
update conformer
Showing
Too many changes to show.
To preserve performance only 1000 of 1000+ files are displayed.
This diff is collapsed.
{kind=link}
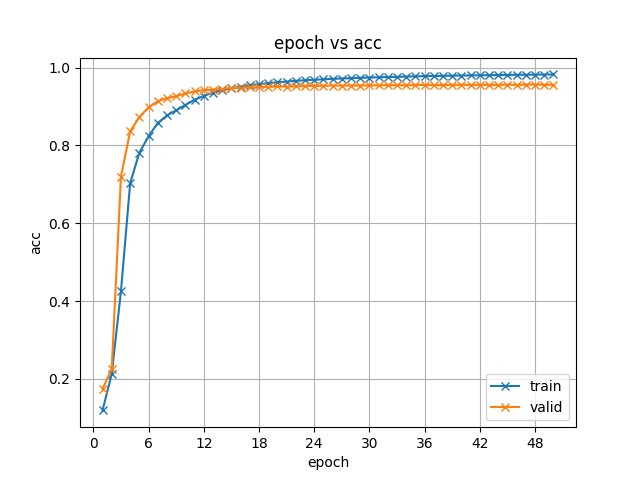
28.6 KB
{kind=link}
46.8 KB
{kind=link}
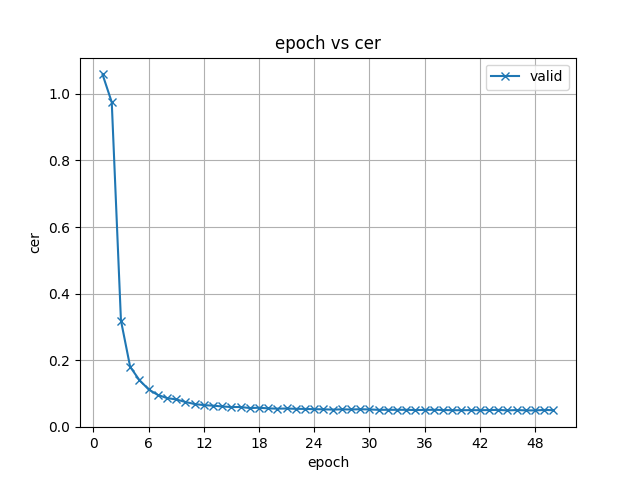
22.2 KB
{kind=link}
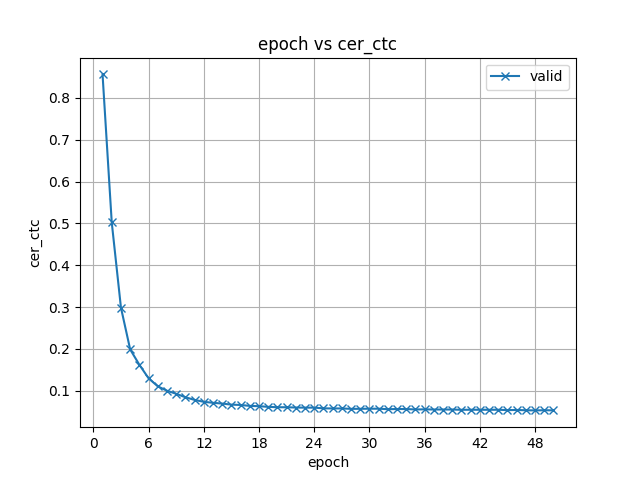
24.8 KB
{kind=link}
46.3 KB
