Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
ViT_pytorch
Commits
19ee37d6
Commit
19ee37d6
authored
Sep 09, 2023
by
sunxx1
Browse files
修改readme
parent
26d429a4
Changes
3
Hide whitespace changes
Inline
Side-by-side
Showing
3 changed files
with
83 additions
and
17 deletions
+83
-17
README.md
README.md
+72
-17
docker/Dockerfile
docker/Dockerfile
+7
-0
docker/requirements.txt
docker/requirements.txt
+4
-0
No files found.
README.md
View file @
19ee37d6
# Vision Transformer(ViT)
# Vision Transformer(ViT)
## 模型介绍
## 论文
Vision Transformer(ViT)是一种新的基于Transformer的神经网络模型,它是由Google Brain团队提出的。ViT的主要目标是将Transformer模型应用于计算机视觉领域,以替代传统的卷积神经网络(CNN)模型。ViT模型的核心思想是将图像转换为一组序列,并将它们输入到Transformer模型中进行处理。这个序列可以通过将图像划分为不重叠的小块(称为“补丁”)来生成,然后将每个补丁的像素值摊平为一个向量。这些向量被串联成一个长序列,然后输入到Transformer模型中。与CNN模型不同,ViT模型不需要池化或卷积层来处理输入图像。相反,它使用多头自注意力层(multi-head self-attention layer)来对输入序列进行建模。这些自注意力层允许模型在序列中的任何两个位置之间进行交互和信息传递,从而更好地捕捉图像中的全局关系。最后, ViT模型可以通过一个全连接层或者平均池化层输出最终的分类结果。ViT模型相对于CNN模型具有几个优点。首先,ViT模型可以处理任意大小的图像,而CNN模型通常需要在输入图像上进行裁剪或缩放。其次,ViT模型可以更好地处理全局关系,因为每个像素都可以与其他像素进行交互。最后,ViT模型可以很容易地应用于其他任务,例如对象检测或分割,只需在输出层进行一些修改即可。总体来说,ViT模型是一种新的、有前途的计算机视觉模型,它提供了一种基于Transformer的新思路,可以在不同的视觉任务上取得很好的性能。
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
https://arxiv.org/abs/2010.11929
## 模型结构
## 模型结构
vision transformer模型结构如下图所示主要包括三部分,patch embeding 部分、transformer encoder部分、MLP head部分。ViT将输入图片分为多个patch,再将每个patch投影为固定长度的向量送入Transformer,后续encoder的操作和原始Transformer中完全相同。但是因为对图片分类,因此在输入序列中加入一个特殊的token,该token对应的输出即为最后的类别预测。
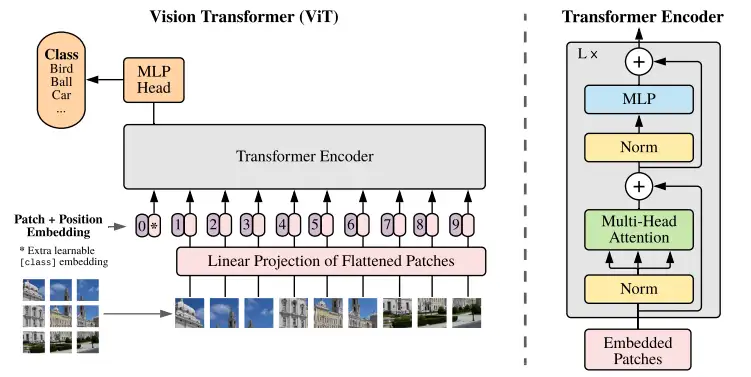
Vision Transformer先将图像用卷积进行分块以降低计算量,再对每一块进行展平处理变成序列,然后将序列添加位置编码和cls token,再输入多层Transformer结构提取特征,最后将cls tooken取出来通过一个MLP(多层感知机)用于分类。
## 数据集

## 算法原理
图像领域借鉴《Transformer is all you need!》算法论文中的Encoder结构提取特征,Transformer的核心思想是利用注意力模块attention提取特征:

## 环境配置
### Docker(方法一)
```
plaintext
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.10.0-centos7.6-dtk-22.10.1-py37-latest
# <your IMAGE ID>用以上拉取的docker的镜像ID替换
docker run --shm-size 10g --network=host --name=nit-pytorch --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v $PWD/megatron-deepspeed-vit:/home/vit-pytorch -it <your IMAGE ID> bash
pip install -r requirements.txt
```
### Dockerfile(方法二)
```
plaintext
cd ViT-PyTorch/docker
docker build --no-cache -t ViT-PyTorch:latest .
