
init
Showing
.gitignore
0 → 100644
CODE_OF_CONDUCT.md
0 → 100644
CONTRIBUTING.md
0 → 100644
Cargo.lock
0 → 100644
This diff is collapsed.
Cargo.toml
0 → 100644
Dockerfile
0 → 100644
Dockerfile_amd
0 → 100644
Dockerfile_dcu
0 → 100644
Dockerfile_intel
0 → 100644
LICENSE
0 → 100644
Makefile
0 → 100644
README.md
0 → 100644
README_ORINGIN.md
0 → 100644
assets/architecture.png
0 → 100644
{kind=link}
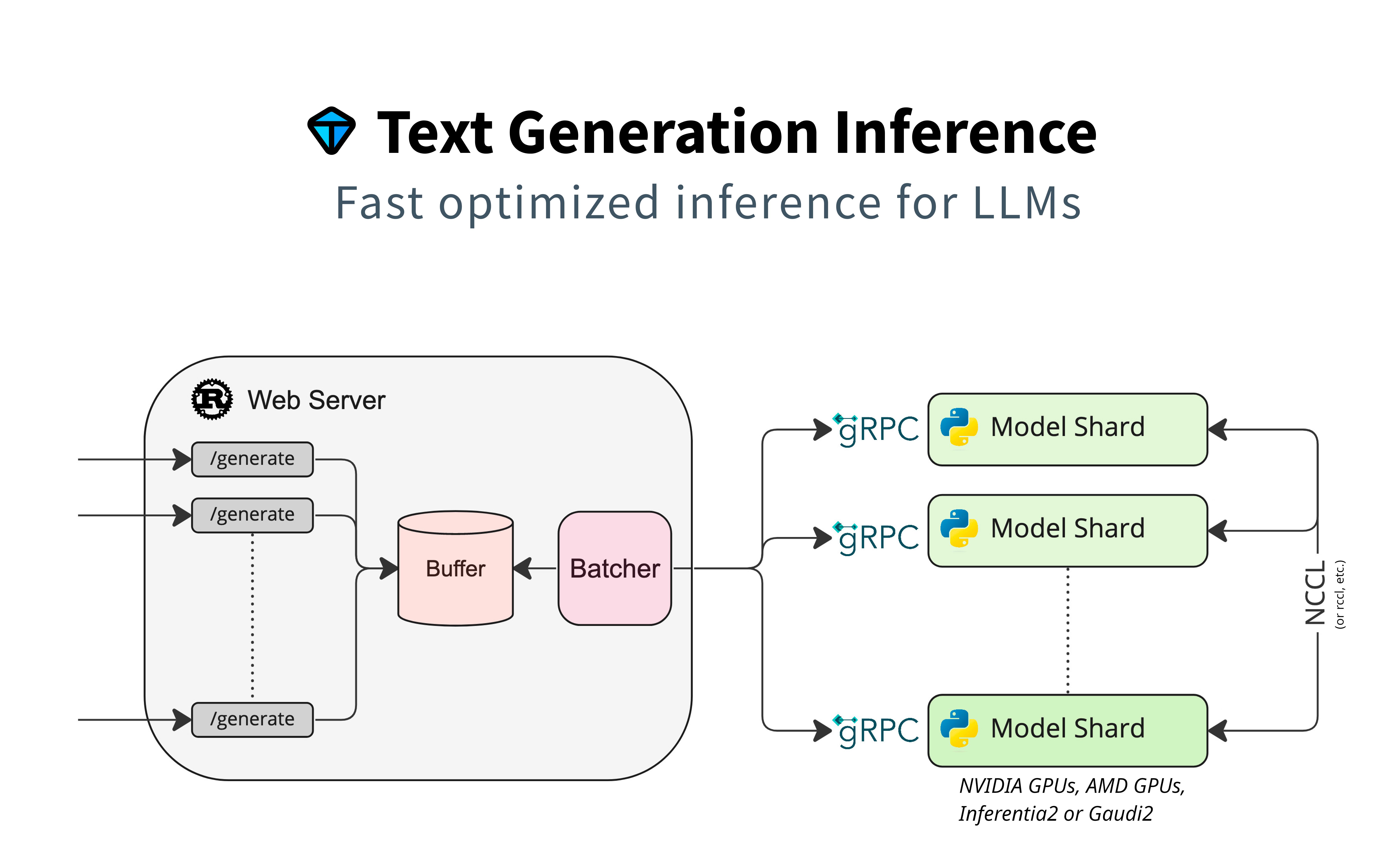
930 KB
assets/benchmark.png
0 → 100644
{kind=link}
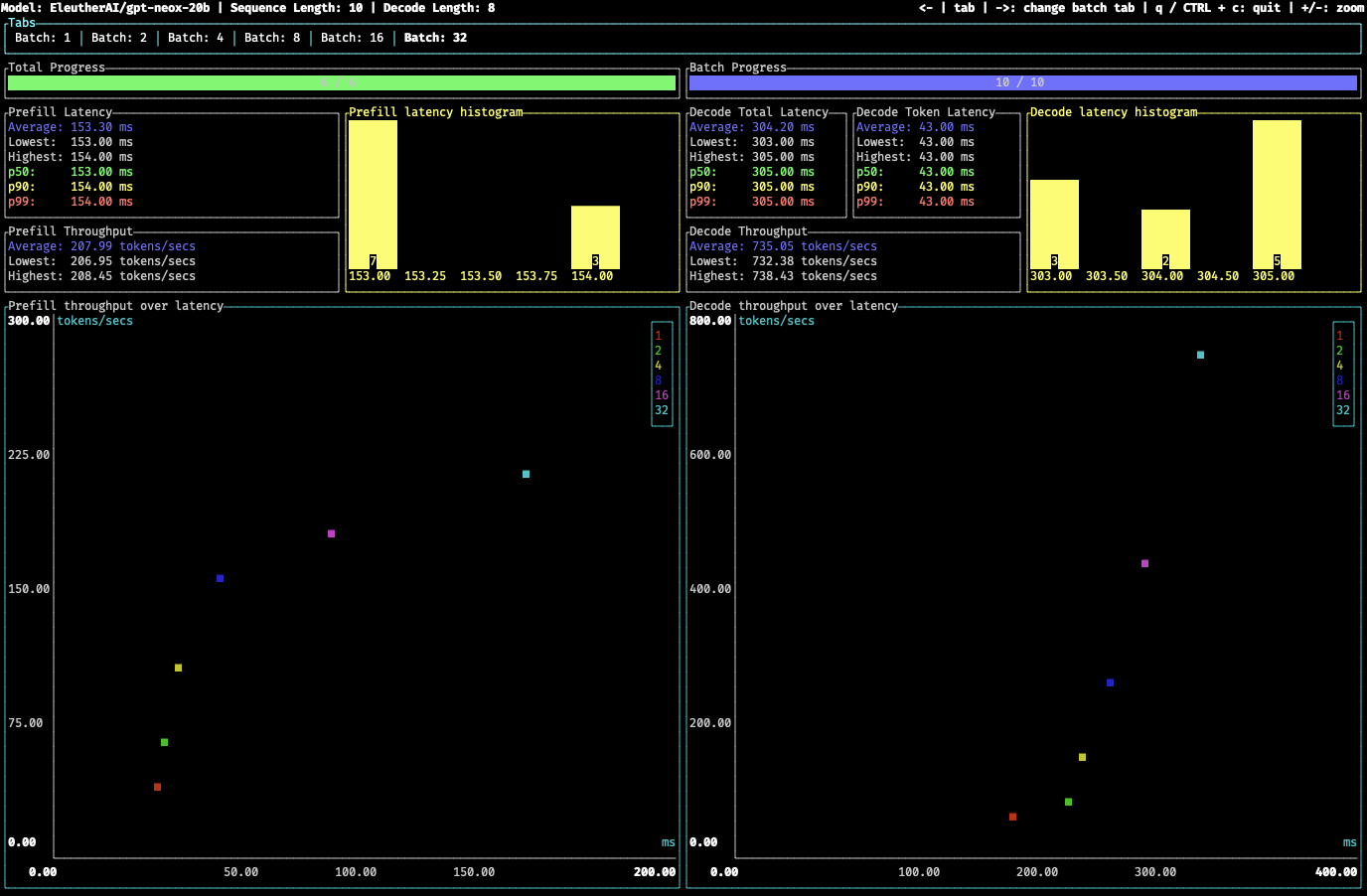
101 KB
assets/tgi_grafana.json
0 → 100644
This diff is collapsed.
benchmark/Cargo.toml
0 → 100644
benchmark/README.md
0 → 100644
benchmark/src/app.rs
0 → 100644
This diff is collapsed.
benchmark/src/event.rs
0 → 100644