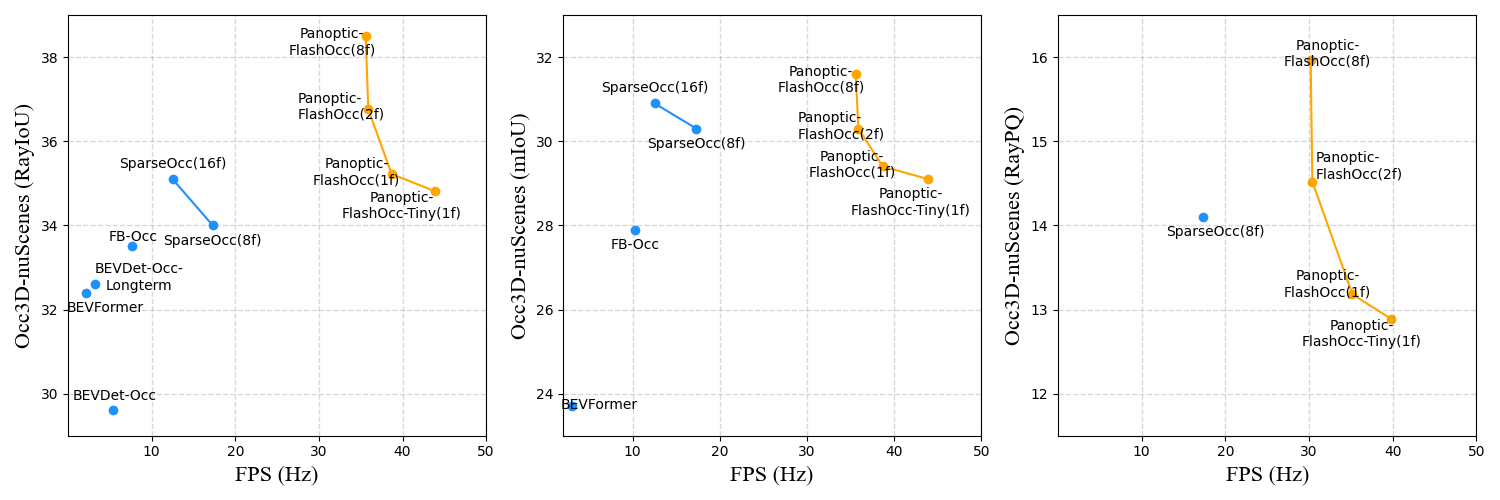
* Please note that the FPS here is measured with RTX3090 TensorRT FP16.
# Panoptic-FlashOcc: An Efficient Baseline to Marry Semantic Occupancy with Panoptic via Instance Center
<divalign="left">
<imgsrc="figs/performance.png"width="1500px"/>
</div><br/>
* Please note that the FPS here is measured with A100 GPU (PyTorch fp32 backend).
## News
-**2024.09.16** Technical Report: FlashOcc can be insert to Bevdet with 1.1ms consumption while facilitating each other.[](https://arxiv.org/abs/2409.11160)
-**2024.09.16**[Selected as reference algorithm for occupancy on horizon J6E/M](https://zhuanlan.zhihu.com/p/720461546)
-**2024.06.10** Release the code for Panoptic-FlashOCC
-**2024.04.17** Support for ray-iou metric
-**2024.03.22** Release the code for FlashOCCV2
-**2024.02.03**[Release the training code for FlashOcc on UniOcc](https://github.com/drilistbox/FlashOCC_on_UniOcc_and_RenderOCC)
-**2024.01.20**[TensorRT Implement Writen In C++ With Cuda Acceleration](https://github.com/drilistbox/TRT_FlashOcc)
-**2023.12.23** Release the quick testing code via TensorRT in MMDeploy.
-**2023.11.28** Release the training code for FlashOCC.
FPS are tested via TensorRT on 3090 with FP16 precision. Please refer to Tab.2 in paper for the detail model settings for M-number.
