# Llama, Mistral and other Llama-like model support in Megatron-LM
NOTE: Llama-3 and Mistral support in Megatron is currently experimental and we are still evaluting benchmark results to confirm model conversion, training and inference correctness.
The [Llama-2](https://ai.meta.com/llama/) and [Llama-3](https://llama.meta.com/) family of models are an open-source set of pretrained & finetuned (for chat) models that have achieved strong results across a wide set of benchmarks. At their times of release, both Llama-2 and Llama-3 models achieved among the best results for open-source models, and were competitive with leading closed-source models (see https://arxiv.org/pdf/2307.09288.pdf and https://ai.meta.com/blog/meta-llama-3/).
Similarly, [Mistral-7b](https://mistral.ai/news/announcing-mistral-7b/) is an open-source model with pretrained and finetuned (for chat) variants that achieve strong benchmark results.
Architecturally Llama-2, Llama-3 and Mistral-7b are very similar. As such Megatron can support loading checkpoints from all three for inference and finetuning. Converting the checkpoints and loading them is slightly different for each model and is detailed for each below.
# Llama-2
Llama-2 checkpoints can be loaded into Megatron for inference and for finetuning. Loading these checkpoints consists of three steps:
1. Get access to download the checkpoints.
2. Convert the checkpoints from Meta/Huggingface format to Megatron format.
3. Setup arguments for launching the model.
The following sections detail these steps. The final section lists benchmark result comparisons between: 1) Llama-2 inference code running the Meta-format checkpoints, and 2) Megatron inference code running the converted checkpoints.
## Contents
*[Download Meta or Huggingface checkpoints](#download-meta-or-huggingface-checkpoints)
Users must first apply for access to download the Llama-2 checkpoints either directly from [Meta](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) or through [Huggingface](https://huggingface.co/docs/transformers/main/model_doc/llama2)(HF). The checkpoints are available in two formats, Meta's native format (available from both the Meta and HF links), and HF's format (available only from HF). Either format can be converted to Megatron, as detailed next.
## Convert checkpoint format
We recommend passing `--dtype bf16` for training or finetuning. Inference can be done in bfloat16 or float16.
### Meta format
The Meta format checkpoints are converted to HF format as an intermediate step before converting to Megatron format. The `transformers` package is required, and must have version >=4.31.0 (e.g., `pip install transformers>=4.31.0`). (**Note**: we have specifically tested with versions `4.31.0` and `4.32.0`; your experience may vary with newer versions.) Assuming the downloaded checkpoints are in `$CHECKPOINT_DIR` (with separate sub-directories for 7B, 13B, 70B, etc.), the following example command can be used to convert from Llama-2 format to HF format in bfloat16:
Valid values for `--model-size` are `llama2-7B`, `llama2-13B`, and `llama2-70B` (for pretrained-only models), and `llama2-7Bf`, `llama2-13Bf`, and `llama2-70Bf` (for chat-finetuned models).
### Huggingface format
The HF checkpoints can be converted to Megatron format by using Megatron's own Llama-2 checkpoint converter for HF format (see script `tools/checkpoint/loader_llama_mistral.py`). One important argument that must be set correctly is the tensor parallel size (`TP`) for each model. The following table shows these values:
| Model size | Tensor parallel size (`TP`) |
| ---------- | --------------------------- |
| 7B | 1 |
| 13B | 2 |
| 70B | 8 |
Using these values for `TP`, along with the path to the Llama-2 tokenizer model (automatically downloaded with original checkpoint download; see `${TOKENIZER_MODEL}` below), run the following command from the root of your Megatron source code to convert from HF format to Megatron format:
```
$>: python tools/checkpoint/convert.py \
> --model-type GPT \
> --loader llama_mistral \
> --saver megatron \
> --target-tensor-parallel-size ${TP} \
> --checkpoint-type hf
> --load-dir ${HF_FORMAT_DIR} \
> --save-dir ${MEGATRON_FORMAT_DIR} \
> --tokenizer-model ${TOKENIZER_MODEL}
```
After this conversion, we are ready to load the checkpoints into a Megatron GPT model.
## Launch model
### Launch Megatron
If loading for either inference or finetuning, use the following arguments:
```
--tensor-model-parallel-size ${TP} \
--pipeline-model-parallel-size 1 \
--seq-length 4096 \
--max-position-embeddings 4096 \
--tokenizer-type Llama2Tokenizer \
--tokenizer-model ${TOKENIZER_MODEL} \
--load ${CHECKPOINT_DIR} \
--exit-on-missing-checkpoint \
--use-checkpoint-args \
--no-load-optim \
--no-load-rng \
--untie-embeddings-and-output-weights \
--use-rotary-position-embeddings \
--normalization RMSNorm \
--no-position-embedding \
--no-masked-softmax-fusion \
--attention-softmax-in-fp32
```
### Launch Meta
Meta checkpoints can be launched with: https://github.com/facebookresearch/llama
### Launch Huggingface
Huggingface checkpoints can be launched with: https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py
## Benchmark results
The tables below list the benchmark comparisons between native Llama-2 (using Meta's checkpoint and Meta's inference code) and Megatron (using a converted HF checkpoint and Megatron's inference code).
The values are the percent error between Megatron and Llama-2, calculated using the formula: `|<llama_score> - <megatron_score>| / <llama_score>`, where the type of score is detailed before each table. Across all tests (80 total per model size), the mean error is 0.15%. The small difference in benchmark scores between the two models is due to minor arithmetic differences in implementation that alter the numerics slightly. Some of the factors that influence this difference include:
- Megatron performs batch matrix multiplications in a couple places, such as within self attention and in SwiGLU, that Llama performs separately.
- Megatron uses `torch.baddbmm` within self attention, versus Llama using `torch.matmul`.
- Megatron uses a `sin`/`cos` implementation for rotary position embeddings, versus Llama using a `polar`/`complex` implementation.
- Llama calls `torch.set_default_dtype(torch.float16)` during initialization, which Megatron does not.
Users must first apply for access to download the Llama-3 checkpoints either directly from [Meta](https://llama.meta.com/llama-downloads) or through [Huggingface](https://huggingface.co/meta-llama)(HF). The checkpoints are available in two formats, Meta's native format (available from both the Meta and HF links), and HF's format (available only from HF). Either format can be converted to Megatron, as detailed next.
## Install tiktoken
The Llama-3 tokenizer relies on the availability of the `tiktoken` module which can be installed through `pip`.
## Install llama package from Meta
1. In a location outside of the megatron-lm source directory, e.g `~`: `git clone https://github.com/meta-llama/llama3.git`
2.`cd $LLAMA3_SOURCE_DIR`
4.`pip install -e .`
## Convert checkpoint format
We recommend passing `--dtype bf16` for training or finetuning. Inference can be done in bfloat16 or float16.
### Meta format
The Meta format checkpoints are converted to HF format as an intermediate step before converting to Megatron format. The `transformers` package is required, and must have version >=4.31.0 (e.g., `pip install transformers>=4.31.0`). (**Note**: we have specifically tested with versions `4.31.0` and `4.32.0`; your experience may vary with newer versions.) Assuming the downloaded checkpoints are in `$CHECKPOINT_DIR` (with separate sub-directories for 8B, 70B, etc.), the following example command can be used to convert from Llama-3 format to HF format in bfloat16:
```
python tools/checkpoint/convert.py \
> --model-type GPT \
> --loader llama_mistral \
> --saver mcore \
> --checkpoint-type meta \
> --model-size llama3-8B \
> --load-dir $LLAMA_META_FORMAT_DIR \
> --save-dir ${MEGATRON_FORMAT_DIR} \
> --tokenizer-model ${TOKENIZER_MODEL} \
> --target-tensor-parallel-size ${TP} \
> --target-pipeline-parallel-size ${PP} \
> --bf16
```
Valid values for `--model_size` are `llama3-8B` and `llama3-70B` (for pretrained-only models), and `llama3-8Bf` and `llama3-70Bf` (for chat-finetuned models).
