
Initial commit
Showing
.dockerignore
0 → 100644
.gitattributes
0 → 100644
.gitignore
0 → 100644
.gitmodules
0 → 100644
Dockerfile
0 → 100644
LICENSE
0 → 100644
This diff is collapsed.
README.md
0 → 100644
{kind=link}
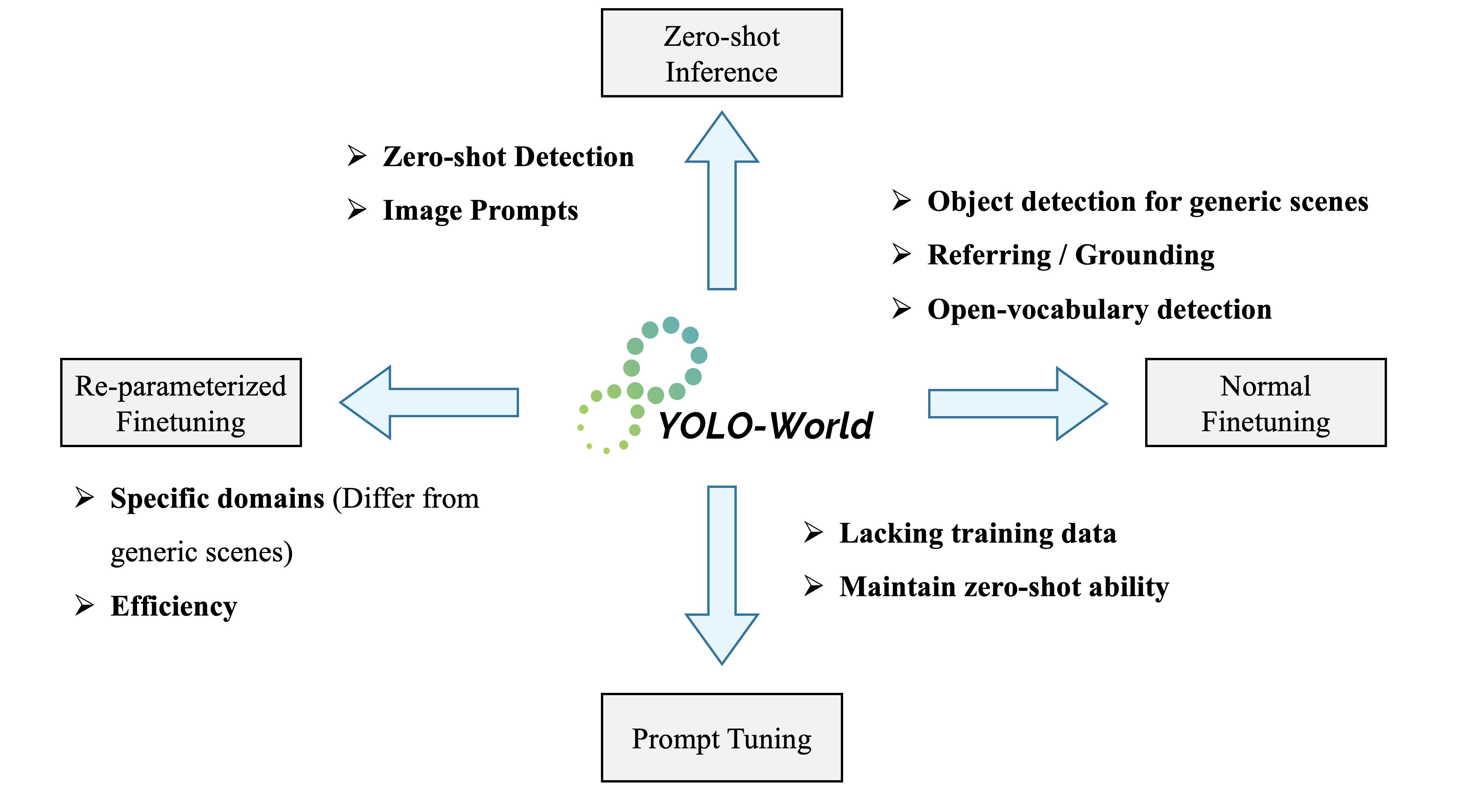
466 KB
assets/reparameterize.png
0 → 100644
{kind=link}
62.8 KB
assets/yolo_arch.png
0 → 100644
{kind=link}
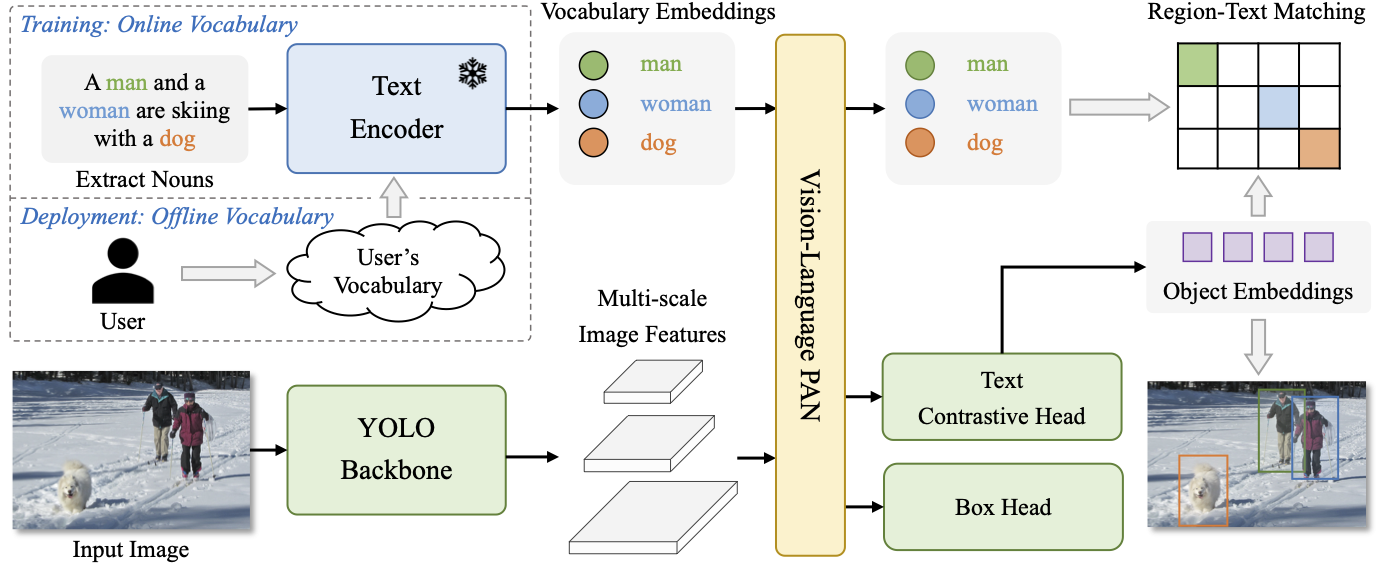
298 KB
assets/yolo_logo.png
0 → 100644
{kind=link}
99.9 KB