vLLM is a fast and easy-to-use library for LLM inference and serving.
pip install-r requirements.txt
pip install-e.# This may take several minutes.
```
## Test simple server
## Latest News 🔥
```bash
-[2023/06] We officially released vLLM! vLLM has powered [LMSYS Vicuna and Chatbot Arena](https://chat.lmsys.org) since mid April. Check out our [blog post]().
The detailed arguments for `simple_server.py` can be found by:
Visit our [documentation](https://llm-serving-cacheflow.readthedocs-hosted.com/_/sharing/Cyo52MQgyoAWRQ79XA4iA2k8euwzzmjY?next=/en/latest/) to get started.
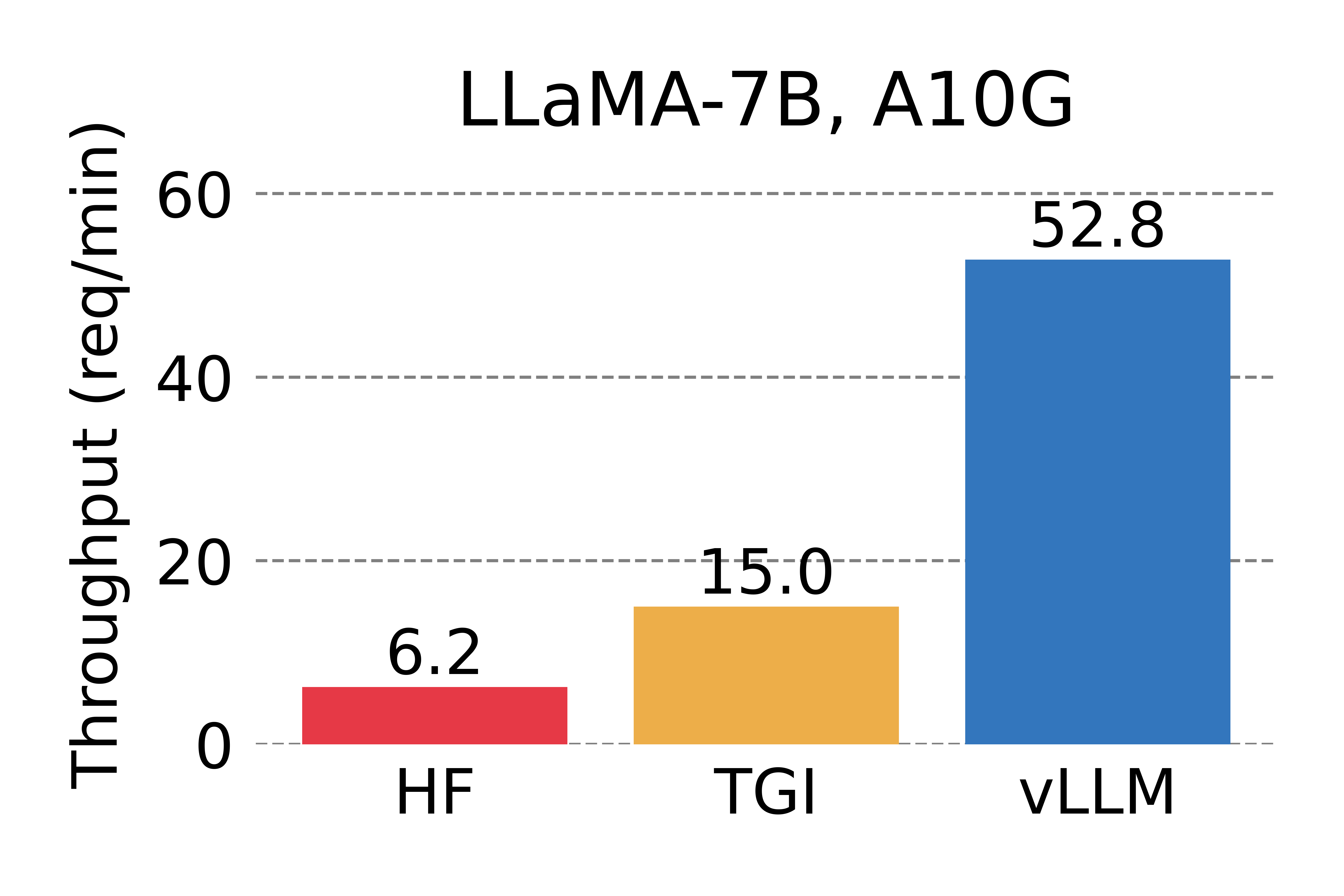
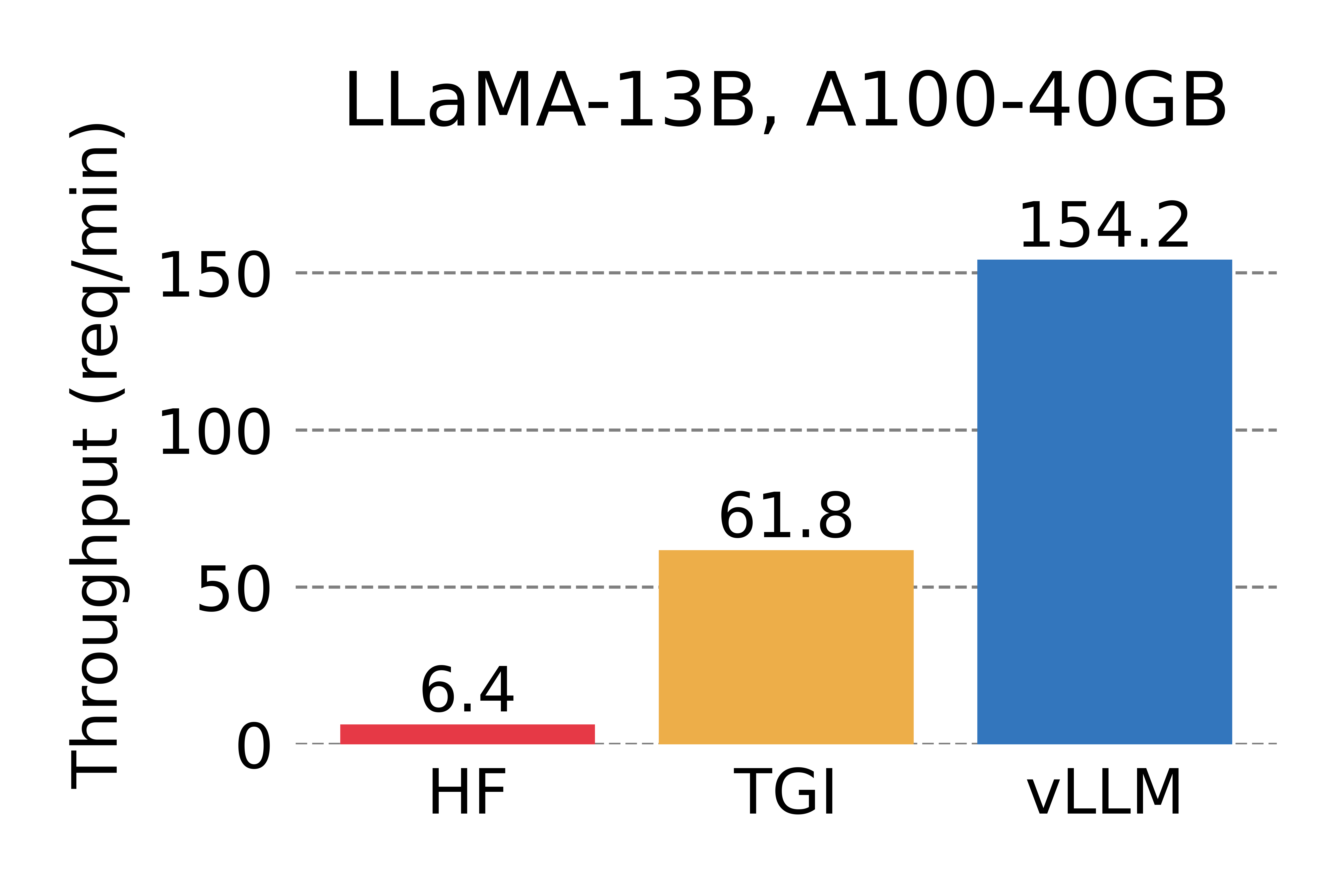