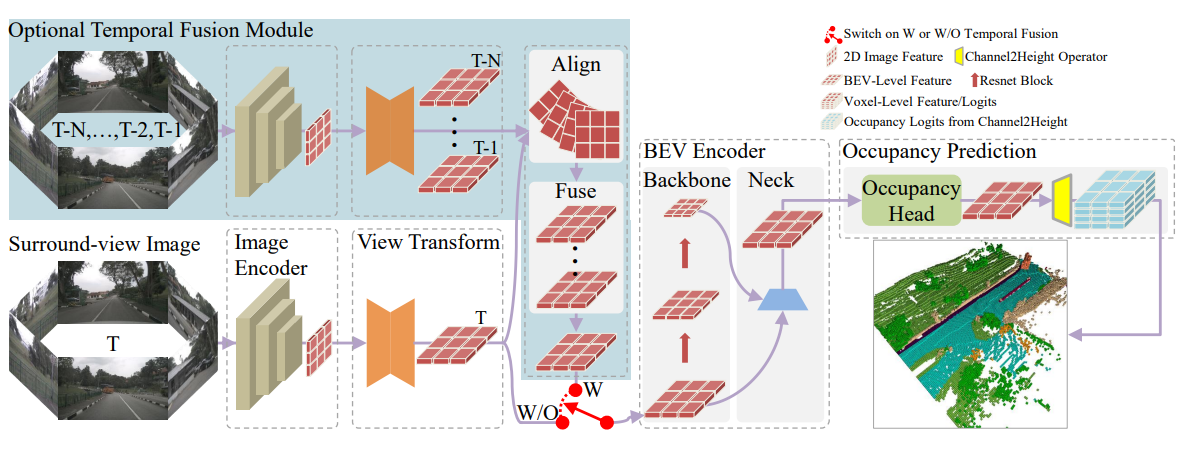
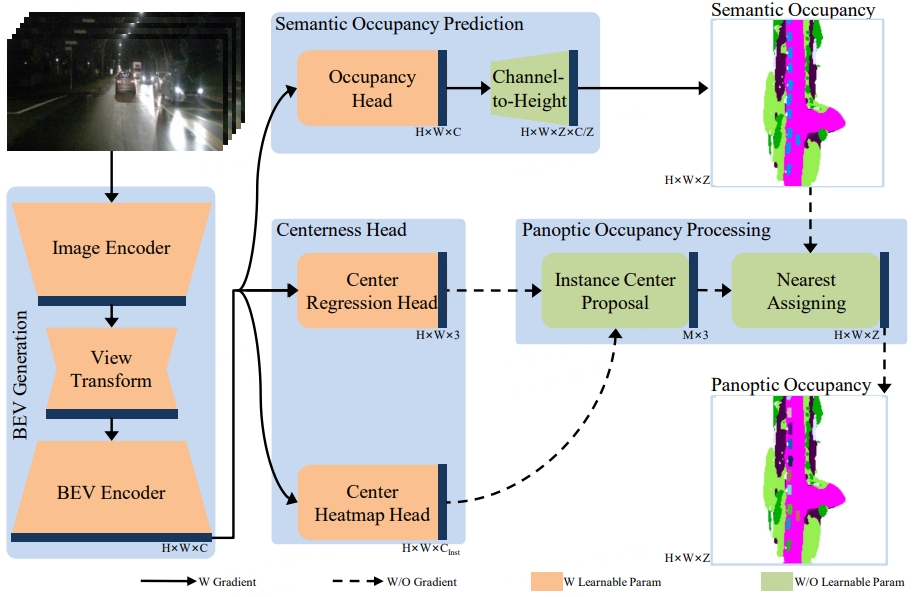
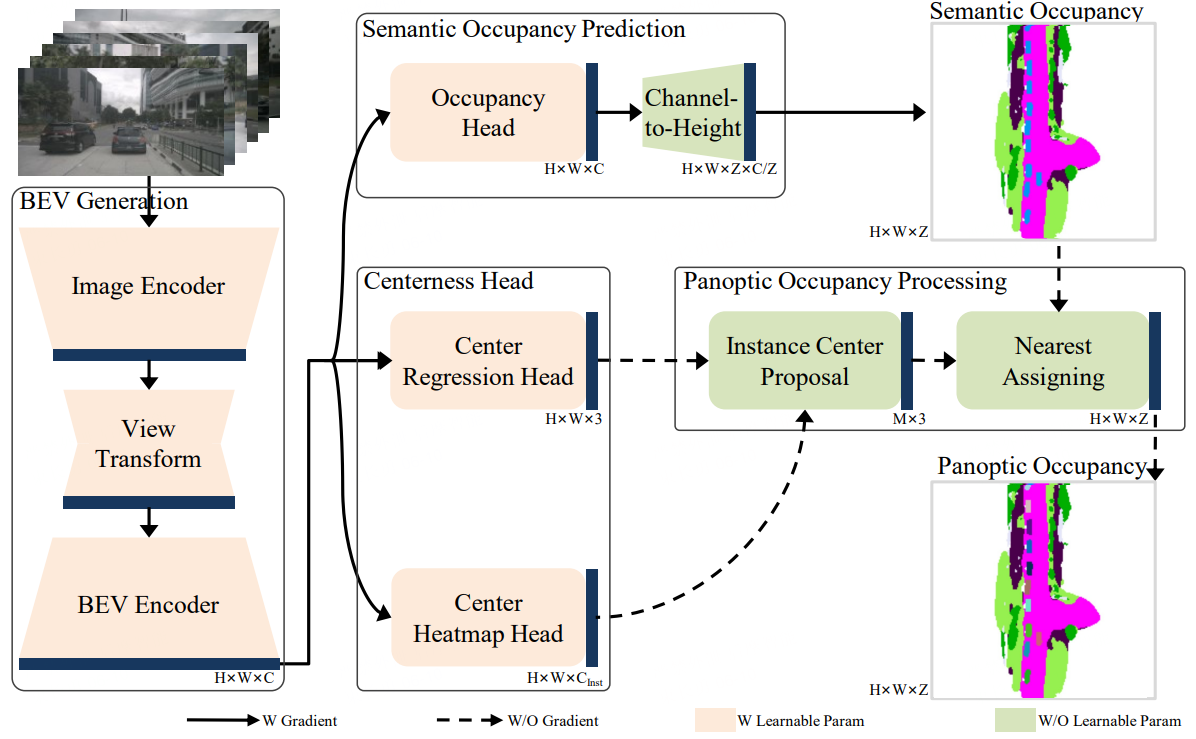
### 2. Panoptic-FlashOCC
**In Panoptic-FlashOCC, we have made the following 3 adjustments to FlashOCC**:
- Without using camera mask for training. This is because its use significantly improves the prediction performance in the visible region, but at the expense of prediction in the invisible region.
- Using category balancing.
- Using stronger loss settings.
- Introducing instance center for panoptic occupancy
**More results for different configurations will be released soon.**
* Please note that the FPS here is measured with A100 GPU (PyTorch fp32 backend).
## Get Started
1.[Environment Setup](doc/install.md)
2.[Model Training](doc/model_training.md)
3.[Quick Test Via TensorRT In MMDeploy](doc/mmdeploy_test.md)
| Backend | mIOU | FPS(Hz) |
|----------|-------|---------|
| PyTorch-FP32 | 31.95 | - |
| TRT-FP32 | 30.78 | 96.2 |
| TRT-FP16 | 30.78 | 197.6 |
| TRT-FP16+INT8(PTQ) | 29.60 | 383.7 |
| TRT-INT8(PTQ) | 29.59 | 397.0 |
4.[Visualization](doc/visualization.md)
*[flashocc] : A detail video can be found at [baidu](https://pan.baidu.com/s/1xfnFsj5IclpjJxIaOlI6dA?pwd=gype)
<divalign="center">
<imgsrc="figs/visualization.png"/>
</div><br/>
* [panoptic-flashocc] : first row is our prediction and second row is gt.
