
added DeepSeek OCR API by liushengtong
Showing
File added
File added
File added
File added
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
File added
{kind=link}
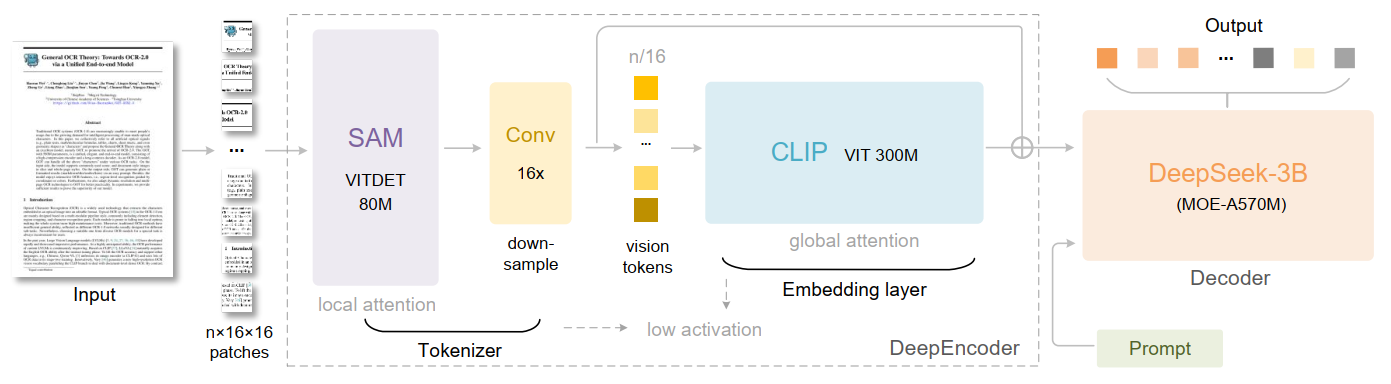
