"superbench/common/vscode:/vscode.git/clone" did not exist on "91b44bc5a170ae6715dc02ed84a8b9bb8022f562"

Docs - Add design document (#125)
**Description** Add Executor and Benchmarks design doc **Major Revision** - Add Executor design doc - Add Benchmarks design doc
Showing
{kind=link}
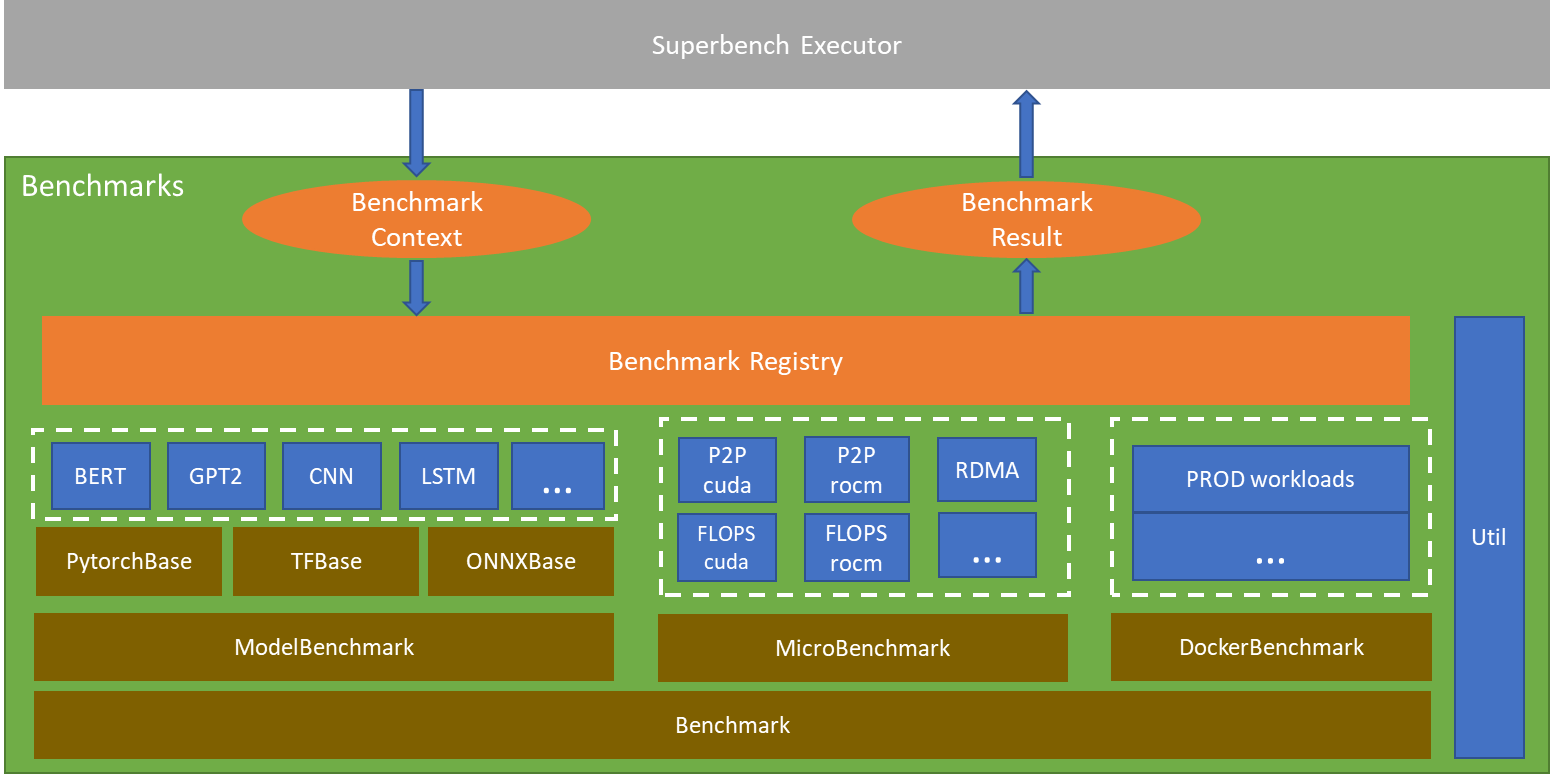
48 KB
{kind=link}
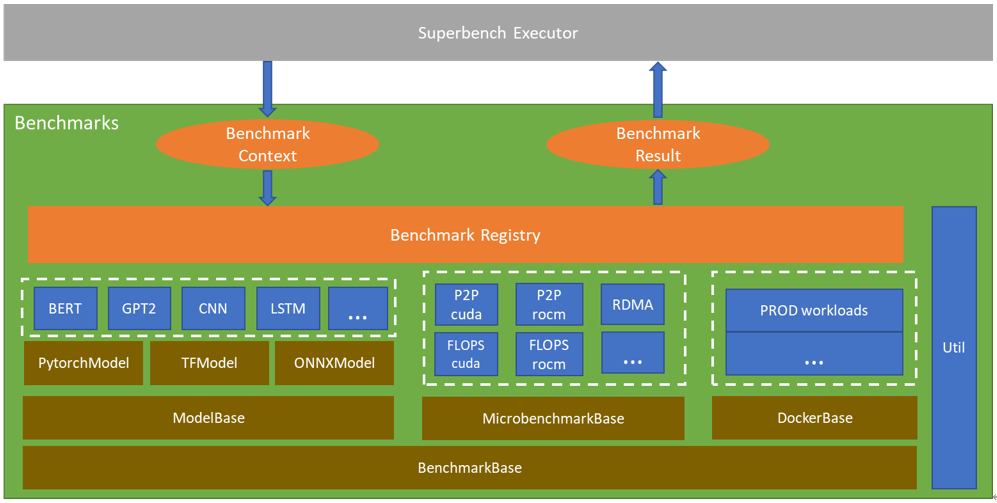
83.9 KB
{kind=link}
This diff is collapsed.
{kind=link}
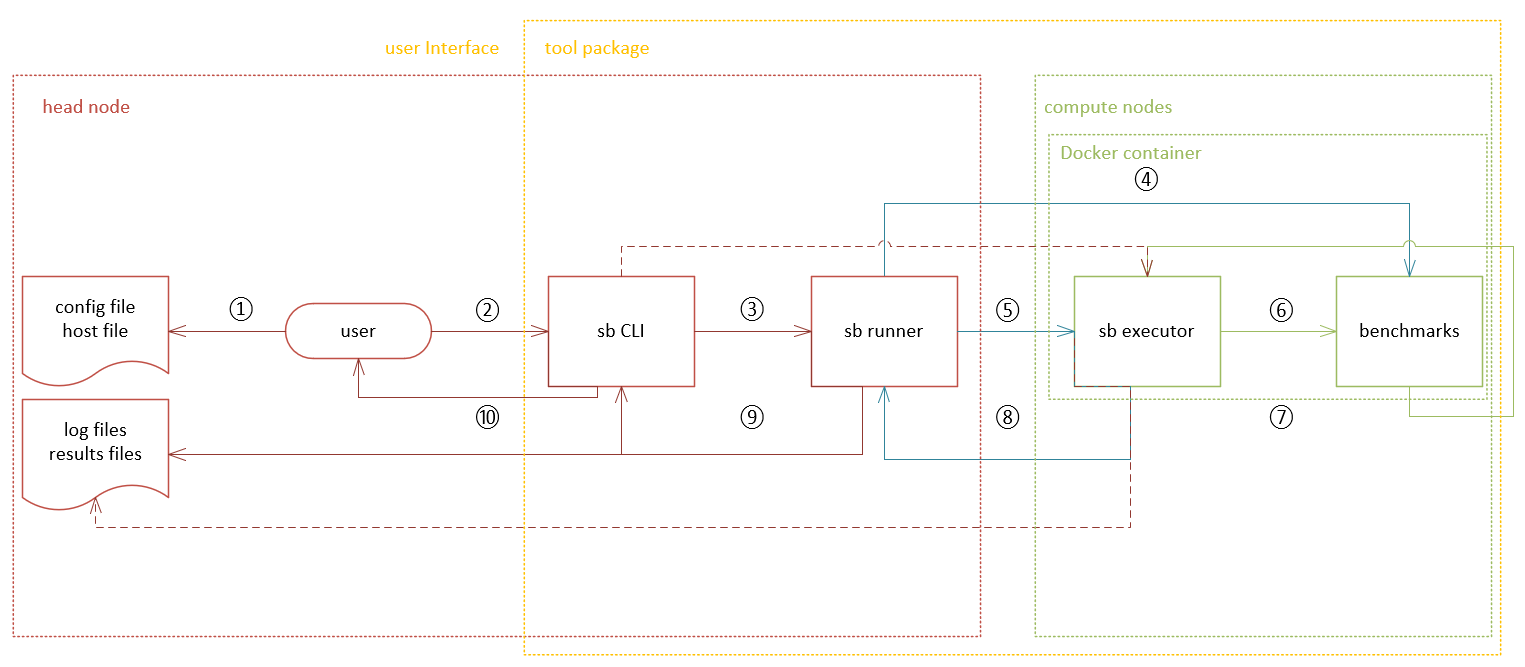
67.4 KB
{kind=link}
{kind=link}
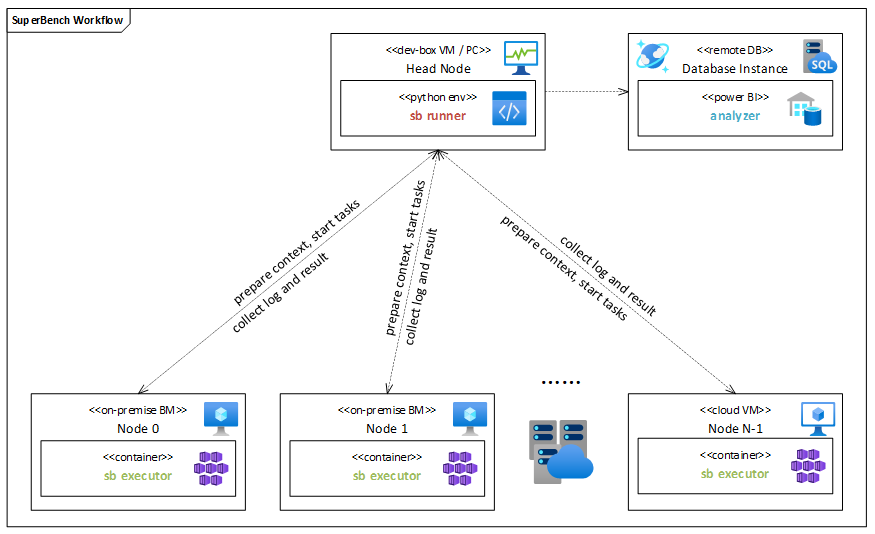
| W: | H:
| W: | H:
{kind=link}
This diff is collapsed.
