Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
yolov3_migraphx
Commits
c935706c
Commit
c935706c
authored
Oct 30, 2023
by
liucong
Browse files
更新readme文档
parent
62a40bea
Changes
2
Hide whitespace changes
Inline
Side-by-side
Showing
2 changed files
with
4 additions
and
0 deletions
+4
-0
Doc/YOLOV3_02.png
Doc/YOLOV3_02.png
+0
-0
README.md
README.md
+4
-0
No files found.
Doc/YOLOV3_02.png
0 → 100644
View file @
c935706c
700 KB
README.md
View file @
c935706c
...
@@ -16,6 +16,10 @@ YOLOV3是由Joseph Redmon和Ali Farhadi在2018年提出的单阶段目标检测
...
@@ -16,6 +16,10 @@ YOLOV3是由Joseph Redmon和Ali Farhadi在2018年提出的单阶段目标检测
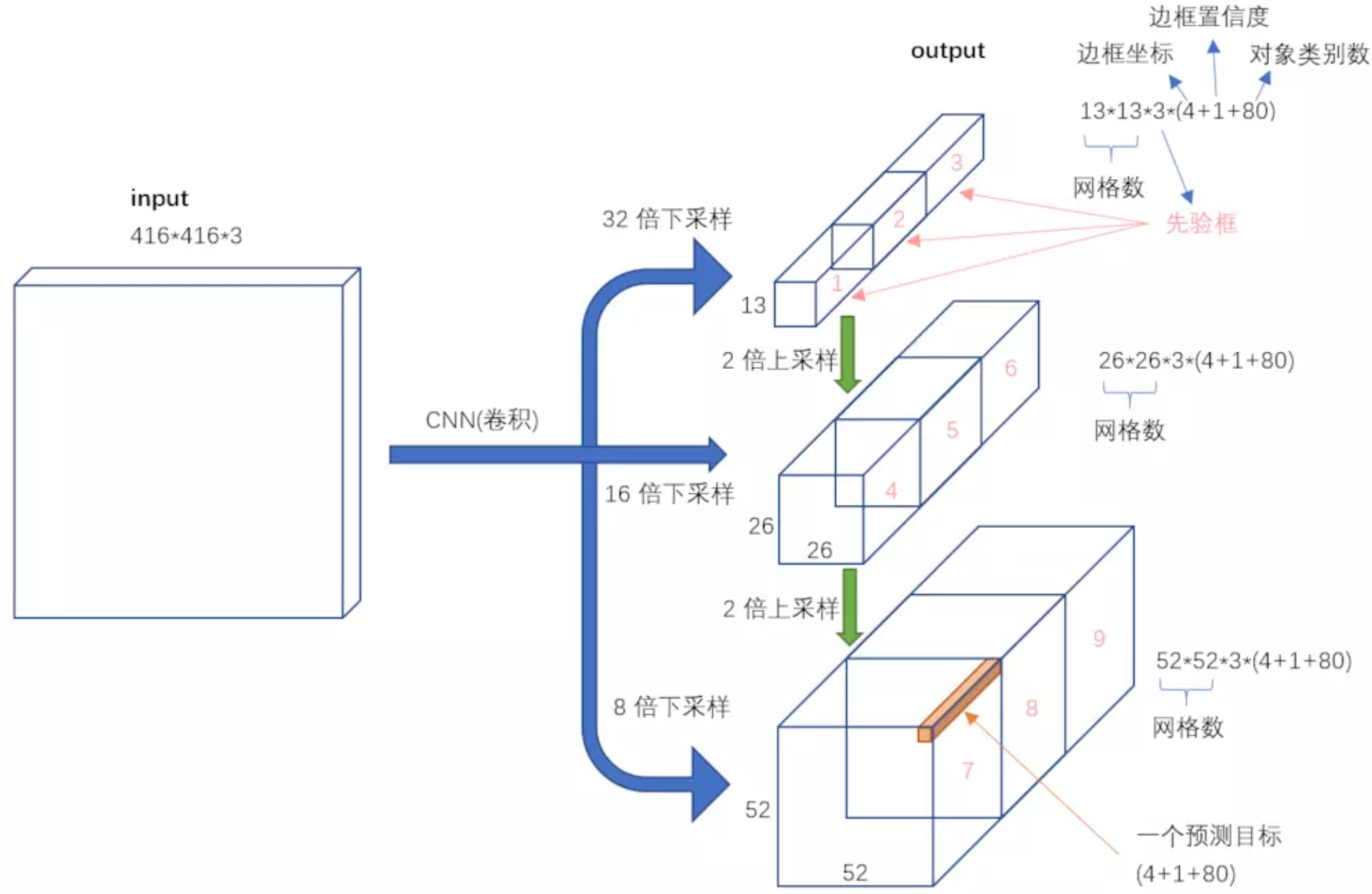
Yolov3算法的基本思想:首先通过特征提取网络对输入提取特征,backbone部分由YOLOV2时期的Darknet19进化至Darknet53加深了网络层数,引入了Resnet中的跨层加和操作;然后结合不同卷积层的特征实现多尺度训练,一共有13x13、26x26、52x52三种分辨率,分别用来预测大、中、小的物体;每种分辨率的特征图将输入图像分成不同数量的格子,每个格子预测B个bounding box,每个bounding box预测内容包括: Location(x, y, w, h)、Confidence Score和C个类别的概率,因此YOLOv3输出层的channel数为B
*
(5 + C)。YOLOv3的loss函数也有三部分组成:Location误差,Confidence误差和分类误差。
Yolov3算法的基本思想:首先通过特征提取网络对输入提取特征,backbone部分由YOLOV2时期的Darknet19进化至Darknet53加深了网络层数,引入了Resnet中的跨层加和操作;然后结合不同卷积层的特征实现多尺度训练,一共有13x13、26x26、52x52三种分辨率,分别用来预测大、中、小的物体;每种分辨率的特征图将输入图像分成不同数量的格子,每个格子预测B个bounding box,每个bounding box预测内容包括: Location(x, y, w, h)、Confidence Score和C个类别的概率,因此YOLOv3输出层的channel数为B
*
(5 + C)。YOLOv3的loss函数也有三部分组成:Location误差,Confidence误差和分类误差。
<img
src=
"./Doc/YOLOV3_02.png"
style=
"zoom:100%;"
align=
middle
>
## 环境配置
## 环境配置
### Docker(方法一)
### Docker(方法一)
...
...
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}