### Huggingface format
The HF checkpoints can be converted to Megatron format by using Megatron's own Llama-3 checkpoint converter for HF format (see script `tools/checkpoint/loader_llama_mistral.py`). One important argument that must be set correctly is the tensor parallel size (`TP`) for each model. The following table shows these values:
| Model size | Tensor parallel size (`TP`) |
| ---------- | --------------------------- |
| 8B | 1 |
| 70B | 8 |
Using these values for `TP`, along with the path to the Llama-3 tokenizer model (automatically downloaded with original checkpoint download; see `${TOKENIZER_MODEL}` below), run the following command from the root of your Megatron source code to convert from HF format to Megatron format:
```
$>: python tools/checkpoint/convert.py \
> --model-type GPT \
> --loader llama_mistral \
> --saver mcore \
> --target-tensor-parallel-size ${TP} \
> --checkpoint-type hf
> --load-dir ${HF_FORMAT_DIR} \
> --save-dir ${MEGATRON_FORMAT_DIR} \
> --tokenizer-model ${TOKENIZER_MODEL}
> --model-size llama3-8B \
```
Valid values for `--model-size` are `llama3-8B` and `llama3-70B` (for pretrained-only models), and `llama3-8Bf` and `llama3-70Bf` (for chat-finetuned models).
After this conversion, we are ready to load the checkpoints into a Megatron GPT model.
## Launch model
### Launch Megatron
If loading for either inference or finetuning, use the following arguments:
```
--tensor-model-parallel-size ${TP} \
--pipeline-model-parallel-size 1 \
--seq-length 4096 \
--max-position-embeddings 4096 \
--tokenizer-type Llama3Tokenizer \
--tokenizer-model ${TOKENIZER_MODEL} \
--load ${CHECKPOINT_DIR} \
--exit-on-missing-checkpoint \
--use-checkpoint-args \
--no-load-optim \
--no-load-rng \
--untie-embeddings-and-output-weights \
--normalization RMSNorm \
--position-embedding-type rope \
--no-masked-softmax-fusion \
--attention-softmax-in-fp32
```
### Launch Meta
Meta checkpoints can be launched with: https://github.com/meta-llama/llama3
### Launch Huggingface
Huggingface checkpoints can be launched by following the instructions here: https://huggingface.co/blog/llama3
## Benchmark results
Llama-3 support in Megatron is currently experimental and we are still carrying out benchmark evaluations.
# Mistral-7b
Megatron currently supports loading the v.03 release of Mistral-7b (which does not use sliding window attention and offers a larger 32768 vocabulary) for inference and finetuning. Loading these checkpoints consists of several steps:
1. Get access to download the checkpoints (weights and tokenizer).
2. Install the `mistral-common` package
3. Convert the checkpoints from HuggingFace format to Megatron format.
Users must first apply for access to download the Mistral-7b checkpoints through [Huggingface](https://huggingface.co/mistralai/Mistral-7B-v0.3)(HF). Megatron does not currently support the v0.1 or v0.2 checkpoints, ensure you download v0.3. Megatron also does not currently support using the raw weights directly from [Mistral](https://docs.mistral.ai/getting-started/open_weight_models/).
## Install the mistral-common package
`pip install mistral-common`
## Convert checkpoint format
The HF checkpoints can be converted to Megatron format by using Megatron's own Mistral checkpoint converter for HF format (see script `tools/checkpoint/loader_llama_mistral.py`).
Using the path to the Mistral tokenizer model (downloaded alongside the HF checkpoint), run the following command from the root of your Megatron source code to convert from HF format to mcore format:
```
$>: python tools/checkpoint/convert.py \
> --model-type GPT \
> --loader llama_mistral \
> --saver mcore \
> --target-tensor-parallel-size ${TP} \
> --checkpoint-type hf \
> --load-dir ${HF_FORMAT_DIR} \
> --save-dir ${MEGATRON_FORMAT_DIR} \
> --tokenizer-model ${TOKENIZER_MODEL} \
> --model-size mistral-7B \
```
Valid values for `--model-size` are mistral-7B for the pretrained model or mistral-7Bf for the chat fine-tuned model.
After this conversion, we are ready to load the checkpoints into an mcore GPT model.
## Launch model
If loading for either inference or finetuning, use the following arguments:
```
--tensor-model-parallel-size ${TP} \
--pipeline-model-parallel-size 1 \
--seq-length 4096 \
--max-position-embeddings 4096 \
--tokenizer-type MistralTokenizer \
--tokenizer-model ${TOKENIZER_MODEL} \
--load ${CHECKPOINT_DIR} \
--exit-on-missing-checkpoint \
--use-checkpoint-args \
--no-load-optim \
--no-load-rng \
--untie-embeddings-and-output-weights \
--normalization RMSNorm \
--position-embedding-type rope \
--no-masked-softmax-fusion \
--attention-softmax-in-fp32
```
## Benchmark results
Mistral-7B support in Megatron is currently experimental and we are still carrying out benchmark evaluations.
# Other Llama-like model support
*Note: Experimental*
Many models such as Yi-34B use the Llama architecture and may be converted from HuggingFace to Megatron using the commands in [Llama3](#llama-3).
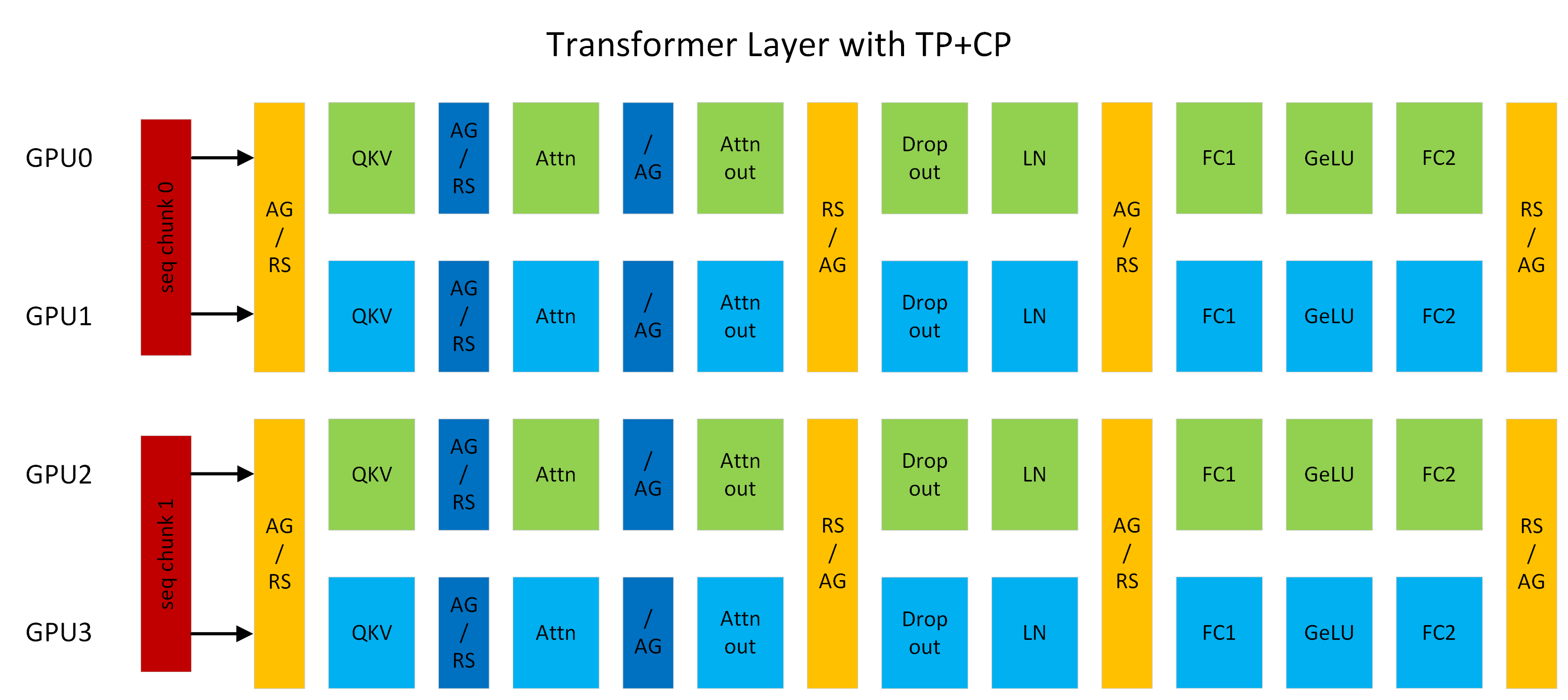
Figure 1: A transformer layer running with TP2CP2. Communications next to Attention are for CP, others are for TP. (AG/RS: all-gather in forward and reduce-scatter in backward, RS/AG: reduce-scatter in forward and all-gather in backward, /AG: no-op in forward and all-gather in backward).
Context Parallelism ("CP") is a parallelization scheme on the dimension of sequence length. Unlike prior SP (sequence parallelism) which only splits the sequence of Dropout and LayerNorm activations, CP partitions the network inputs and all