
Merge branch 'dygraph' of https://github.com/PaddlePaddle/PaddleOCR into dev/add_thread_pred
Showing
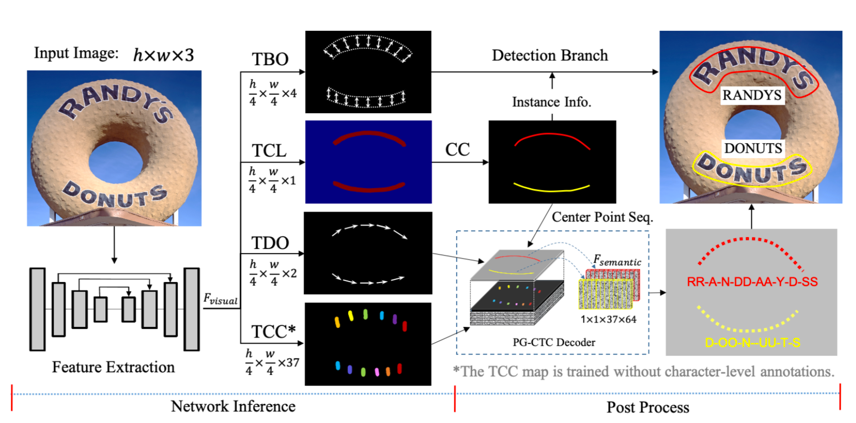
doc/doc_ch/pgnet.md
0 → 100644
{kind=link}

663 KB
{kind=link}

467 KB
{kind=link}

134 KB
{kind=link}

337 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
doc/pgnet_framework.png
0 → 100644
{kind=link}
242 KB
ppocr/data/pgnet_dataset.py
0 → 100644
ppocr/losses/e2e_pg_loss.py
0 → 100644