
first init
Showing
Too many changes to show.
To preserve performance only 380 of 380+ files are displayed.
docs/images/res.jpg
0 → 100644
{kind=link}

481 KB
docs/images/road554.png
0 → 100644
{kind=link}

142 KB
docs/images/roadsign_yml.png
0 → 100644
{kind=link}

102 KB
docs/images/ssld_model.png
0 → 100644
{kind=link}
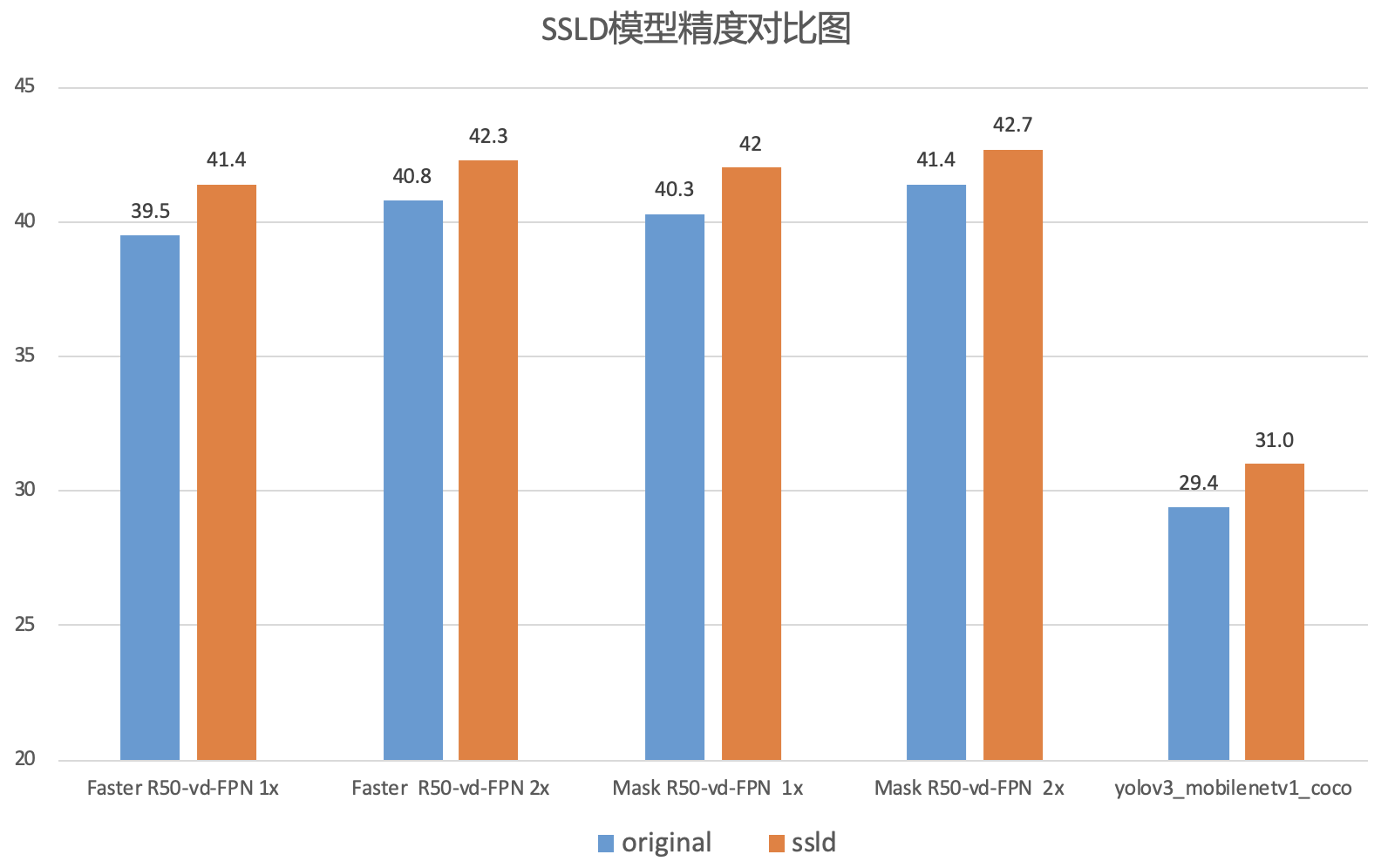
79.7 KB
docs/images/yaml_show.png
0 → 100644
{kind=link}
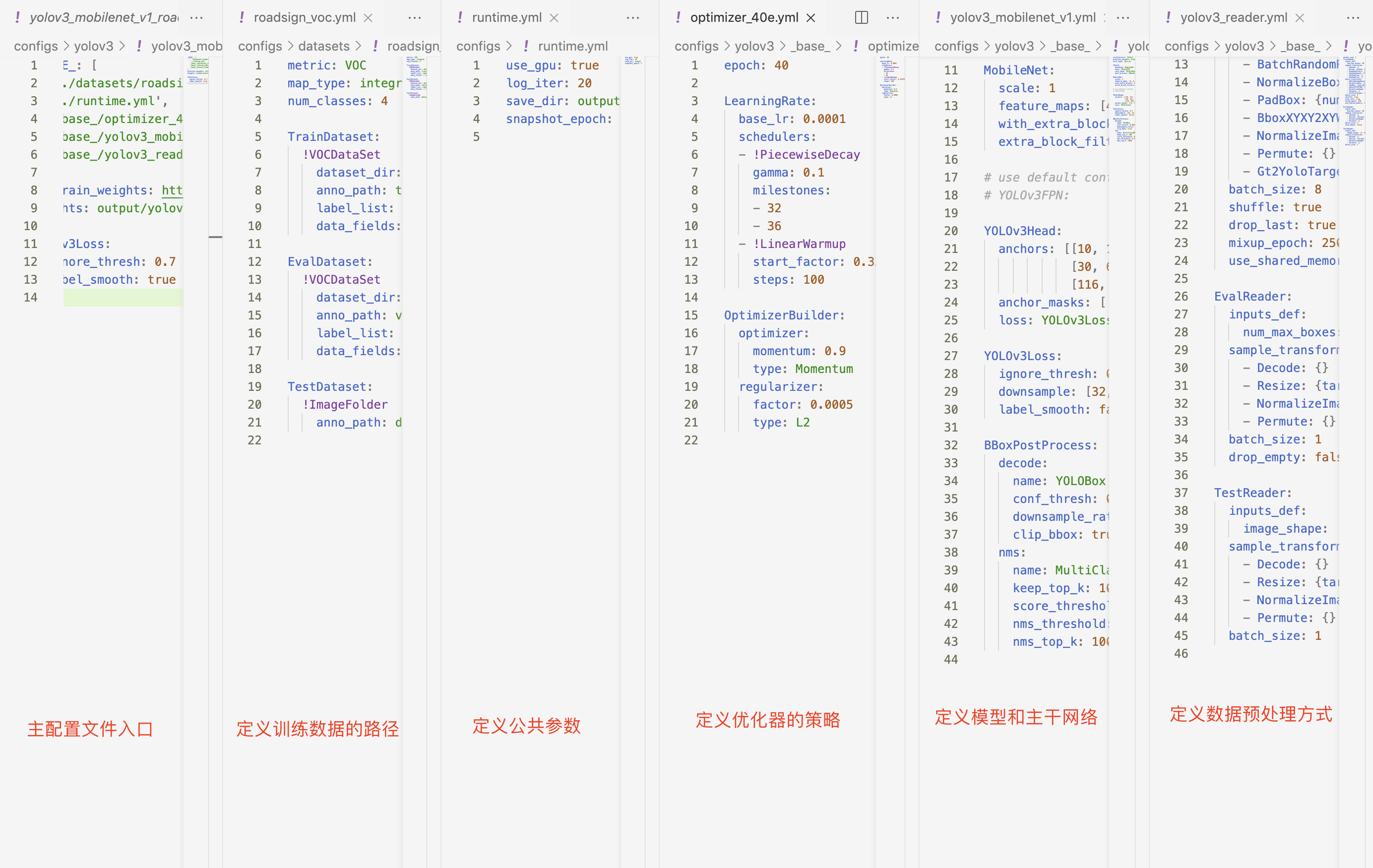
668 KB
docs/tutorials/FAQ/FAQ第一期.md
0 → 100644
docs/tutorials/FAQ/FAQ第零期.md
0 → 100644
docs/tutorials/FAQ/README.md
0 → 100644
docs/tutorials/INSTALL.md
0 → 100644
docs/tutorials/INSTALL_cn.md
0 → 100644