
Merge pull request #5989 from MissPenguin/dygraph
update docs
Showing
doc/doc_ch/application.md
0 → 100644
doc/doc_ch/ocr_book.md
0 → 100644
doc/doc_ch/table_datasets.md
0 → 100644
doc/doc_en/algorithm_en.md
0 → 100644
doc/doc_en/ocr_book_en.md
0 → 100644
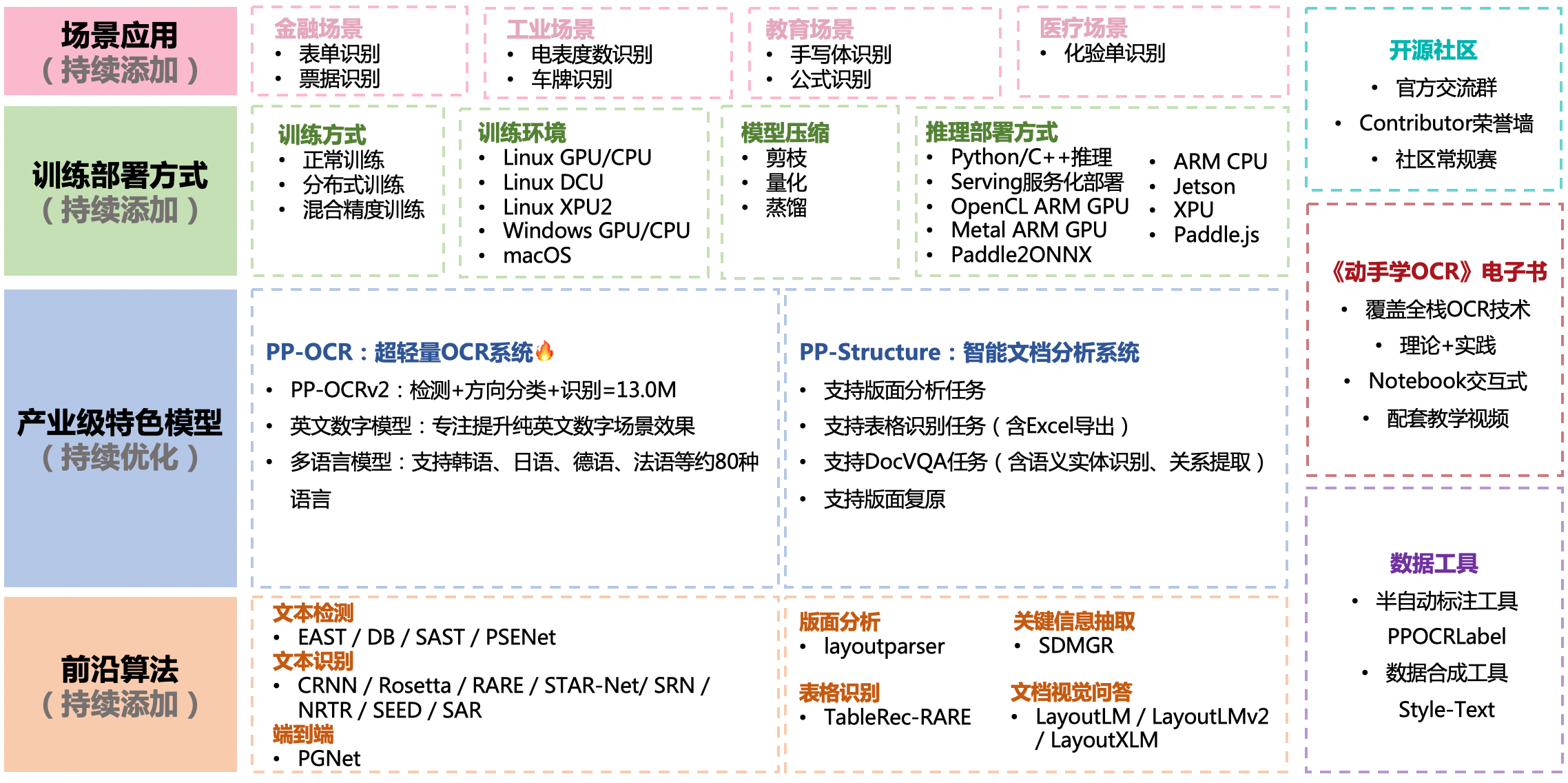
doc/features.png
0 → 100644
{kind=link}
1.15 MB