activations along sequence dimension. With CP, all modules except attention (e.g., Linear, LayerNorm, etc.) can work as usual without any changes, because they do not have inter-token operations. As for attention, the Q (query) of each token needs to compute with the KV (key and value) of all tokens in the same sequence. Hence, CP requires additional all-gather across GPUs to collect the full sequence of KV. Correspondingly, reduce-scatter should be applied to the activation gradients of KV in backward propagation. To reduce activation memory footprint, each GPU only stores the KV of a sequence chunk in forward and gathers KV again in backward. KV communication happens between a GPU and its counterparts in other TP groups. The all-gather and reduce-scatter are transformed to point-to-point communications in ring topology under the hood. Exchanging KV also can leverage MQA/GQA to reduce communication volumes, as they only have one or few attention heads for KV.
For example, in Figure 1, assuming sequence length is 8K, each GPU processes 4K tokens. GPU0 and GPU2 compose a CP group, they exchange KV with each other. Same thing also happens between GPU1 and GPU3. CP is similar to `Ring Attention <https://arxiv.org/abs/2310.01889>`_ but provides better performance by (1) leveraging the latest OSS and cuDNN flash attention kernels; (2) removing unnecessary computation resulted from low-triangle causal masking and achieving optimal load balance among GPUs.
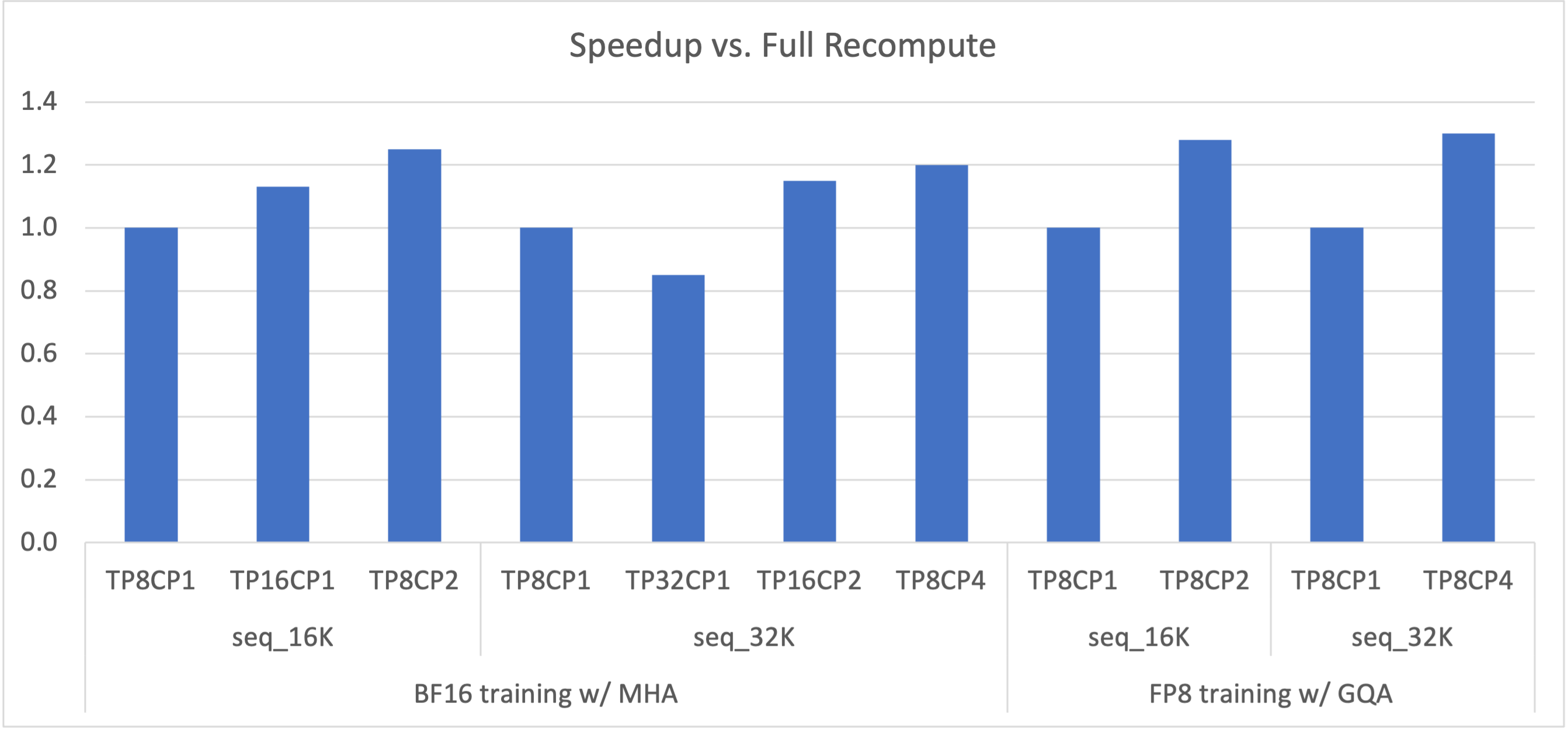
