
init
Showing
3rdparty/.gitignore
0 → 100644
CMakeLists.txt
0 → 100644
CODE_OF_CONDUCT.md
0 → 100644
CONTRIBUTING.md
0 → 100644
LICENSE
0 → 100644
MANIFEST.in
0 → 100644
README.md
0 → 100644
THIRDPARTYNOTICES.txt
0 → 100644
This diff is collapsed.
VERSION
0 → 100644
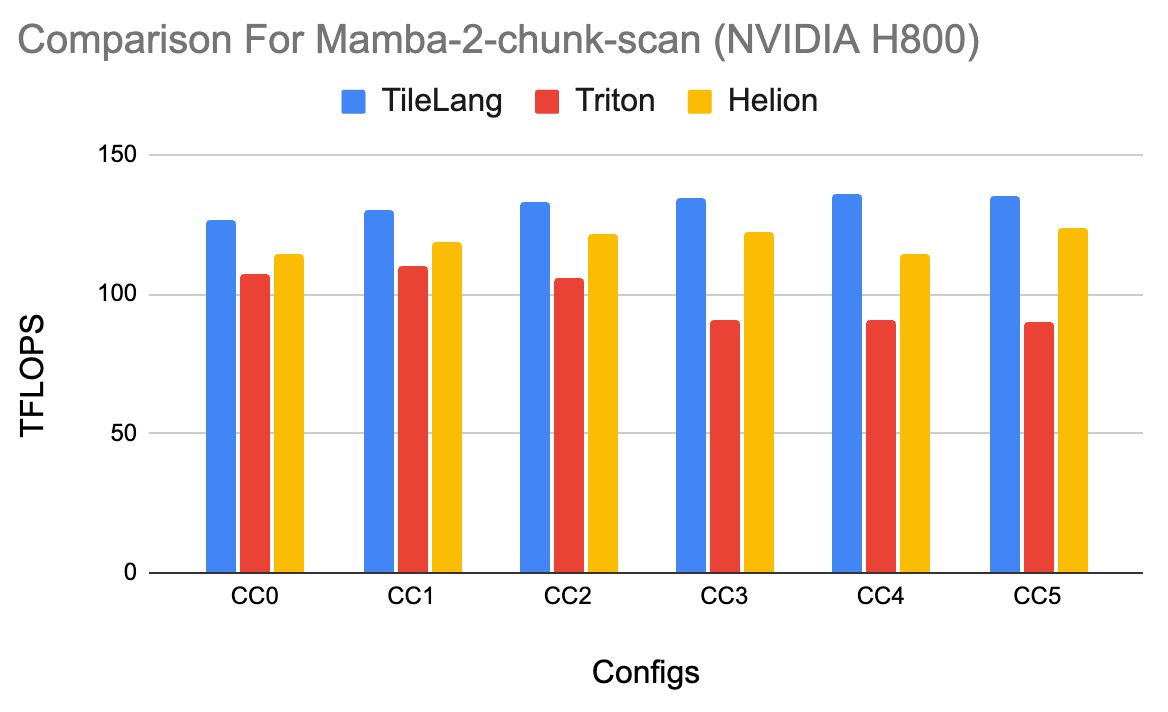
benchmark/mamba2/README.md
0 → 100644
{kind=link}
85.6 KB
benchmark/matmul/README.md
0 → 100644