{kind=link}
This diff is collapsed.
{kind=link}
This diff is collapsed.
{kind=link}
This diff is collapsed.
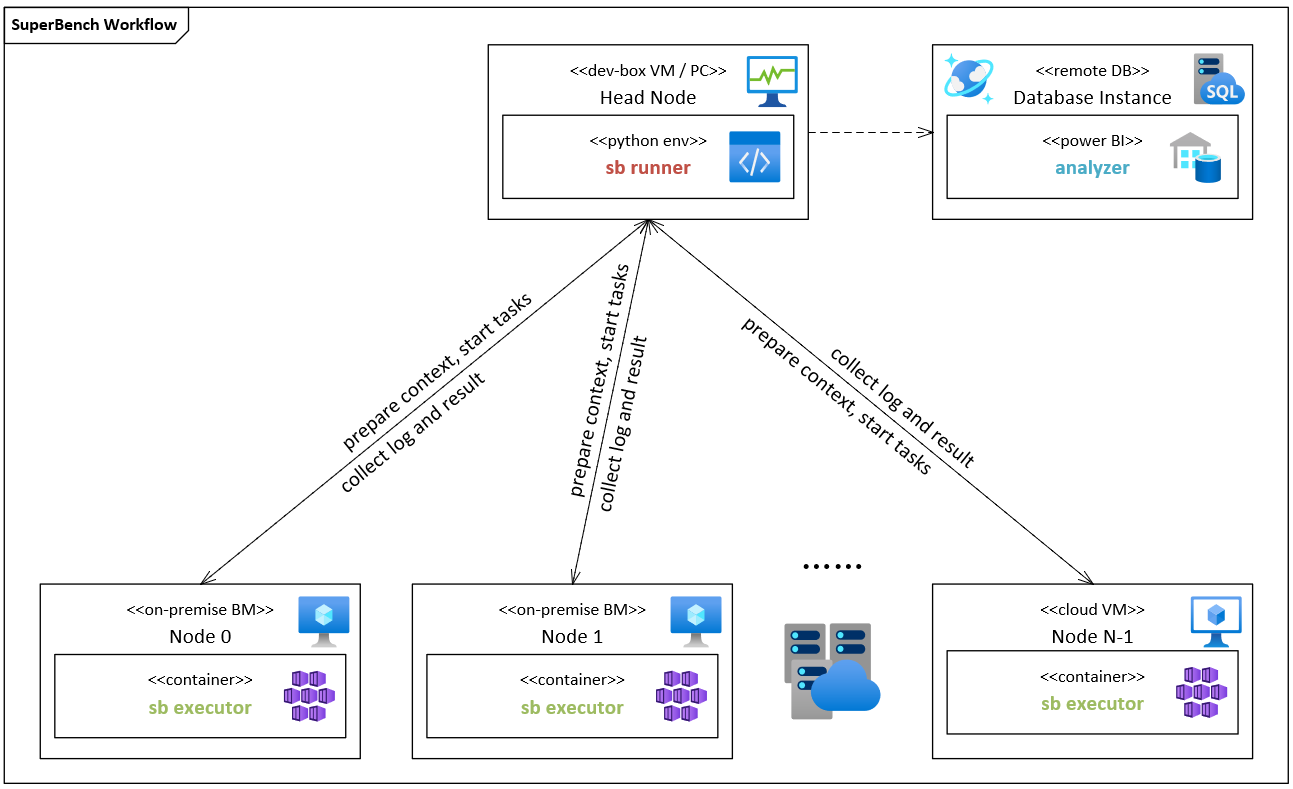
docs/design-docs/overview.md
0 → 100644