docker run --rm --shm-size 10g --network=host --name=megatron --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v $PWD/../../ViT-PyTorch:/home/ViT-PyTorch -it megatron bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
在本测试中可以使用cifar10数据集。
```
plaintext
DTK驱动:dtk22.10.1
python:python3.7
torch:1.10.0
torchvision:0.10.0
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应
```
2、其它非特殊库参照requirements.txt安装
数据集处理方法请参考cifar10官方介绍自行处理,也可通过下面链接下载,将数据放在data目录下。
```
plaintext
pip install -r requirements.txt
```
链接:链接:https://pan.baidu.com/s/1ZFMQVBGQZI6UWZKJcTYPAQ?pwd=fq3l 提取码:fq3l
## 数据集
## ViT训练
cifar10
### 环境配置
提供
[
光源
](
https://www.sourcefind.cn/#/service-details
)
拉取的训练以及推理的docker镜像:
*
训练镜像:docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.10.0-centos7.6-dtk-22.10.1-py37-latest
*
pip install -r requirements.txt
### 训练
链接:https://pan.baidu.com/s/1ZFMQVBGQZI6UWZKJcTYPAQ?pwd=fq3l 提取码:fq3l
## 训练
下载预训练模型放在checkpoint目录下:
下载预训练模型放在checkpoint目录下:
```
```
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
```
```
训练命令:
### 单机单卡
export HIP_VISIBLE_DEVICES=
3
export HIP_VISIBLE_DEVICES=
0
python3 -m torch.distributed.launch --nproc_per_node=1 train.py --name cifar10-100_500 --dataset cifar10 --model_type ViT-B_16 --pretrained_dir checkpoint/ViT-B_16.npz --train_batch_size 64 --num_steps 500
python3 -m torch.distributed.launch --nproc_per_node=1 train.py --name cifar10-100_500 --dataset cifar10 --model_type ViT-B_16 --pretrained_dir checkpoint/ViT-B_16.npz --train_batch_size 64 --num_steps 500
## 准确率数据
### 单机多卡
```
python3 -m torch.distributed.launch --nproc_per_node=8 train.py --name cifar10-100_500 --dataset cifar10 --model_type ViT-B_16 --pretrained_dir checkpoint/ViT-B_16.npz --train_batch_size 64 --num_steps 500
```
## 精度
测试数据使用的是cifar10,使用的加速卡是DCU Z100L。
测试数据使用的是cifar10,使用的加速卡是DCU Z100L。
| 卡数 | 精度 |
| 卡数 | 精度 |
| :------: | :------: |
| :------: | :------: |
| 1 | Best Accuracy=0.3051 |
| 1 | Best Accuracy=0.3051 |
## 应用场景
### 算法类别
图像分类
### 热点行业
制造,能源,交通,网安
### 源码仓库及问题反馈
### 源码仓库及问题反馈
https://developer.hpccube.com/codes/modelzoo/vit-pytorch
https://developer.hpccube.com/codes/modelzoo/vit-pytorch
...
...
docker/Dockerfile
0 → 100644
View file @
19ee37d6
FROM
image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.10.0-centos7.6-dtk-22.10.1-py37-latest
ENV
DEBIAN_FRONTEND=noninteractive
# RUN yum update && yum install -y git cmake wget build-essential
RUN
source
/opt/dtk-22.10.1/env.sh
# 安装pip相关依赖
COPY
requirements.txt requirements.txt
RUN
pip3
install
-i
http://mirrors.aliyun.com/pypi/simple/
--trusted-host
mirrors.aliyun.com
-r
requirements.txt
docker/requirements.txt
0 → 100644
View file @
19ee37d6
numpy
tqdm
tensorboard
ml-collections
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment
