
first init
Showing
LICENSE
0 → 100644
This diff is collapsed.
README.md
deleted
100644 → 0
README_cn.md
0 → 100644
asserts/000000014439.jpg
0 → 100644
{kind=link}

200 KB
asserts/block.jpg
0 → 100644
{kind=link}
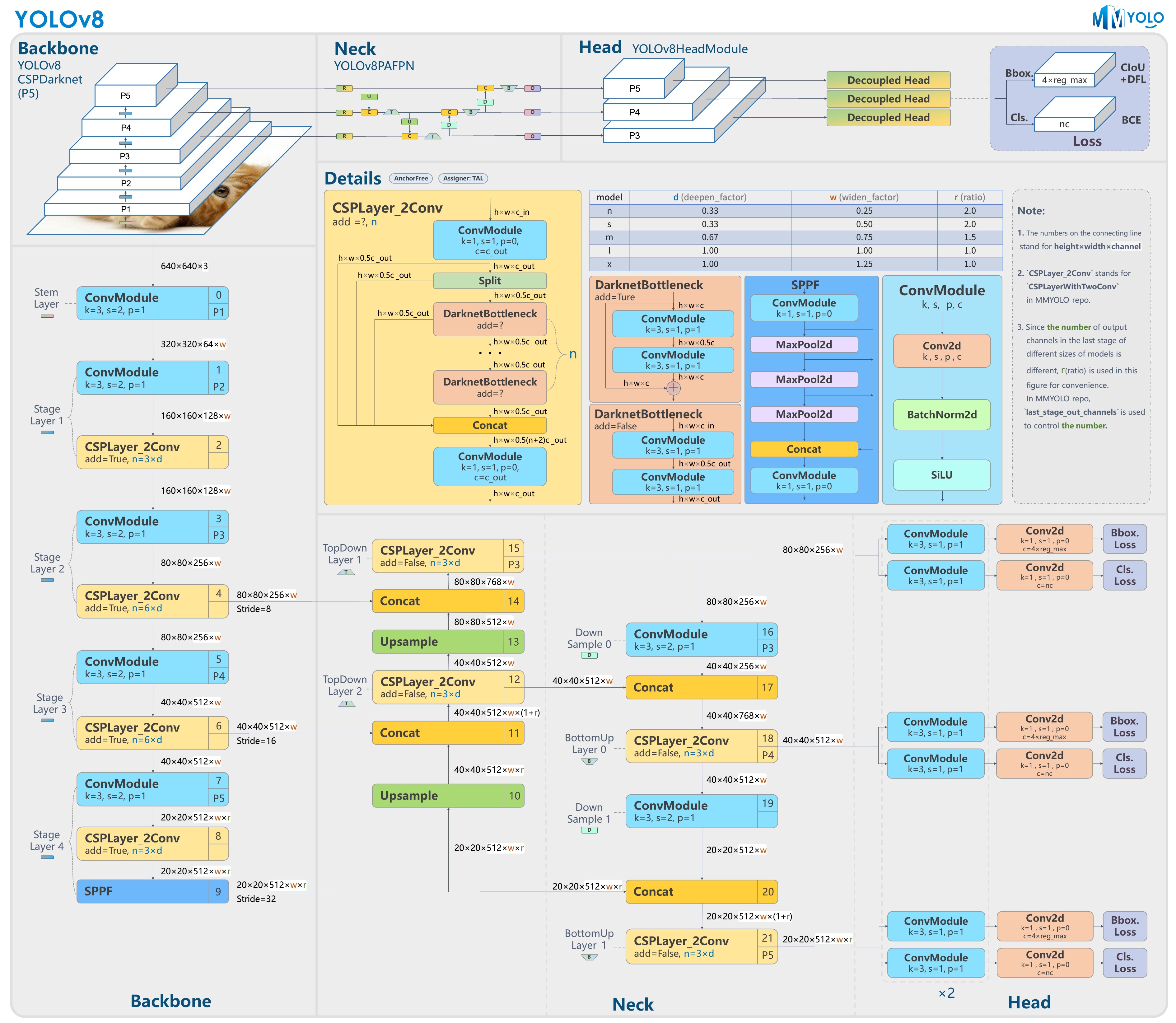
1.35 MB
