
Update doc/inf_result.png, result/result.png, doc/training_loss.png,...
Update doc/inf_result.png, result/result.png, doc/training_loss.png, doc/2403.04652v1.pdf, inference/6B_single_dcu.py, result/training_loss.png, finetune/single_node.sh, finetune/multi_node.sh, finetune/data/dataset_info.json, finetune/data/identity.json, finetune/data/mllm_demo.json, finetune/data/README.md, finetune/data/README_zh.md, finetune/data/alpaca_zh_demo.json, finetune/data/c4_demo.json, finetune/data/glaive_toolcall_en_demo.json, finetune/data/glaive_toolcall_zh_demo.json, finetune/data/alpaca_en_demo.json, finetune/data/dpo_zh_demo.json, finetune/data/kto_en_demo.json, finetune/data/wiki_demo.txt, finetune/data/dpo_en_demo.json, finetune/scripts/cal_flops.py, finetune/scripts/cal_lr.py, finetune/scripts/cal_ppl.py, finetune/scripts/length_cdf.py, finetune/scripts/llamafy_baichuan2.py, finetune/scripts/loftq_init.py, finetune/scripts/llamafy_qwen.py, finetune/scripts/llama_pro.py, finetune/src/api.py, finetune/src/train.py, finetune/src/webui.py, finetune/src/llamafactory/__init__.py, finetune/src/llamafactory/cli.py, finetune/src/llamafactory/api/__init__.py, finetune/src/llamafactory/api/common.py, finetune/src/llamafactory/api/chat.py, finetune/src/llamafactory/api/protocol.py, finetune/src/llamafactory/api/app.py, finetune/src/llamafactory/chat/__init__.py, finetune/src/llamafactory/chat/base_engine.py, finetune/src/llamafactory/chat/hf_engine.py, finetune/src/llamafactory/chat/vllm_engine.py, finetune/src/llamafactory/chat/chat_model.py, finetune/src/llamafactory/data/__init__.py, finetune/src/llamafactory/data/collator.py, finetune/src/llamafactory/data/utils.py, finetune/src/llamafactory/data/aligner.py, finetune/src/llamafactory/data/formatter.py, finetune/src/llamafactory/data/preprocess.py, finetune/src/llamafactory/data/parser.py, finetune/src/llamafactory/data/loader.py, finetune/src/llamafactory/data/template.py, finetune/src/llamafactory/eval/__init__.py, finetune/src/llamafactory/eval/evaluator.py, finetune/src/llamafactory/eval/template.py, finetune/src/llamafactory/extras/__init__.py, finetune/src/llamafactory/extras/ploting.py, finetune/src/llamafactory/extras/logging.py, finetune/src/llamafactory/extras/constants.py, finetune/src/llamafactory/extras/misc.py, finetune/src/llamafactory/extras/packages.py, finetune/src/llamafactory/extras/callbacks.py, finetune/src/llamafactory/hparams/__init__.py, finetune/src/llamafactory/hparams/data_args.py, finetune/src/llamafactory/hparams/evaluation_args.py, finetune/src/llamafactory/hparams/generating_args.py, finetune/src/llamafactory/hparams/finetuning_args.py, finetune/src/llamafactory/hparams/parser.py, finetune/src/llamafactory/hparams/model_args.py, finetune/src/llamafactory/model/__init__.py, finetune/src/llamafactory/model/adapter.py, finetune/src/llamafactory/model/loader.py, finetune/src/llamafactory/model/patcher.py, finetune/src/llamafactory/model/utils/__init__.py, finetune/src/llamafactory/model/utils/checkpointing.py, finetune/src/llamafactory/model/utils/embedding.py, finetune/src/llamafactory/model/utils/moe.py, finetune/src/llamafactory/model/utils/attention.py, finetune/src/llamafactory/model/utils/quantization.py, finetune/src/llamafactory/model/utils/valuehead.py, finetune/src/llamafactory/model/utils/longlora.py, finetune/src/llamafactory/model/utils/visual.py, finetune/src/llamafactory/model/utils/misc.py, finetune/src/llamafactory/model/utils/mod.py, finetune/src/llamafactory/model/utils/unsloth.py, finetune/src/llamafactory/model/utils/rope.py, finetune/src/llamafactory/train/__init__.py, finetune/src/llamafactory/train/utils.py, finetune/src/llamafactory/train/tuner.py, finetune/src/llamafactory/train/dpo/__init__.py, finetune/src/llamafactory/train/dpo/trainer.py, finetune/src/llamafactory/train/dpo/workflow.py, finetune/src/llamafactory/train/kto/__init__.py, finetune/src/llamafactory/train/kto/workflow.py, finetune/src/llamafactory/train/kto/trainer.py, finetune/src/llamafactory/train/orpo/__init__.py, finetune/src/llamafactory/train/orpo/workflow.py, finetune/src/llamafactory/train/orpo/trainer.py, finetune/src/llamafactory/train/ppo/__init__.py, finetune/src/llamafactory/train/ppo/workflow.py, finetune/src/llamafactory/train/ppo/utils.py, finetune/src/llamafactory/train/ppo/trainer.py, finetune/src/llamafactory/train/pt/__init__.py, finetune/src/llamafactory/train/pt/trainer.py, finetune/src/llamafactory/train/pt/workflow.py, finetune/src/llamafactory/train/rm/__init__.py, finetune/src/llamafactory/train/rm/metric.py, finetune/src/llamafactory/train/rm/trainer.py, finetune/src/llamafactory/train/rm/workflow.py, finetune/src/llamafactory/train/sft/__init__.py, finetune/src/llamafactory/train/sft/workflow.py, finetune/src/llamafactory/train/sft/trainer.py, finetune/src/llamafactory/train/sft/metric.py, finetune/src/llamafactory/webui/__init__.py, finetune/src/llamafactory/webui/chatter.py, finetune/src/llamafactory/webui/common.py, finetune/src/llamafactory/webui/interface.py, finetune/src/llamafactory/webui/runner.py, finetune/src/llamafactory/webui/css.py, finetune/src/llamafactory/webui/engine.py, finetune/src/llamafactory/webui/utils.py, finetune/src/llamafactory/webui/manager.py, finetune/src/llamafactory/webui/locales.py, finetune/src/llamafactory/webui/components/__init__.py, finetune/src/llamafactory/webui/components/data.py, finetune/src/llamafactory/webui/components/chatbot.py, finetune/src/llamafactory/webui/components/train.py, finetune/src/llamafactory/webui/components/top.py, finetune/src/llamafactory/webui/components/infer.py, finetune/src/llamafactory/webui/components/eval.py, finetune/src/llamafactory/webui/components/export.py files
Showing
doc/2403.04652v1.pdf
0 → 100644
File added
doc/inf_result.png
0 → 100644
{kind=link}

77.9 KB
doc/training_loss.png
0 → 100644
{kind=link}
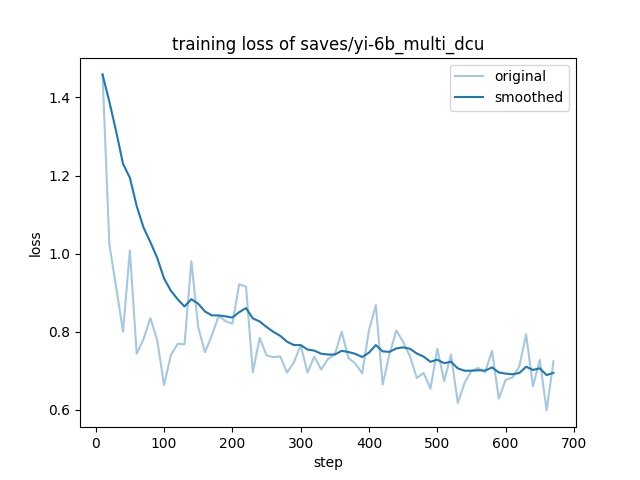
40.8 KB
finetune/data/README.md
0 → 100644
finetune/data/README_zh.md
0 → 100644
This diff is collapsed.
This diff is collapsed.
finetune/data/c4_demo.json
0 → 100644
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
finetune/data/identity.json
0 → 100644
This diff is collapsed.
This diff is collapsed.
finetune/data/mllm_demo.json
0 → 100644
finetune/data/wiki_demo.txt
0 → 100644
This diff is collapsed.
finetune/multi_node.sh
0 → 100644
finetune/scripts/cal_lr.py
0 → 100644