
wan2.1
Showing
LICENSE.txt
0 → 100644
README.md
0 → 100644
README_official.md
0 → 100644
This diff is collapsed.
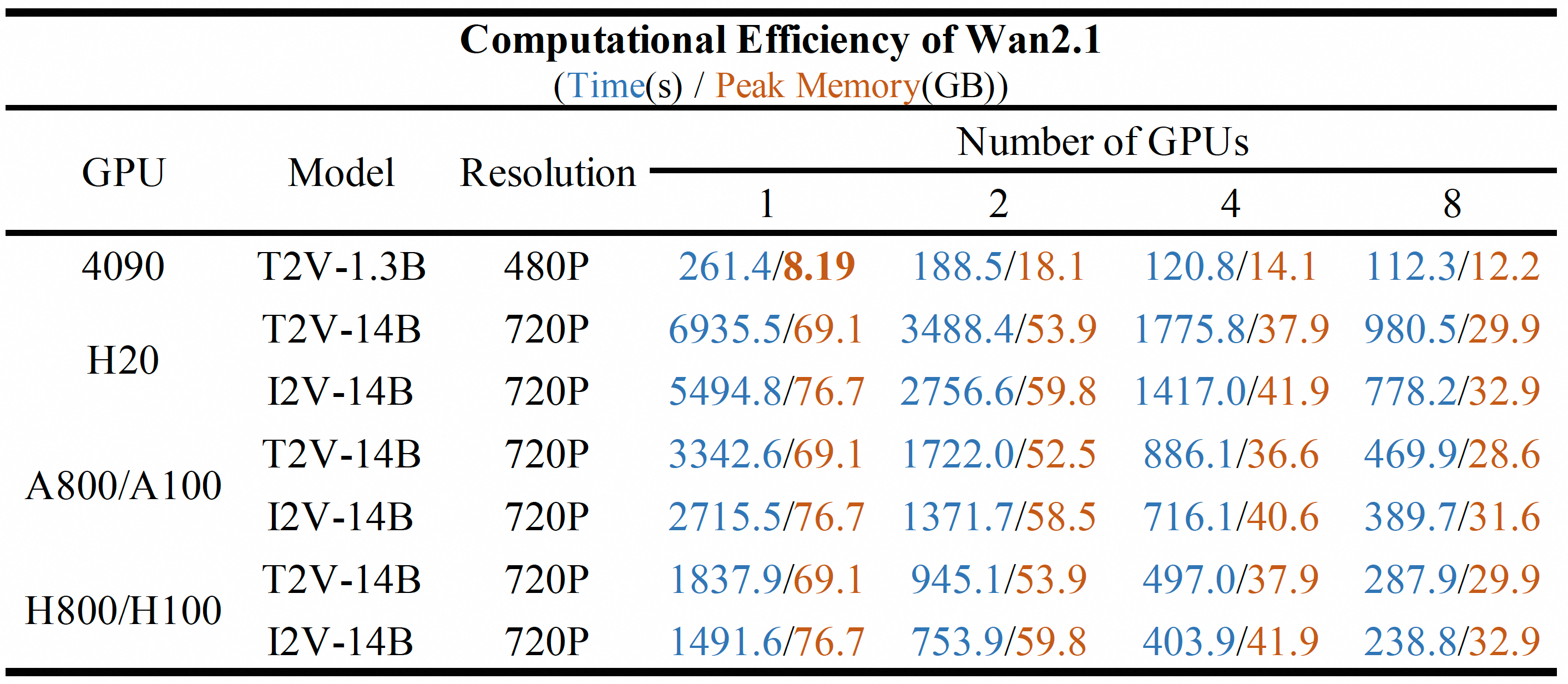
assets/comp_effic.png
0 → 100644
{kind=link}
1.71 MB
{kind=link}
516 KB
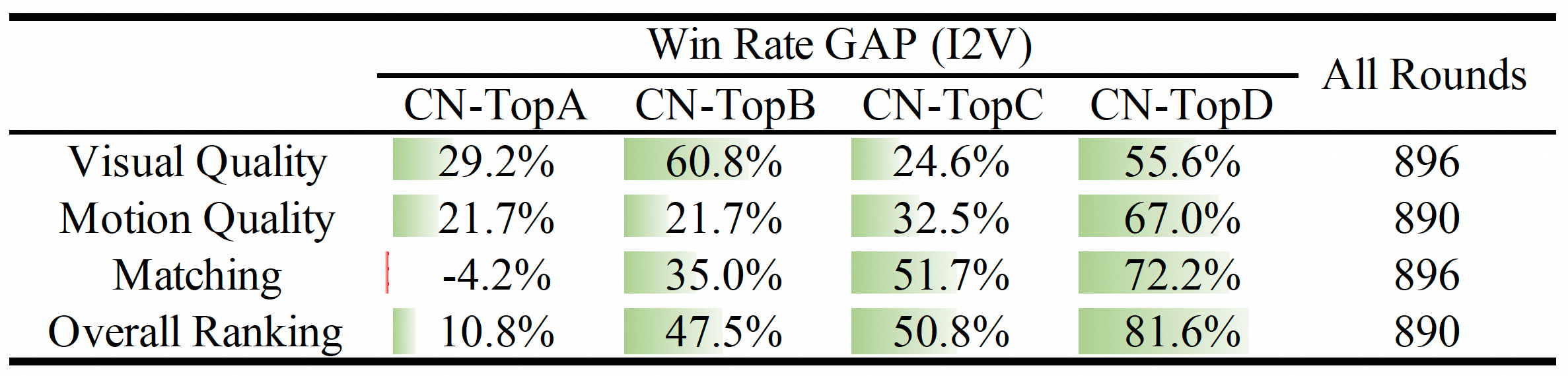