<divalign="center">
<imgsrc="figs/sem.png"/>
</div><br/>
<divalign="center">
<imgsrc="figs/pano.png"/>
</div><br/>
5.[TensorRT Implement Writen In C++ With Cuda Acceleration](https://github.com/drilistbox/TRT_FlashOcc)
## Acknowledgement
Many thanks to the authors of [BEVDet](https://github.com/HuangJunJie2017/BEVDet), [FB-BEV](https://github.com/NVlabs/FB-BEV.git),
[RenderOcc](https://github.com/pmj110119/RenderOcc.git) and [SparseBEV](https://github.com/MCG-NJU/SparseBEV.git)
## Bibtex
If this work is helpful for your research, please consider citing the following BibTeX entry.
```
@article{yu2024ultimatedo,
title={UltimateDO: An Efficient Framework to Marry Occupancy Prediction with 3D Object Detection via Channel2height},
author={Yu, Zichen and Shu, Changyong},
journal={arXiv preprint arXiv:2409.11160},
year={2024}
}
@article{yu2024panoptic,
title={Panoptic-FlashOcc: An Efficient Baseline to Marry Semantic Occupancy with Panoptic via Instance Center},
author={Yu, Zichen and Shu, Changyong and Sun, Qianpu and Linghu, Junjie and Wei, Xiaobao and Yu, Jiangyong and Liu, Zongdai and Yang, Dawei and Li, Hui and Chen, Yan},
journal={arXiv preprint arXiv:2406.10527},
year={2024}
}
@article{yu2023flashocc,
title={FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin},
author={Zichen Yu and Changyong Shu and Jiajun Deng and Kangjie Lu and Zongdai Liu and Jiangyong Yu and Dawei Yang and Hui Li and Yan Chen},
step 3. Prepare nuScenes dataset as introduced in [nuscenes_det.md](nuscenes_det.md) and create the pkl for FlashOCC by running:
```shell
python tools/create_data_bevdet.py
```
thus, the folder will be ranged as following:
```shell script
└── Path_to_FlashOcc/
└── data
└── nuscenes
├── v1.0-trainval (existing)
├── sweeps (existing)
├── samples (existing)
├── bevdetv2-nuscenes_infos_train.pkl (new)
└── bevdetv2-nuscenes_infos_val.pkl (new)
```
step 4. For Occupancy Prediction task, download (only) the 'gts' from [CVPR2023-3D-Occupancy-Prediction](https://github.com/CVPR2023-3D-Occupancy-Prediction/CVPR2023-3D-Occupancy-Prediction) and arrange the folder as:
```shell script
└── Path_to_FlashOcc/
└── data
└── nuscenes
├── v1.0-trainval (existing)
├── sweeps (existing)
├── samples (existing)
├── gts (new)
├── bevdetv2-nuscenes_infos_train.pkl (new)
└── bevdetv2-nuscenes_infos_val.pkl (new)
```
(for panoptic occupancy), we follow the data setting in SparseOcc:
(1) Download Occ3D-nuScenes occupancy GT from [gdrive](https://drive.google.com/file/d/1kiXVNSEi3UrNERPMz_CfiJXKkgts_5dY/view?usp=drive_link), unzip it, and save it to `data/nuscenes/occ3d`.
(2) Generate the panoptic occupancy ground truth with `gen_instance_info.py`. The panoptic version of Occ3D will be saved to `data/nuscenes/occ3d_panoptic`.
step 5. CKPTS Preparation
(1) Download flashocc-r50-256x704.pth[https://drive.google.com/file/d/1k9BzXB2nRyvXhqf7GQx3XNSej6Oq6I-B/view] to Path_to_FlashOcc/FlashOcc/ckpts/, then run:
This page provides specific tutorials about the usage of MMDetection3D for nuScenes dataset.
## Before Preparation
You can download nuScenes 3D detection data [HERE](https://www.nuscenes.org/download) and unzip all zip files.
Like the general way to prepare dataset, it is recommended to symlink the dataset root to `$MMDETECTION3D/data`.
The folder structure should be organized as follows before our processing.
```
mmdetection3d
├── mmdet3d
├── tools
├── configs
├── data
│ ├── nuscenes
│ │ ├── maps
│ │ ├── samples
│ │ ├── sweeps
│ │ ├── v1.0-test
| | ├── v1.0-trainval
```
## Dataset Preparation
We typically need to organize the useful data information with a .pkl or .json file in a specific style, e.g., coco-style for organizing images and their annotations.