Figure 2: Speedup of 175B GPT with various TP+CP combinations vs. full recompute (i.e., TP8CP1).
LLM encounters OOM (out of memory) issue with long context (i.e., long sequence length) because of linearly increasing memory footprint of activations. Recomputing activations in backward can avoid OOM but also introduce significant overheads (~30% with full recompute). Enlarging TP (tensor model parallelism) can fix the OOM issue as well, but it potentially makes compute (e.g., Linear) too short to overlap communication latencies. To be clear, scaling out to more GPUs with bigger TP can hit the overlapping problem no matter if OOM happens.
CP can better address the issues. With CP, each GPU only computes on a part of the sequence, which reduces both computation and communication by CP times. Therefore, there are no concerns about the overlapping between them. The activation memory footprint per GPU is also CP times smaller, hence no OOM issue any more. As Figure 2 shows, the combinations of TP and CP can achieve optimal performance by eliminating recompute overheads and making the best tradeoff between computation and communications.
Enabling context parallelism
----------------------------
CP support has been added to GPT. All models that share GPT code path also should be able to benefit from CP, such as Llama. CP can work with TP (tensor model parallelism), PP (pipeline model parallelism), and DP (data parallelism), where the total number of GPUs equals TPxCPxPPxDP. CP also can work with different attention variants, including MHA/MQA/GQA, uni-directional and bi-directional masking.
