***`Aug. 31th, 2023`:** initial MapTRv2 is released at ***maptrv2*** branch. Please run `git checkout maptrv2` to use it.
***`Aug. 14th, 2023`:** As required by many researchers, the code of MapTR-based map annotation framework (VMA) will be released at https://github.com/hustvl/VMA recently.
***`Aug. 10th, 2023`:** We release [MapTRv2](https://arxiv.org/abs/2308.05736) on Arxiv. MapTRv2 demonstrates much stronger performance and much faster convergence. To better meet the requirement of the downstream planner (like [PDM](https://github.com/autonomousvision/nuplan_garage)), we introduce an extra semantic——centerline (using path-wise modeling proposed by [LaneGAP](https://github.com/hustvl/LaneGAP)). Code & model will be released in late August. Please stay tuned!
***`May. 12th, 2023`:** MapTR now support various bevencoder, such as [BEVFormer encoder](projects/configs/maptr/maptr_tiny_r50_24e_bevformer.py) and [BEVFusion bevpool](projects\configs\maptr\maptr_tiny_r50_24e_bevpool.py). Check it out!
***`Apr. 20th, 2023`:** Extending MapTR to a general map annotation framework ([paper](https://arxiv.org/pdf/2304.09807.pdf), [code](https://github.com/hustvl/VMA)), with high flexibility in terms of spatial scale and element type.
***`Mar. 22nd, 2023`:** By leveraging MapTR, VAD ([paper](https://arxiv.org/abs/2303.12077), [code](https://github.com/hustvl/VAD)) models the driving scene as fully vectorized representation, achieving SoTA end-to-end planning performance!
***`Jan. 21st, 2023`:** MapTR is accepted to ICLR 2023 as **Spotlight Presentation**!
***`Nov. 11st, 2022`:** We release an initial version of MapTR.
***`Aug. 31st, 2022`:** We released our paper on Arxiv. Code/Models are coming soon. Please stay tuned! ☕️
## Introduction
<divalign="center"><h4>MapTR/MapTRv2 is a simple, fast and strong online vectorized HD map construction framework.</h4></div>

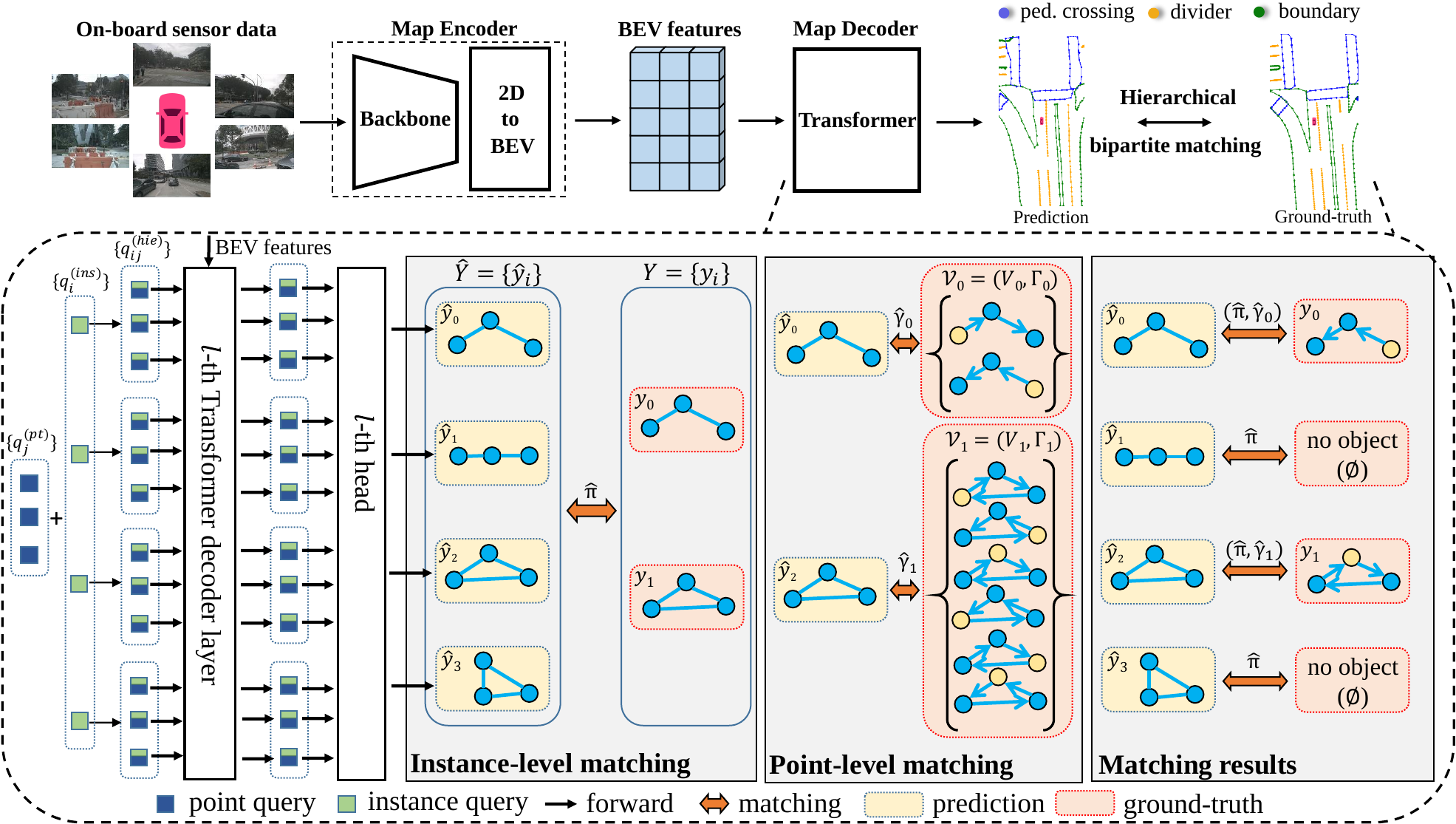
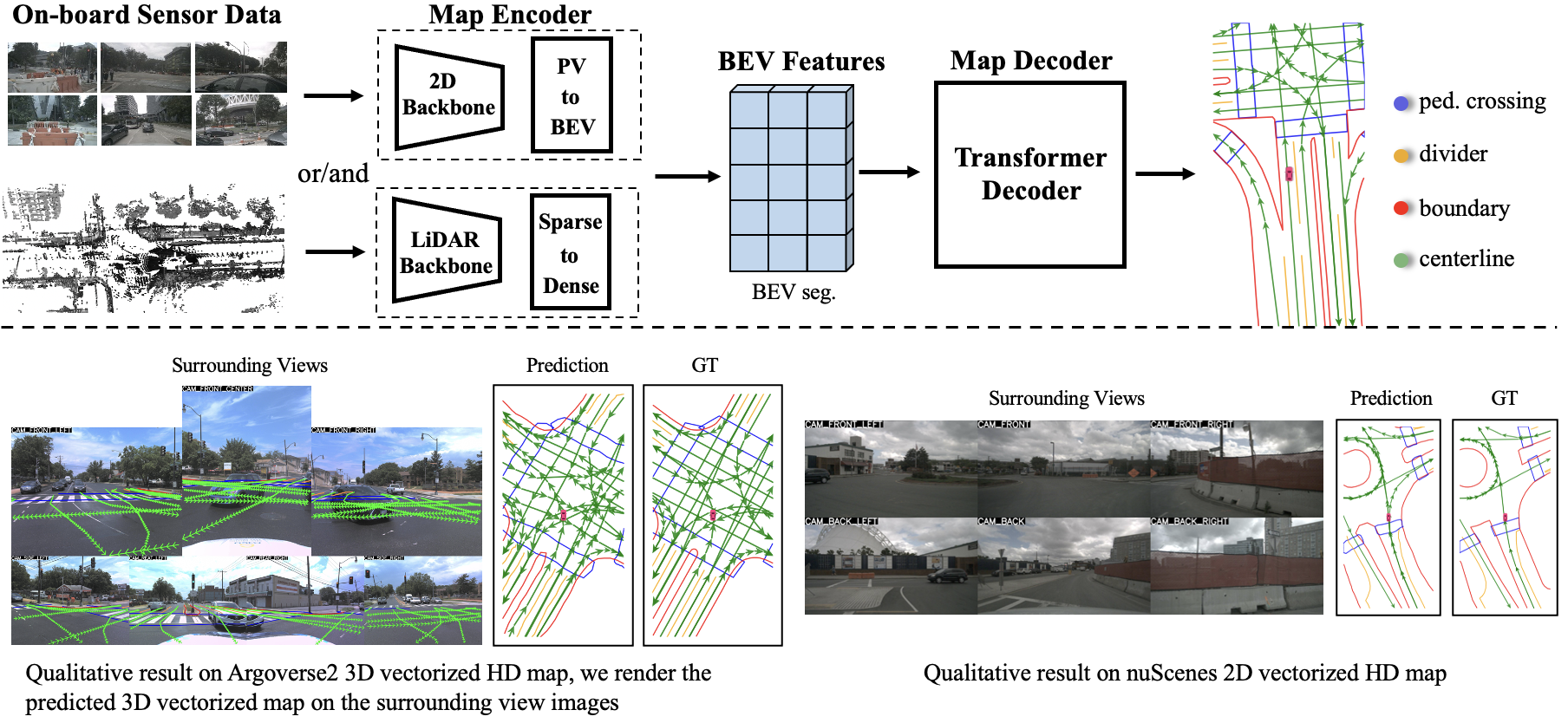
High-definition (HD) map provides abundant and precise static environmental information of the driving scene, serving as a fundamental and indispensable component for planning in autonomous driving system. In this paper, we present **Map****TR**ansformer, an end-to-end framework for online vectorized HD map construction. We propose a unified permutation-equivalent modeling approach, i.e., modeling map element as a point set with a group of equivalent permutations, which accurately describes the shape of map