To prepare these files for nuScenes, run the following command:
The folder structure after processing should be as below.
```
mmdetection3d
├── mmdet3d
├── tools
├── configs
├── data
│ ├── nuscenes
│ │ ├── maps
│ │ ├── samples
│ │ ├── sweeps
│ │ ├── v1.0-test
| | ├── v1.0-trainval
│ │ ├── nuscenes_database
│ │ ├── nuscenes_infos_train.pkl
│ │ ├── nuscenes_infos_val.pkl
│ │ ├── nuscenes_infos_test.pkl
│ │ ├── nuscenes_dbinfos_train.pkl
│ │ ├── nuscenes_infos_train_mono3d.coco.json
│ │ ├── nuscenes_infos_val_mono3d.coco.json
│ │ ├── nuscenes_infos_test_mono3d.coco.json
```
Here, .pkl files are generally used for methods involving point clouds and coco-style .json files are more suitable for image-based methods, such as image-based 2D and 3D detection.
Next, we will elaborate on the details recorded in these info files.
-`nuscenes_database/xxxxx.bin`: point cloud data included in each 3D bounding box of the training dataset
-`nuscenes_infos_train.pkl`: training dataset info, each frame info has two keys: `metadata` and `infos`.
`metadata` contains the basic information for the dataset itself, such as `{'version': 'v1.0-trainval'}`, while `infos` contains the detailed information as follows:
- info\['lidar_path'\]: The file path of the lidar point cloud data.
- info\['token'\]: Sample data token.
- info\['sweeps'\]: Sweeps information (`sweeps` in the nuScenes refer to the intermediate frames without annotations, while `samples` refer to those key frames with annotations).
- info\['sweeps'\]\[i\]\['data_path'\]: The data path of i-th sweep.
- info\['sweeps'\]\[i\]\['type'\]: The sweep data type, e.g., `'lidar'`.
- info\['sweeps'\]\[i\]\['sample_data_token'\]: The sweep sample data token.
- info\['sweeps'\]\[i\]\['sensor2ego_translation'\]: The translation from the current sensor (for collecting the sweep data) to ego vehicle. (1x3 list)
- info\['sweeps'\]\[i\]\['sensor2ego_rotation'\]: The rotation from the current sensor (for collecting the sweep data) to ego vehicle. (1x4 list in the quaternion format)
- info\['sweeps'\]\[i\]\['ego2global_translation'\]: The translation from the ego vehicle to global coordinates. (1x3 list)
- info\['sweeps'\]\[i\]\['ego2global_rotation'\]: The rotation from the ego vehicle to global coordinates. (1x4 list in the quaternion format)
- info\['sweeps'\]\[i\]\['timestamp'\]: Timestamp of the sweep data.
- info\['sweeps'\]\[i\]\['sensor2lidar_translation'\]: The translation from the current sensor (for collecting the sweep data) to lidar. (1x3 list)
- info\['sweeps'\]\[i\]\['sensor2lidar_rotation'\]: The rotation from the current sensor (for collecting the sweep data) to lidar. (1x4 list in the quaternion format)
- info\['cams'\]: Cameras calibration information. It contains six keys corresponding to each camera: `'CAM_FRONT'`, `'CAM_FRONT_RIGHT'`, `'CAM_FRONT_LEFT'`, `'CAM_BACK'`, `'CAM_BACK_LEFT'`, `'CAM_BACK_RIGHT'`.
Each dictionary contains detailed information following the above way for each sweep data (has the same keys for each information as above). In addition, each camera has a key `'cam_intrinsic'` for recording the intrinsic parameters when projecting 3D points to each image plane.
- info\['lidar2ego_translation'\]: The translation from lidar to ego vehicle. (1x3 list)
- info\['lidar2ego_rotation'\]: The rotation from lidar to ego vehicle. (1x4 list in the quaternion format)
- info\['ego2global_translation'\]: The translation from the ego vehicle to global coordinates. (1x3 list)
- info\['ego2global_rotation'\]: The rotation from the ego vehicle to global coordinates. (1x4 list in the quaternion format)
- info\['timestamp'\]: Timestamp of the sample data.
