"src/routes/vscode:/vscode.git/clone" did not exist on "872ea83c50a38cacea30c77cd0e64ea67f36d2aa"

v1.0
Showing
Too many changes to show.
To preserve performance only 1000 of 1000+ files are displayed.
CITATION.cff
0 → 100644
CONTRIBUTING.md
0 → 100644
LICENSE
0 → 100644
This diff is collapsed.
README.md
0 → 100644
README_origin.md
0 → 100644
app.py
0 → 100644
benchmark.sh
0 → 100644
doc/SAVPE.png
0 → 100644
{kind=link}
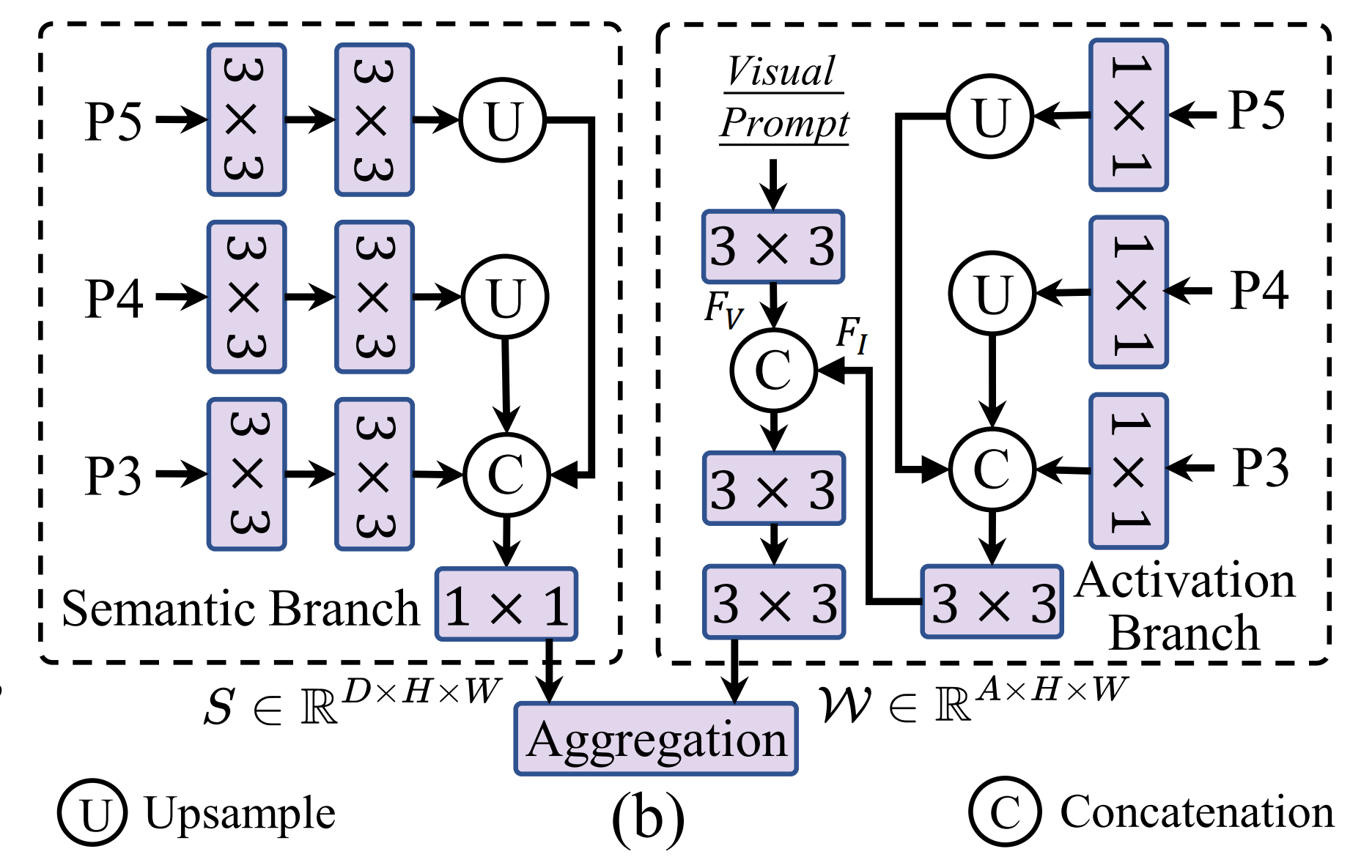
265 KB
doc/bus-output.png
0 → 100644
{kind=link}

1.36 MB
doc/yoloe.png
0 → 100644
{kind=link}
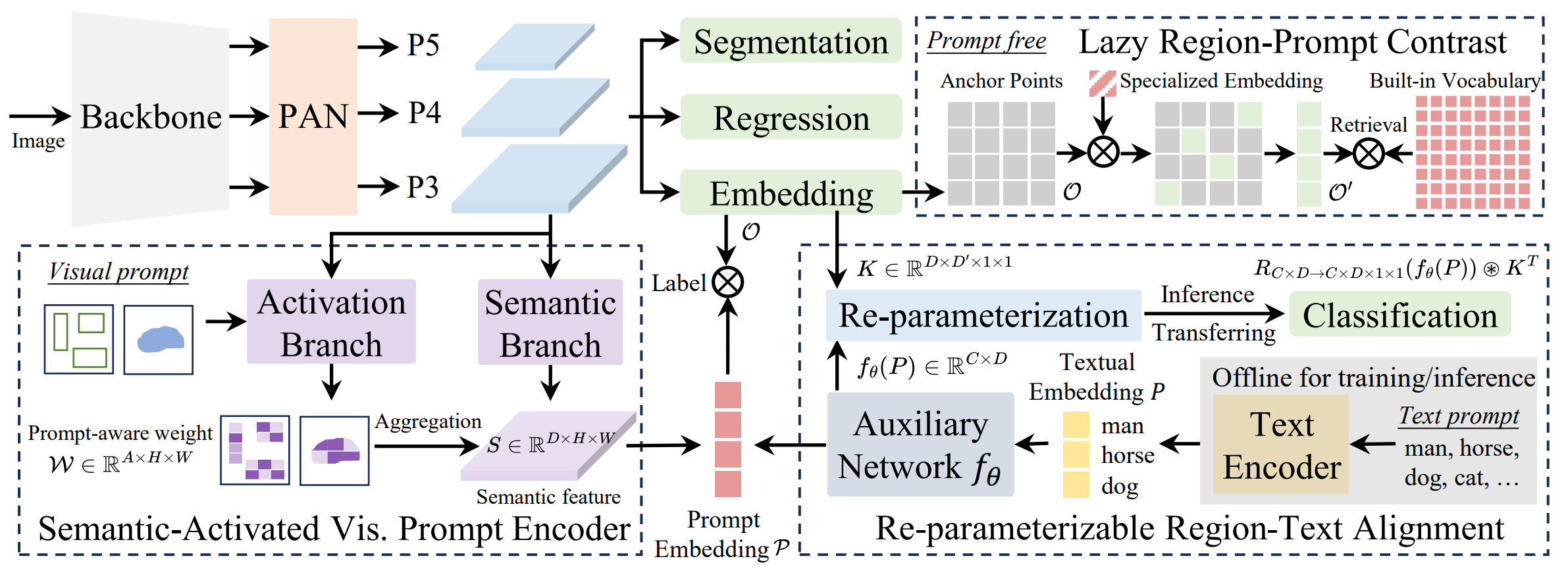
349 KB
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
docker_origin/Dockerfile
0 → 100644
docker_origin/Dockerfile-cpu
0 → 100644