
all
Showing
Too many changes to show.
To preserve performance only 410 of 410+ files are displayed.
examples/multimodal/train.py
0 → 100644
examples/retro/README.md
0 → 100644
examples/t5/README.md
0 → 100644
{kind=link}

61.5 KB
{kind=link}
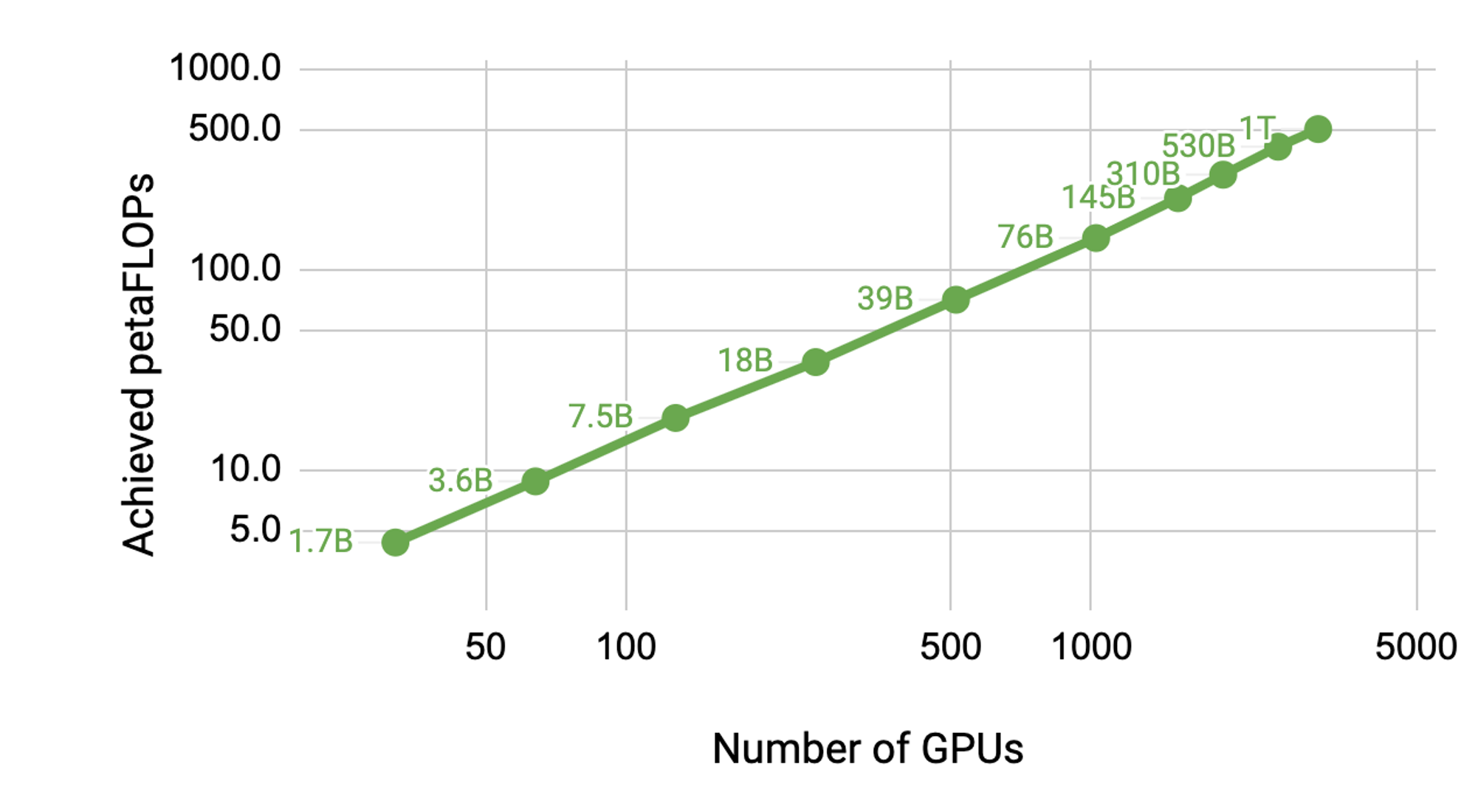
224 KB
images/cases_april2021.png
0 → 100644
{kind=link}
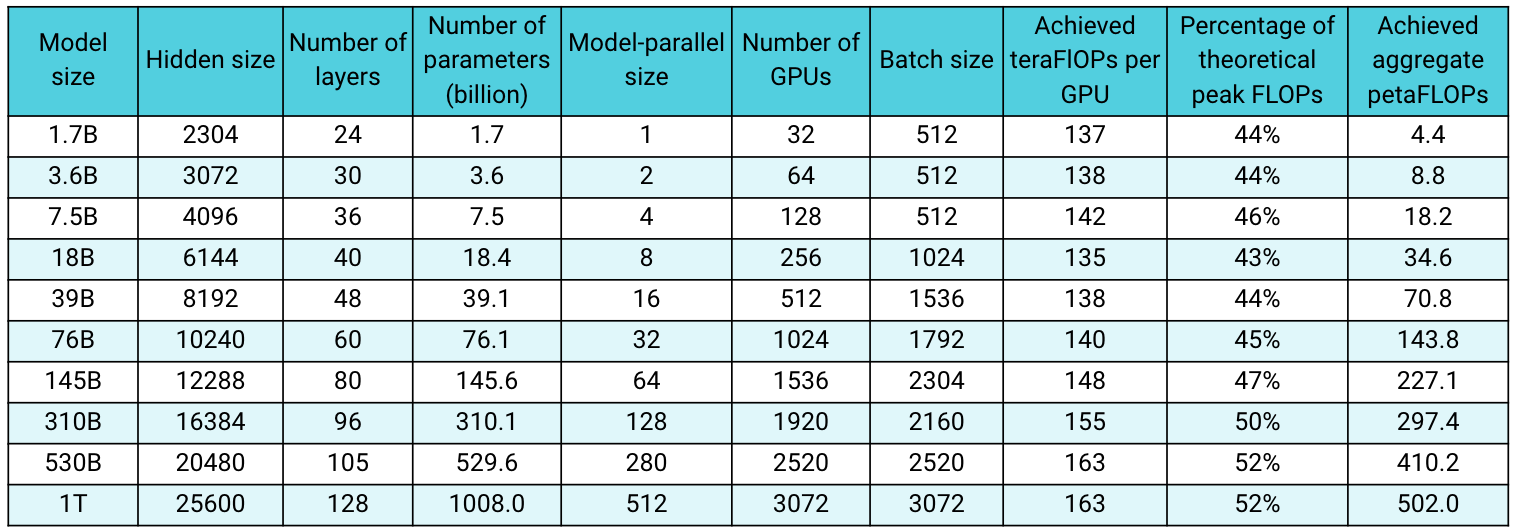
159 KB
kill-all.sh
0 → 100644
kill.sh
0 → 100755
llama3_70b.sh
0 → 100755
llama3_8b.sh
0 → 100755
megatron/core/QuickStart.md
0 → 100644
megatron/core/README.md
0 → 100644
megatron/core/__init__.py
0 → 100644