- info\['gt_boxes'\]: 7-DoF annotations of 3D bounding boxes, an Nx7 array.
- info\['gt_names'\]: Categories of 3D bounding boxes, an 1xN array.
- info\['gt_velocity'\]: Velocities of 3D bounding boxes (no vertical measurements due to inaccuracy), an Nx2 array.
- info\['num_lidar_pts'\]: Number of lidar points included in each 3D bounding box.
- info\['num_radar_pts'\]: Number of radar points included in each 3D bounding box.
- info\['valid_flag'\]: Whether each bounding box is valid. In general, we only take the 3D boxes that include at least one lidar or radar point as valid boxes.
-`nuscenes_infos_train_mono3d.coco.json`: training dataset coco-style info. This file organizes image-based data into three categories (keys): `'categories'`, `'images'`, `'annotations'`.
- info\['categories'\]: A list containing all the category names. Each element follows the dictionary format and consists of two keys: `'id'` and `'name'`.
- info\['images'\]: A list containing all the image info.
- info\['images'\]\[i\]\['file_name'\]: The file name of the i-th image.
- info\['images'\]\[i\]\['id'\]: Sample data token of the i-th image.
- info\['images'\]\[i\]\['token'\]: Sample token corresponding to this frame.
- info\['images'\]\[i\]\['cam2ego_rotation'\]: The rotation from the camera to ego vehicle. (1x4 list in the quaternion format)
- info\['images'\]\[i\]\['cam2ego_translation'\]: The translation from the camera to ego vehicle. (1x3 list)
- info\['images'\]\[i\]\['ego2global_rotation''\]: The rotation from the ego vehicle to global coordinates. (1x4 list in the quaternion format)
- info\['images'\]\[i\]\['ego2global_translation'\]: The translation from the ego vehicle to global coordinates. (1x3 list)
- info\['images'\]\[i\]\['cam_intrinsic'\]: Camera intrinsic matrix. (3x3 list)
- info\['images'\]\[i\]\['width'\]: Image width, 1600 by default in nuScenes.
- info\['images'\]\[i\]\['height'\]: Image height, 900 by default in nuScenes.
- info\['annotations'\]: A list containing all the annotation info.
- info\['annotations'\]\[i\]\['file_name'\]: The file name of the corresponding image.
- info\['annotations'\]\[i\]\['image_id'\]: The image id (token) of the corresponding image.
- info\['annotations'\]\[i\]\['area'\]: Area of the 2D bounding box.
- info\['annotations'\]\[i\]\['bbox'\]: 2D bounding box annotation (exterior rectangle of the projected 3D box), 1x4 list following \[x1, y1, x2-x1, y2-y1\].
x1/y1 are minimum coordinates along horizontal/vertical direction of the image.
- info\['annotations'\]\[i\]\['iscrowd'\]: Whether the region is crowded. Defaults to 0.
- info\['annotations'\]\[i\]\['bbox_cam3d'\]: 3D bounding box (gravity) center location (3), size (3), (global) yaw angle (1), 1x7 list.
- info\['annotations'\]\[i\]\['velo_cam3d'\]: Velocities of 3D bounding boxes (no vertical measurements due to inaccuracy), an Nx2 array.
- info\['annotations'\]\[i\]\['center2d'\]: Projected 3D-center containing 2.5D information: projected center location on the image (2) and depth (1), 1x3 list.
We maintain a default attribute collection and mapping for attribute classification.
Please refer to [here](https://github.com/open-mmlab/mmdetection3d/blob/master/mmdet3d/datasets/nuscenes_mono_dataset.py#L53) for more details.
- info\['annotations'\]\[i\]\['id'\]: Annotation id. Defaults to `i`.
Here we only explain the data recorded in the training info files. The same applies to validation and testing set.