element and stabilizes the learning process. We design a hierarchical query embedding scheme to flexibly encode structured map information and perform hierarchical bipartite matching for map element learning. To speed up convergence, we further introduce auxiliary one-to-many matching and dense supervision. The proposed method well copes with various map elements with arbitrary shapes. It runs at real-time inference speed and achieves state-of-the-art performance on both nuScenes and Argoverse2 datasets. Abundant qualitative results show stable and robust map construction quality in complex and various driving scenes.
## Models
> Results from the [MapTRv2 paper](https://arxiv.org/abs/2308.05736)
![comparison]()
| Method | Backbone | Lr Schd | mAP| FPS|
| :---: | :---: | :---: | :---: | :---:
| MapTR | R18 | 110ep | 45.9 | 35.0|
| MapTR | R50 | 24ep | 50.3 | 15.1|
| MapTR | R50 | 110ep | 58.7|15.1|
| MapTRv2 | R18 | 110ep | 52.3 | 33.7|
| MapTRv2 | R50 | 24ep | 61.5 | 14.1|
| MapTRv2 | R50 | 110ep | 68.7 | 14.1|
| MapTRv2 | V2-99 | 110ep | 73.4 | 9.9|
**Notes**:
- FPS is measured on NVIDIA RTX3090 GPU with batch size of 1 (containing 6 view images).
- All the experiments are performed on 8 NVIDIA GeForce RTX 3090 GPUs.