CP is enabled by simply setting context_parallel_size=<CP_SIZE> in command line. Default context_parallel_size is 1, which means CP is disabled. Running with CP requires Megatron-Core (>=0.5.0) and Transformer Engine (>=1.1).
Package defining different checkpoint formats (backends) and saving/loading algorithms (strategies).
Strategies can be used for implementing new checkpoint formats or implementing new (more optimal for a given use case) ways of saving/loading of existing formats.
Strategies are passed to `dist_checkpointing.load` and `dist_checkpointing.save` functions and control the actual saving/loading procedure.
This package provides modules that provide commonly fused
operations. Fusing operations improves compute efficiency by
increasing the amount of work done each time a tensor is read from
memory. To perform the fusion, modules in this either rely on PyTorch
functionality for doing just-in-time compilation
(i.e. `torch.jit.script` in older PyTorch versions of `torch.compile`
in recent versions), or call into custom kernels in external libraries
such as Apex or TransformerEngine.
Submodules
----------
fusions.fused\_bias\_dropout module
-----------------------------------
This module uses PyTorch JIT to fuse the bias add and dropout operations. Since dropout is not used during inference, different functions are used when in train mode and when in inference mode.
.. automodule:: core.fusions.fused_bias_dropout
:members:
:undoc-members:
:show-inheritance:
fusions.fused\_bias\_gelu module
--------------------------------
This module uses PyTorch JIT to fuse the bias add and GeLU nonlinearity operations.
.. automodule:: core.fusions.fused_bias_gelu
:members:
:undoc-members:
:show-inheritance:
fusions.fused\_layer\_norm module
---------------------------------
This module provides a wrapper around various fused LayerNorm implementation in Apex.
.. automodule:: core.fusions.fused_layer_norm
:members:
:undoc-members:
:show-inheritance:
fusions.fused\_softmax module
-----------------------------
This module provides wrappers around variations of Softmax in Apex.
.. automodule:: core.fusions.fused_softmax
:members:
:undoc-members:
:show-inheritance:
fusions.fused\_cross\_entropy\_loss module
------------------------------------------
This module uses PyTorch JIT to fuse the cross entropy loss calculation and batches communication calls.
This is the implementation of the popular GPT model. It supports several features like model parallelization (Tensor Parallel, Pipeline Parallel, Data Parallel) , mixture of experts, FP8 , Distributed optimizer etc. We are constantly adding new features. So be on the lookout or raise an issue if you want to have something added.