The core function to get `nuscenes_infos_xxx.pkl` and `nuscenes_infos_xxx_mono3d.coco.json` are [\_fill_trainval_infos](https://github.com/open-mmlab/mmdetection3d/blob/master/tools/data_converter/nuscenes_converter.py#L143) and [get_2d_boxes](https://github.com/open-mmlab/mmdetection3d/blob/master/tools/data_converter/nuscenes_converter.py#L397), respectively.
Please refer to [nuscenes_converter.py](https://github.com/open-mmlab/mmdetection3d/blob/master/tools/data_converter/nuscenes_converter.py) for more details.
## Training pipeline
### LiDAR-Based Methods
A typical training pipeline of LiDAR-based 3D detection (including multi-modality methods) on nuScenes is as below.
Compared to general cases, nuScenes has a specific `'LoadPointsFromMultiSweeps'` pipeline to load point clouds from consecutive frames. This is a common practice used in this setting.
Please refer to the nuScenes [original paper](https://arxiv.org/abs/1903.11027) for more details.
The default `use_dim` in `'LoadPointsFromMultiSweeps'` is `[0, 1, 2, 4]`, where the first 3 dimensions refer to point coordinates and the last refers to timestamp differences.
Intensity is not used by default due to its yielded noise when concatenating the points from different frames.
### Vision-Based Methods
A typical training pipeline of image-based 3D detection on nuScenes is as below.
NuScenes proposes a comprehensive metric, namely nuScenes detection score (NDS), to evaluate different methods and set up the benchmark.
It consists of mean Average Precision (mAP), Average Translation Error (ATE), Average Scale Error (ASE), Average Orientation Error (AOE), Average Velocity Error (AVE) and Average Attribute Error (AAE).
Please refer to its [official website](https://www.nuscenes.org/object-detection?externalData=all&mapData=all&modalities=Any) for more details.
We also adopt this approach for evaluation on nuScenes. An example of printed evaluation results is as follows:
Note that the testing info should be changed to that for testing set instead of validation set [here](https://github.com/open-mmlab/mmdetection3d/blob/master/configs/_base_/datasets/nus-3d.py#L132).
After generating the `work_dirs/pp-nus/results_eval.json`, you can compress it and submit it to nuScenes benchmark. Please refer to the [nuScenes official website](https://www.nuscenes.org/object-detection?externalData=all&mapData=all&modalities=Any) for more information.
We can also visualize the prediction results with our developed visualization tools. Please refer to the [visualization doc](https://mmdetection3d.readthedocs.io/en/latest/useful_tools.html#visualization) for more details.
## Notes
### Transformation between `NuScenesBox` and our `CameraInstanceBoxes`.
In general, the main difference of `NuScenesBox` and our `CameraInstanceBoxes` is mainly reflected in the yaw definition. `NuScenesBox` defines the rotation with a quaternion or three Euler angles while ours only defines one yaw angle due to the practical scenario. It requires us to add some additional rotations manually in the pre-processing and post-processing, such as [here](https://github.com/open-mmlab/mmdetection3d/blob/master/mmdet3d/datasets/nuscenes_mono_dataset.py#L673).
In addition, please note that the definition of corners and locations are detached in the `NuScenesBox`. For example, in monocular 3D detection, the definition of the box location is in its camera coordinate (see its official [illustration](https://www.nuscenes.org/nuscenes#data-collection) for car setup), which is consistent with [ours](https://github.com/open-mmlab/mmdetection3d/blob/master/mmdet3d/core/bbox/structures/cam_box3d.py). In contrast, its corners are defined with the [convention](https://github.com/nutonomy/nuscenes-devkit/blob/02e9200218977193a1058dd7234f935834378319/python-sdk/nuscenes/utils/data_classes.py#L527) "x points forward, y to the left, z up". It results in different philosophy of dimension and rotation definitions from our `CameraInstanceBoxes`. An example to remove similar hacks is PR [#744](https://github.com/open-mmlab/mmdetection3d/pull/744). The same problem also exists in the LiDAR system. To deal with them, we typically add some transformation in the pre-processing and post-processing to guarantee the box will be in our coordinate system during the entire training and inference procedure.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

{kind=link}