124 KB
{kind=link}
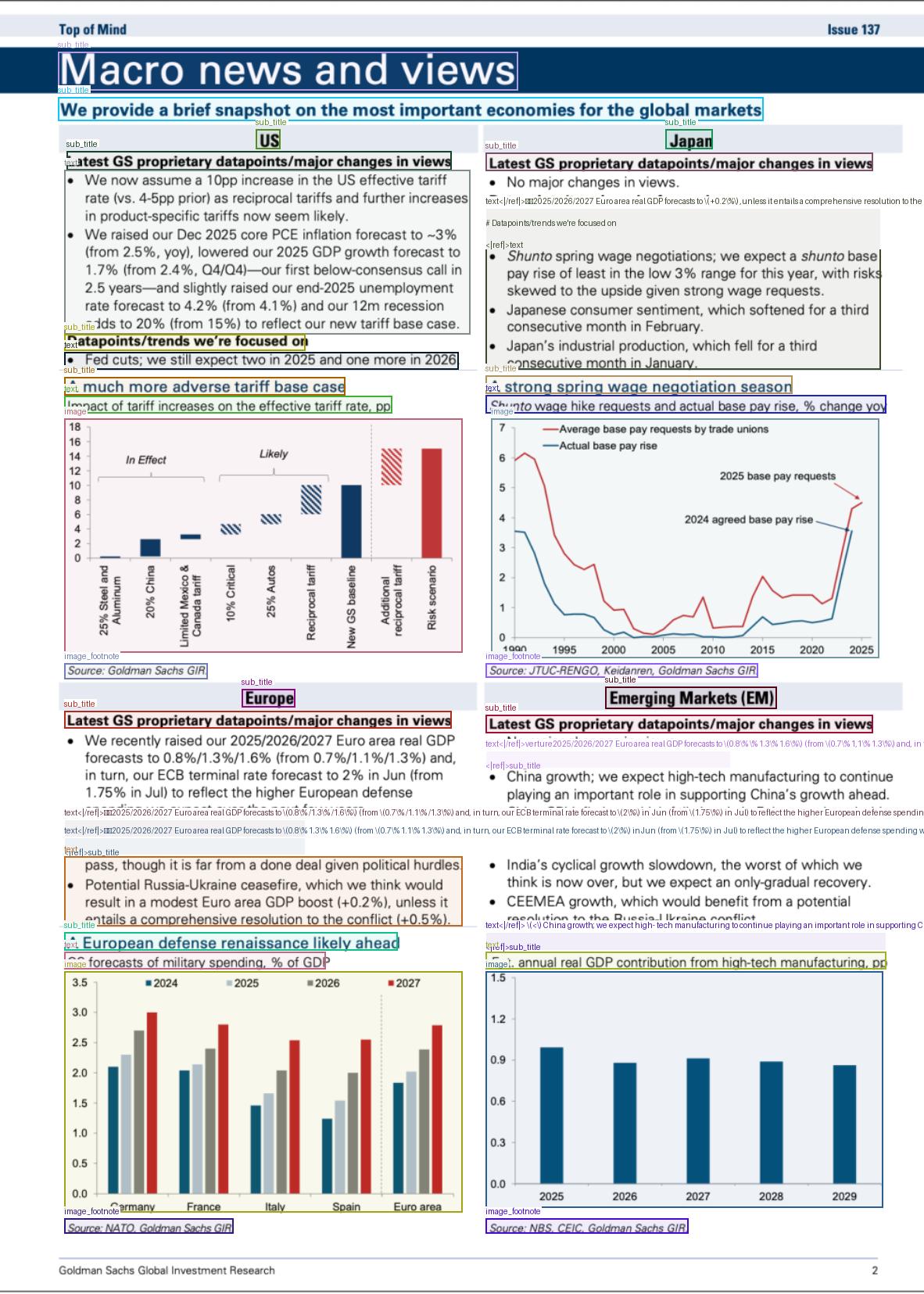
318 KB
{kind=link}

317 KB
{kind=link}
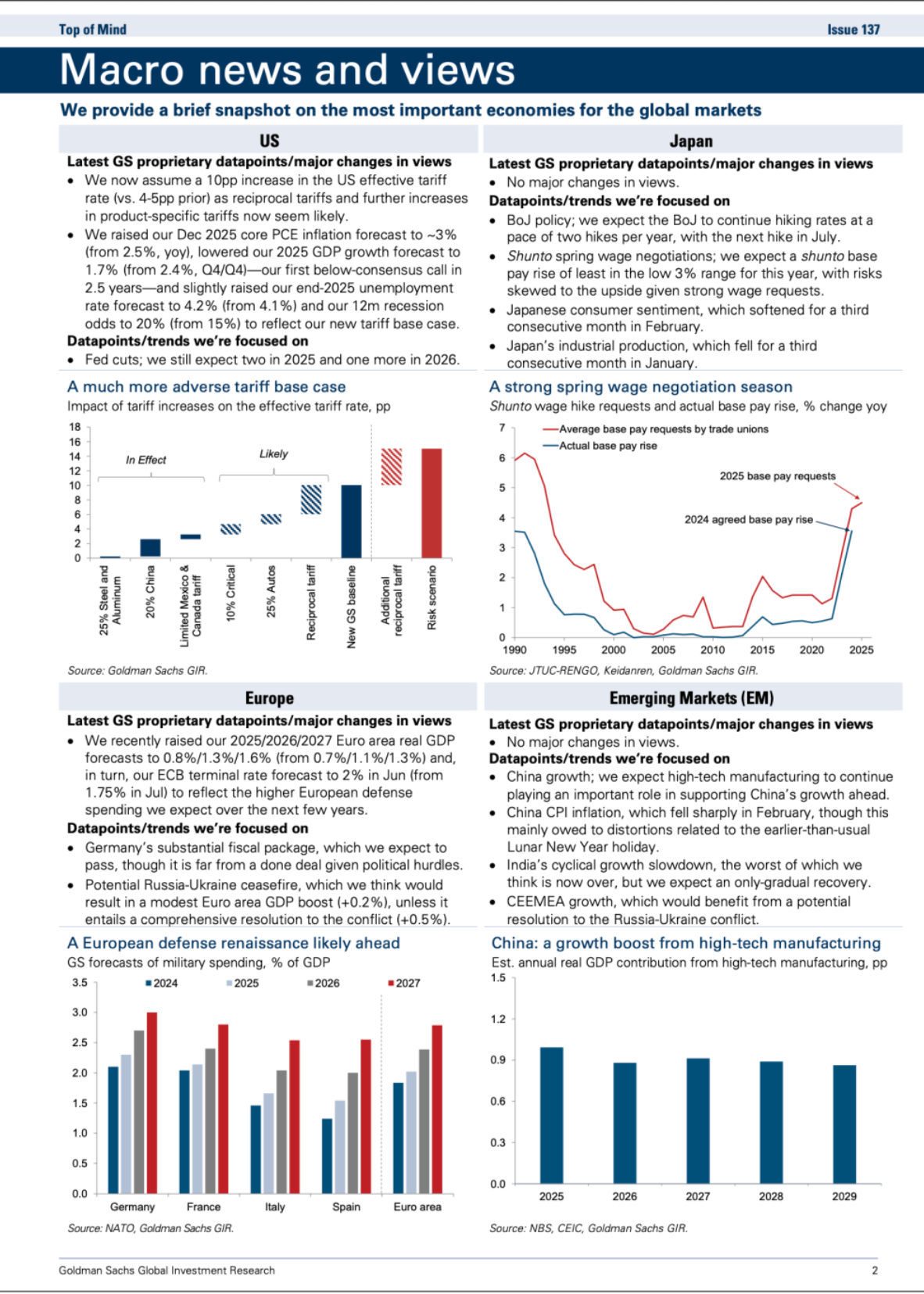
929 KB
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.