asserts/model_framework.png
0 → 100644
{kind=link}
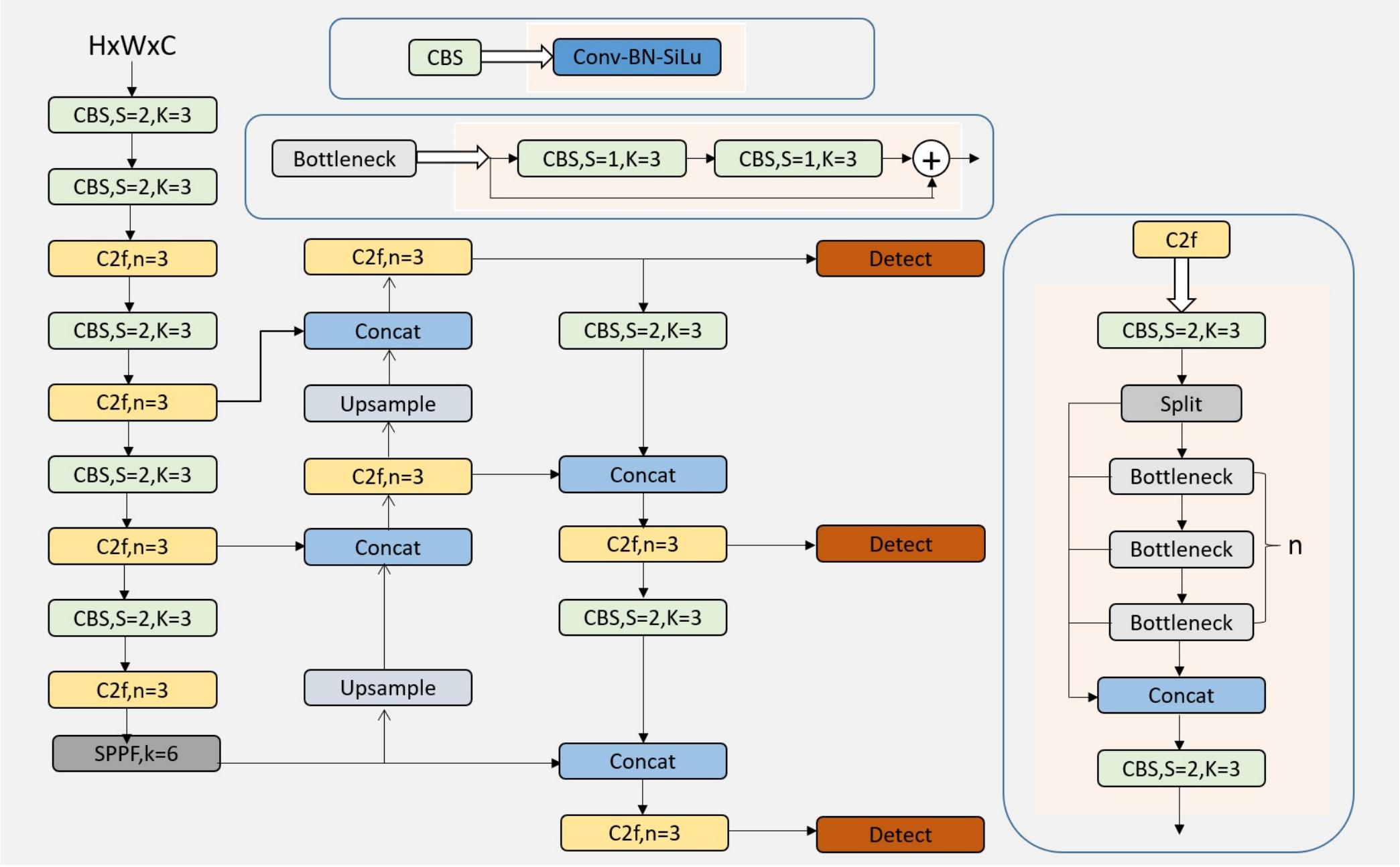
883 KB
bbox.json
0 → 100644
This diff is collapsed.
configs/convnext/README.md
0 → 100644
configs/datasets/voc.yml
0 → 100644
configs/focalnet/README.md
0 → 100644