This package contains most of the popular LLMs . Currently we have support for GPT, Bert, T5 and Retro . This is an ever growing list so keep an eye out.
The motivation for the distributed optimizer is to save memory by distributing the optimizer state evenly across data parallel ranks, versus the current method of replicating the optimizer state across data parallel ranks. As described in https://arxiv.org/abs/1910.02054, this branch specifically implements the following:
- [yes] distribute all 'non-overlapping' optimizer state (i.e., model params already in fp32 are NOT distributed)
- [no] distribute model gradients
- [no] distribute model parameters
Theoretical memory savings vary depending on the combination of the model's param dtype and grad dtype. In the current implementation, the theoretical number of bytes per parameter is (where 'd' is the data parallel size):
| | Non-distributed optim | Distributed optim |
| ------ | ------ | ------ |
| float16 param, float16 grads | 20 | 4 + 16/d |
| float16 param, fp32 grads | 18 | 6 + 12/d |
| fp32 param, fp32 grads | 16 | 8 + 8/d |
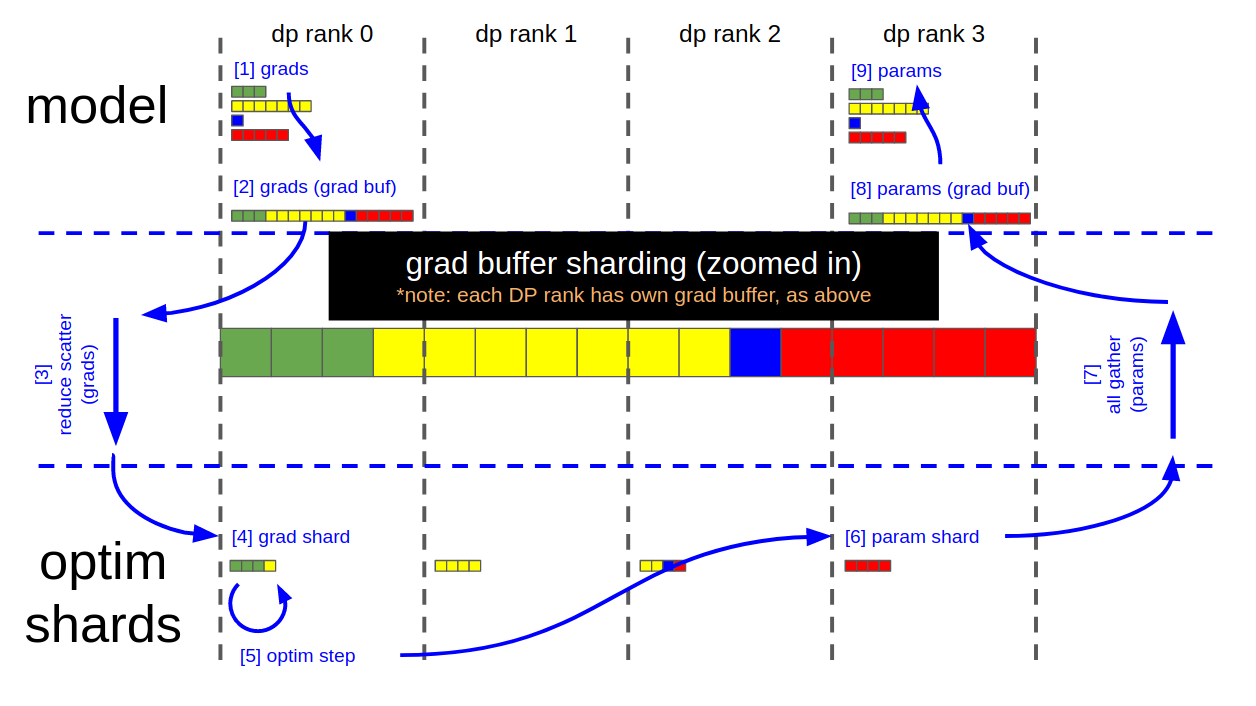
The implementation of the distributed optimizer is centered on using the contiguous grad buffer for communicating grads & params between the model state and the optimizer state. The grad buffer at any given moment either holds:
1. all model grads
2. a 1/d size _copy_ of the main grads (before copying to the optimizer state)
3. a 1/d size _copy_ of the main params (after copying from the optimizer state)
4. all model params
5. zeros (or None), between iterations
The grad buffer is used for performing reduce-scatter and all-gather operations, for passing grads & params between the model state and optimizer state. With this implementation, no dynamic buffers are allocated.
The figures below illustrate the grad buffer's sharding scheme, and the key steps of the distributed optimizer's param update:
- Each DP rank now has 4 elements within the grad buffer that are fully reduced (remaining 12 elements are garbage)
- Each DP rank copies its relevant 4 fp16 grad elements from the grad buffer into 4 fp32 main grad elements (separate buffer, owned by the optimizer); i.e.
- DP rank 0 copies elements [0:4]
- DP rank 1 copies elements [4:8]
- DP rank 2 copies elements [8:12]
- DP rank 3 copies elements [12:16]
- Optimizer.step()
- Each DP rank copies its 4 fp32 main (/optimizer) param elements into the corresponding 4 fp16 elements in the grad buffer
- Call all-gather on each DP rank
- Grad buffer now contains all 16, fully updated, fp16 model param elements
- Copy updated model params from grad buffer into their respective param tensors
- (At this point, grad buffer is ready to be zero'd for the next iteration)

{kind=link}
{kind=link}
{kind=link}