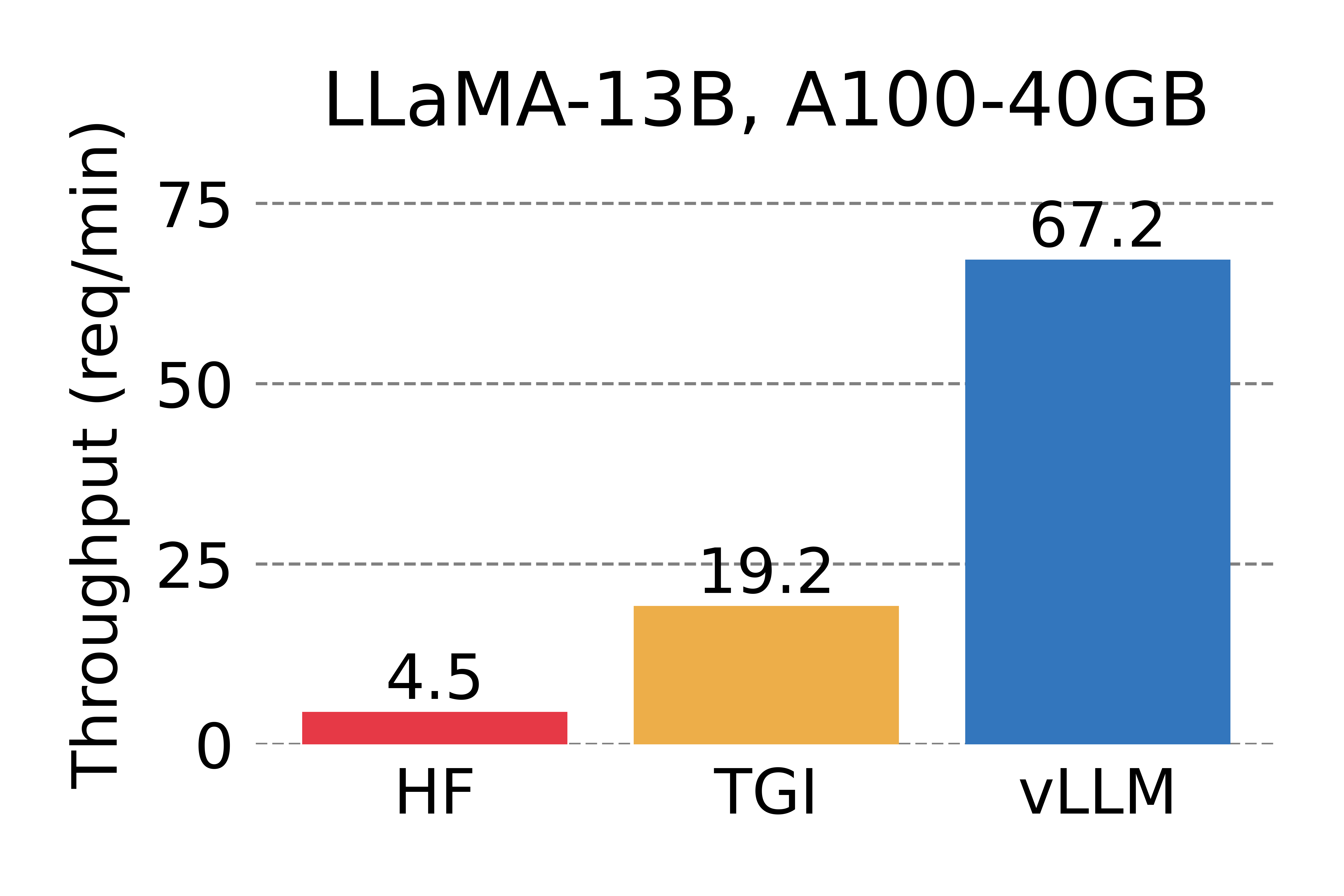
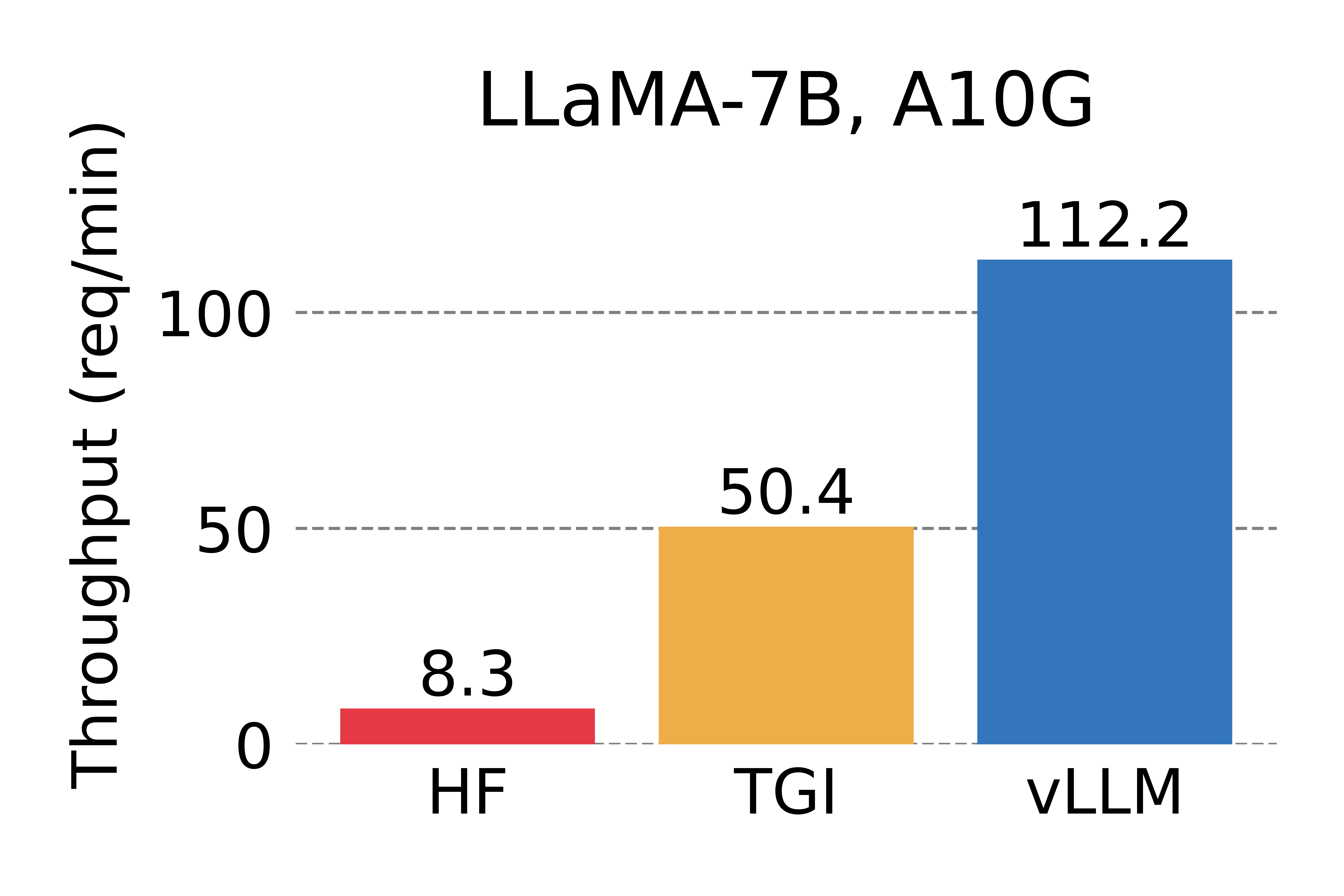
<em> Serving throughput when each request asks for 3 output completions. </em>
</p>
Since LLaMA weight is not fully public, we cannot directly download the LLaMA weights from huggingface. Therefore, you need to follow the following process to load the LLaMA weights.
## Contributing
1. Converting LLaMA weights to huggingface format with [this script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py).
We welcome and value any contributions and collaborations.
```bash
Please check out [CONTRIBUTING.md](./CONTRIBUTING.md) for how to get involved.

{kind=link}
{kind=link}
{kind=link}
{kind=link}