assets/i2v_res.png
0 → 100644
{kind=link}
871 KB
assets/logo.png
0 → 100644
{kind=link}
55 KB
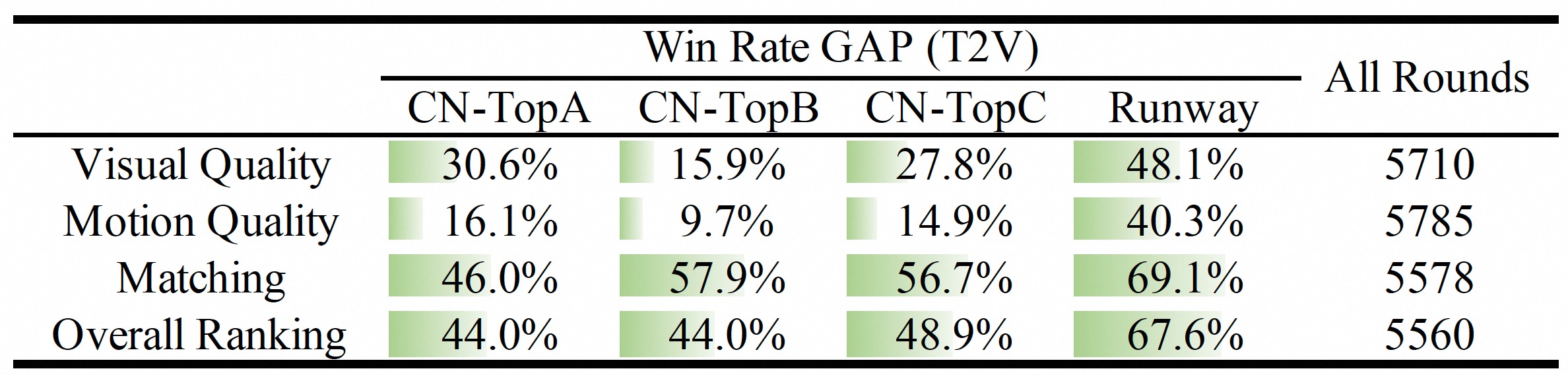
assets/t2v_res.jpg
0 → 100644
{kind=link}
294 KB
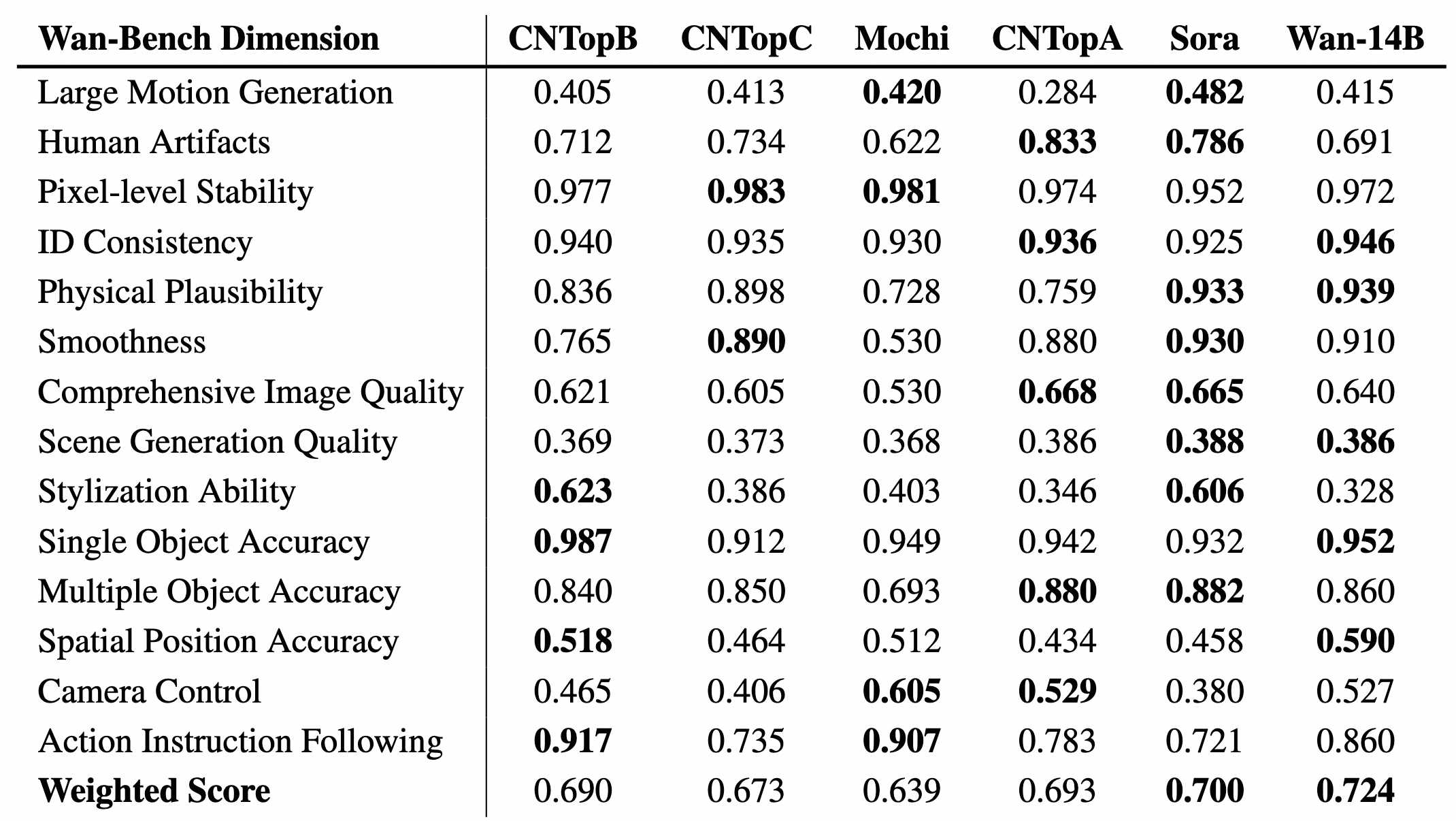
assets/vben_vs_sota.png
0 → 100644
{kind=link}