{kind=link}
36.4 KB
{kind=link}
28.7 KB
{kind=link}
29.7 KB
{kind=link}
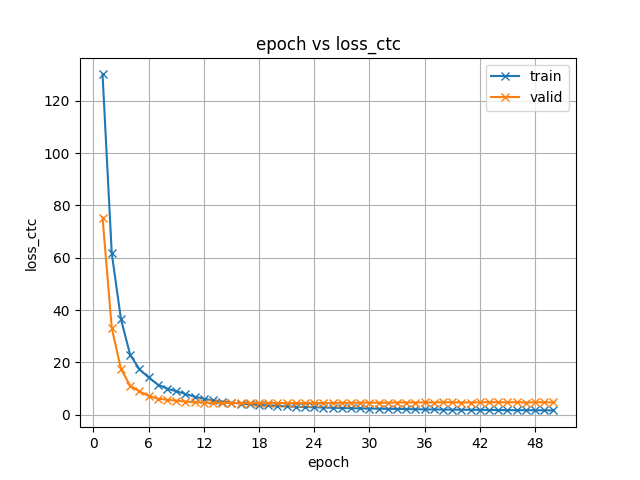
30.6 KB
{kind=link}
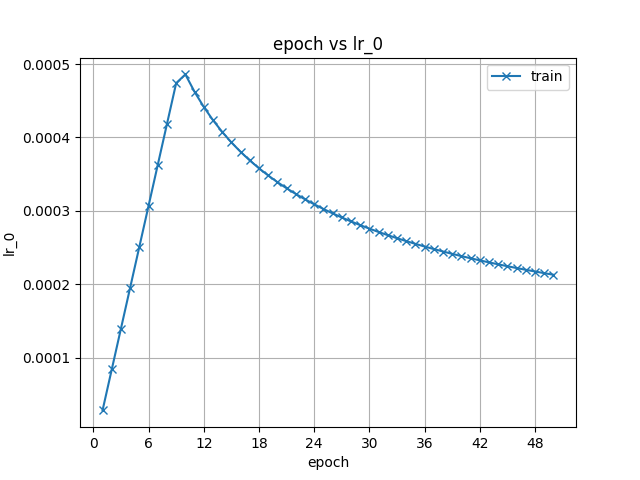
28.4 KB
{kind=link}
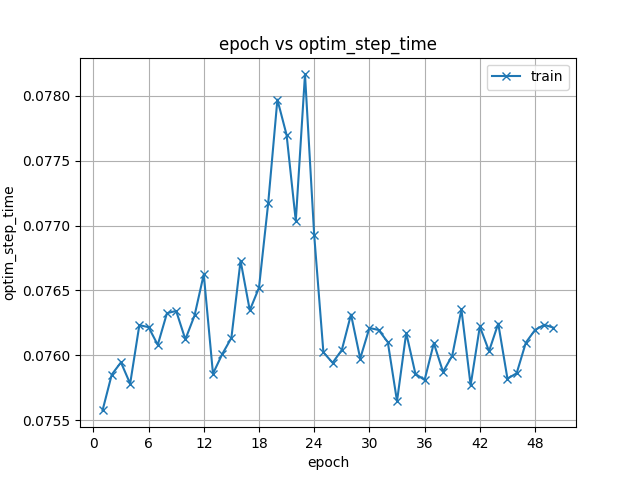
43.3 KB
{kind=link}
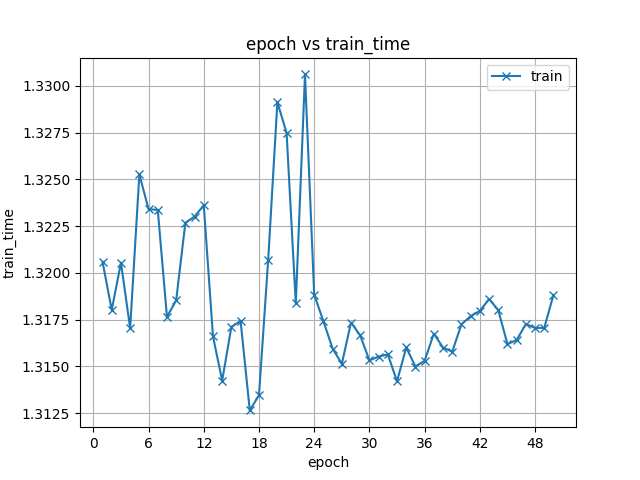
44.1 KB
{kind=link}
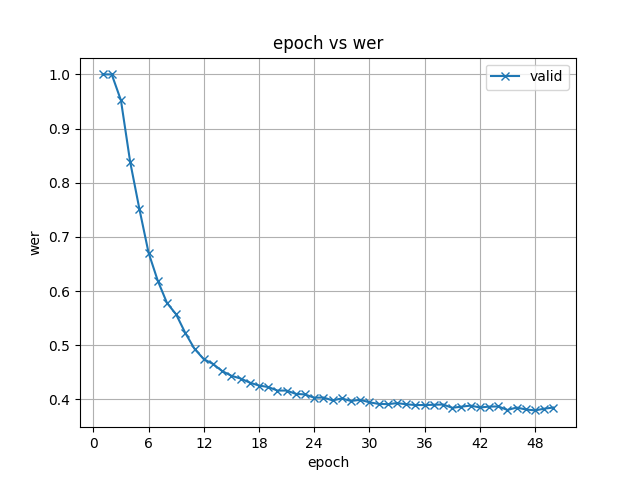
25.8 KB