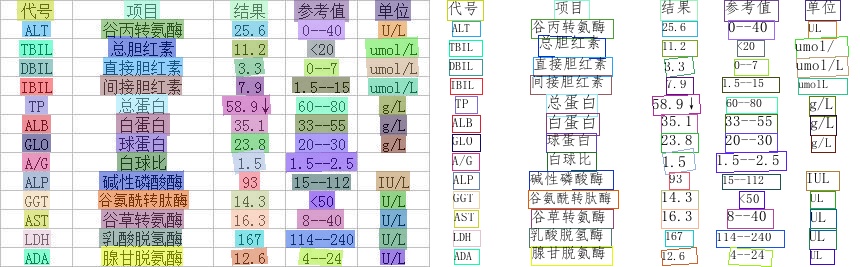
124 KB
{kind=link}
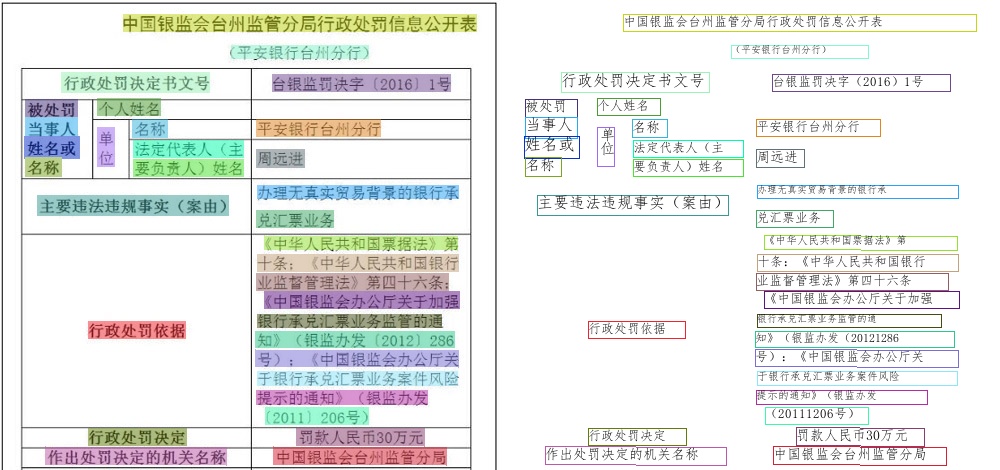
164 KB
{kind=link}

137 KB
{kind=link}

284 KB
{kind=link}

244 KB
{kind=link}

180 KB
{kind=link}

305 KB