
提交ViT代码
Showing
.gitignore
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
Vit-README.md
0 → 100644
img/figure1.png
0 → 100644
{kind=link}
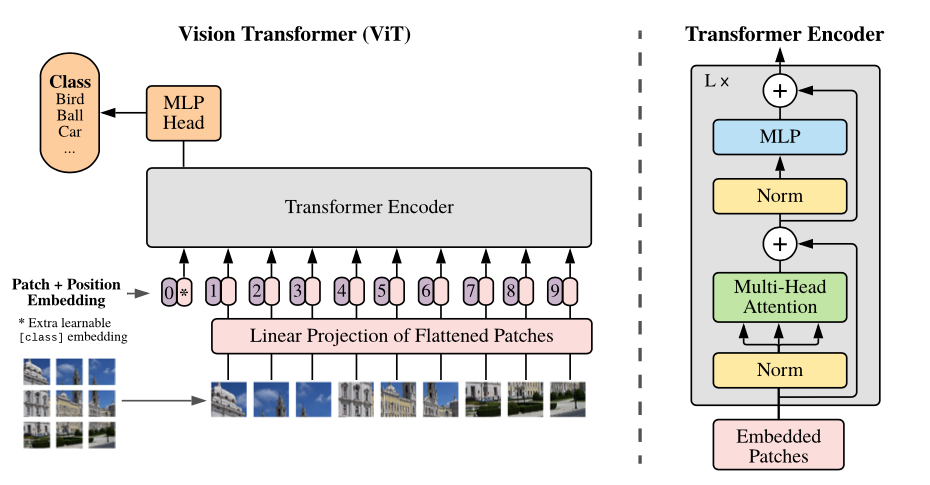
127 KB
img/figure2.png
0 → 100644
{kind=link}
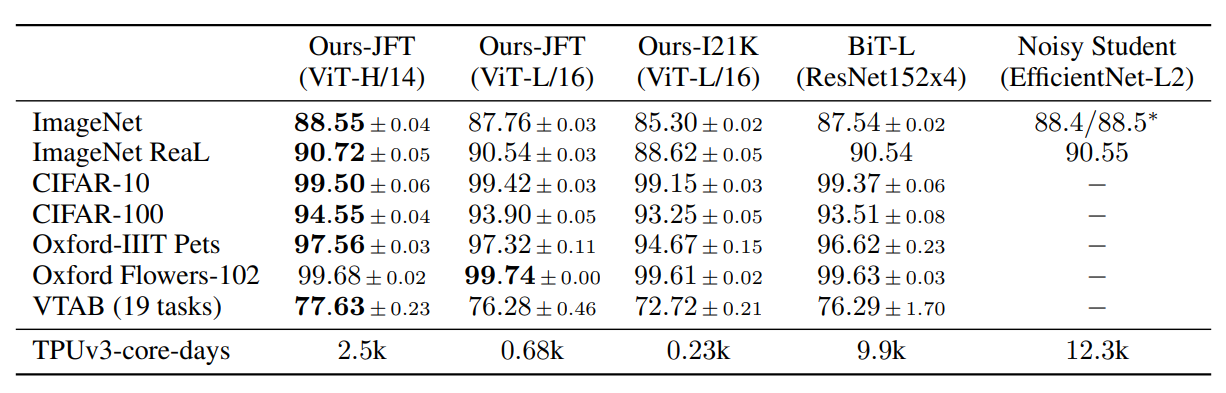
137 KB
img/figure3.png
0 → 100644
{kind=link}

430 KB
logs-z100.txt
0 → 100644
File added
File added
File added
File added
File added
File added
File added
File added
File added
File added
File added
File added