-[Prepare Dataset](docs/prepare_dataset.md)(Notes: annotation generation of MapTRv2 is different from MapTR )
-[Train and Eval](docs/train_eval.md)
-[Visualization](docs/visualization.md)
## Catalog
- [ ] centerline detection & topology support
- [x] multi-modal checkpoints
- [x] multi-modal code
- [ ] lidar modality code
- [x] argoverse2 dataset
- [x] Nuscenes dataset
- [x] MapTR checkpoints
- [x] MapTR code
- [x] Initialization
## Acknowledgements
MapTR is based on [mmdetection3d](https://github.com/open-mmlab/mmdetection3d). It is also greatly inspired by the following outstanding contributions to the open-source community: [BEVFusion](https://github.com/mit-han-lab/bevfusion), [BEVFormer](https://github.com/fundamentalvision/BEVFormer), [HDMapNet](https://github.com/Tsinghua-MARS-Lab/HDMapNet), [GKT](https://github.com/hustvl/GKT), [VectorMapNet](https://github.com/Mrmoore98/VectorMapNet_code).
## Citation
If you find MapTR is useful in your research or applications, please consider giving us a star 🌟 and citing it by the following BibTeX entry.
```bibtex
@inproceedings{MapTR,
title={MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction},
author={Liao, Bencheng and Chen, Shaoyu and Wang, Xinggang and Cheng, Tianheng, and Zhang, Qian and Liu, Wenyu and Huang, Chang},
booktitle={International Conference on Learning Representations},
year={2023}
}
```
```bibtex
@inproceedings{MapTRv2,
title={MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construction},
author={Liao, Bencheng and Chen, Shaoyu and Zhang, Yunchi and Jiang, Bo and Zhang, Qian and Liu, Wenyu and Huang, Chang and Wang, Xinggang},
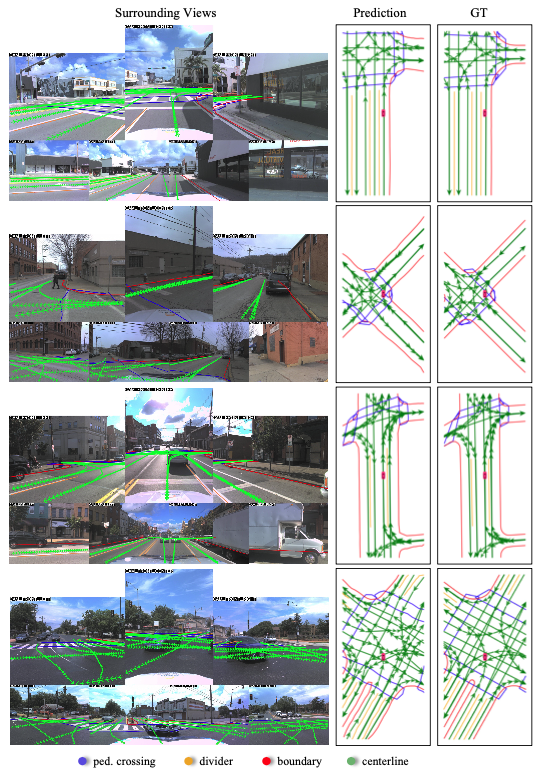
- All the visualization samples will be saved in `/path/to/MapTR/work_dirs/experiment/vis_pred/` automatically. If you want to customize the saving path, you can add `--show-dir /customized_path`.
- The score threshold is set to 0.3 by default. For better visualization, you can adjust the threshold by adding `--score-thresh customized_thresh`
- The GT is visualized in fixed_num_pts format by default, we provide multiple formats to visualize GT at the same time by setting `--gt-format`: `se_pts` means the start and end points of GT, `bbox` means the bounding box envelops the GT, `polyline_pts` means the original annotated GT (you can use Douglas-Peucker algorithm to simplify the redundant annotated points).
## Merge them into video
We also provide the script to merge the input, output and GT into video to benchmark the performance qualitatively.

{kind=link}
{kind=link}
{kind=link}

{kind=link}
{kind=link}

{kind=link}

{kind=link}