1.48 MB
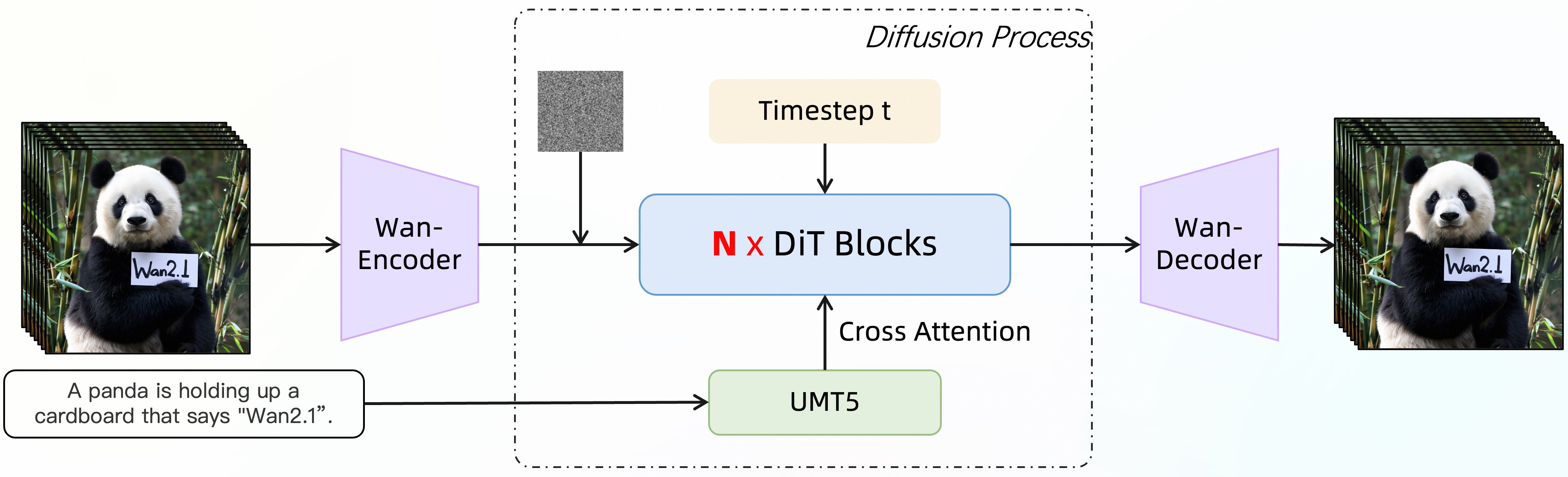
assets/video_dit_arch.jpg
0 → 100644
{kind=link}
628 KB
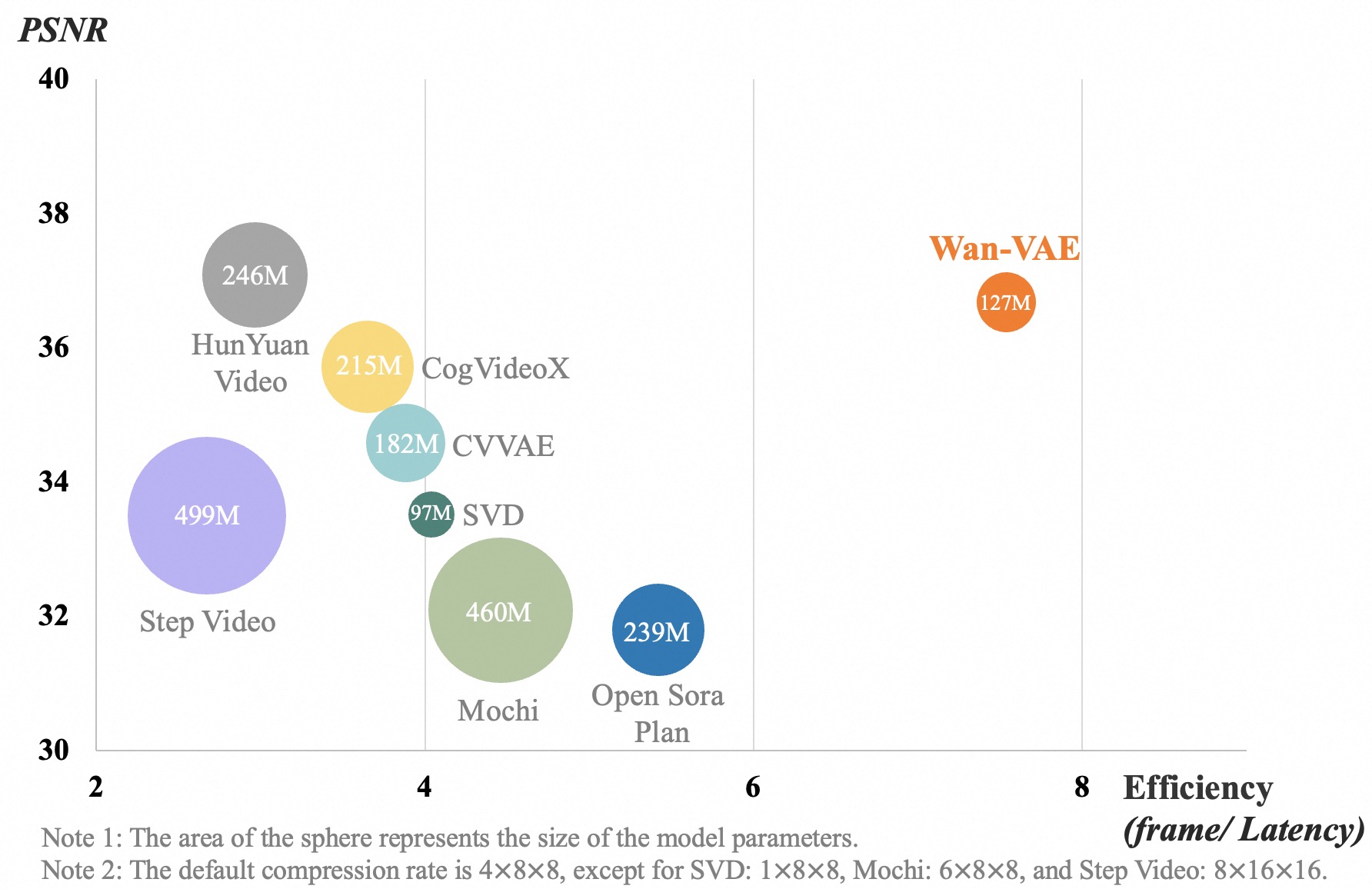
assets/video_vae_res.jpg
0 → 100644
{kind=link}
208 KB
examples/i2v_input.JPG
0 → 100644
{kind=link}

245 KB
generate.py
0 → 100644
gradio/i2v_14B_singleGPU.py
0 → 100644
gradio/t2i_14B_singleGPU.py
0 → 100644
gradio/t2v_1.3B_singleGPU.py
0 → 100644
gradio/t2v_14B_singleGPU.py
0 → 100644
icon.png
0 → 100644
{kind=link}
70.5 KB
model.properties
0 → 100644
modified/config.py
0 → 100644