"vscode:/vscode.git/clone" did not exist on "faf97b39b32e3b03dc0d2de6a3be8946df98bd34"

added DeepSeek OCR API by liushengtong
Showing
DeepSeek-OCR-vllm/.env
0 → 100644
File added
File added
DeepSeek-OCR-vllm/config.py
0 → 100644
File added
File added
File added
File added
This diff is collapsed.
This diff is collapsed.
File added
{kind=link}
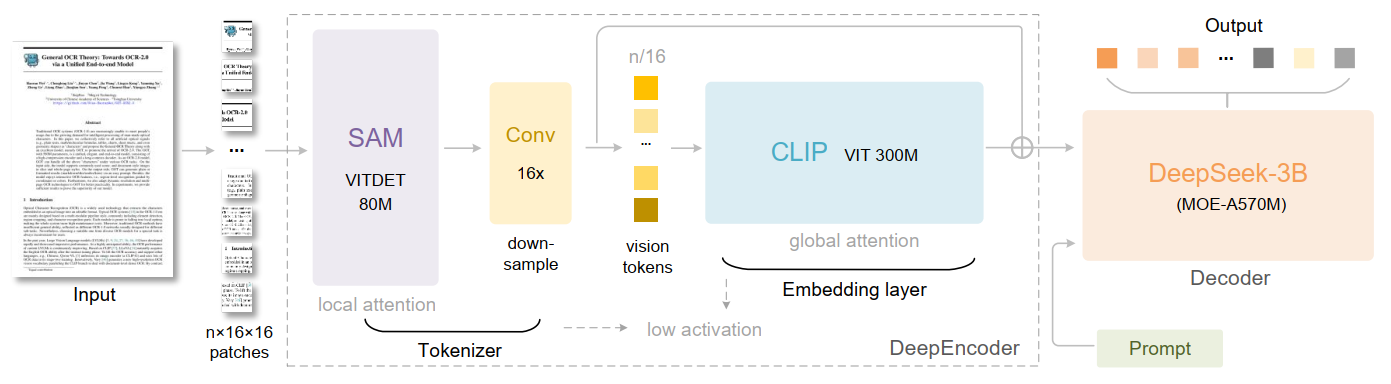
124 KB
{kind=link}
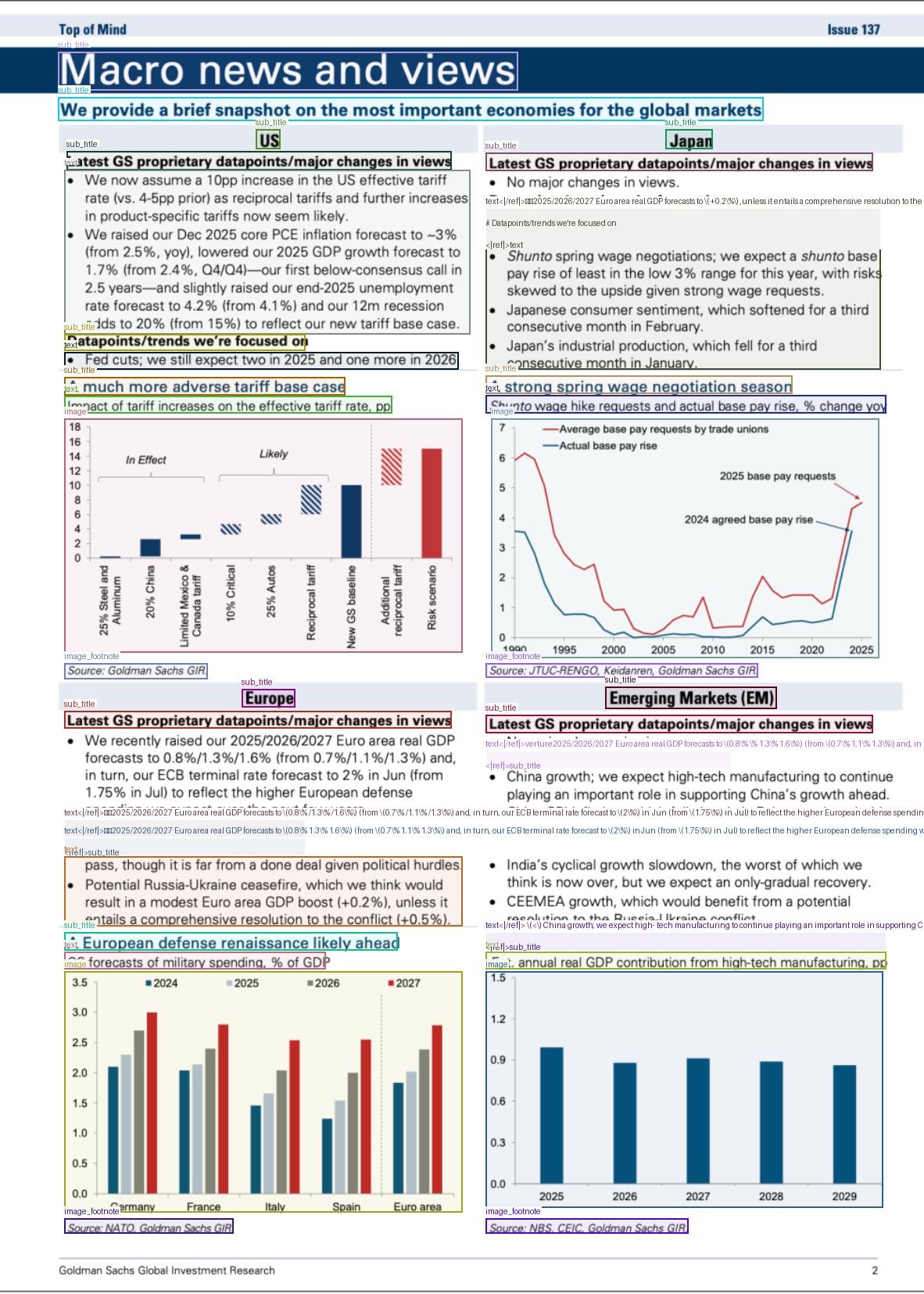
318 KB
{kind=link}

317 KB