Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
VisualGLM-6B_pytorch
Commits
2f487cb5
Commit
2f487cb5
authored
Mar 04, 2024
by
wangsen
Browse files
update readme.md
parent
03a9fae0
Changes
3
Hide whitespace changes
Inline
Side-by-side
Showing
3 changed files
with
10 additions
and
3 deletions
+10
-3
README.md
README.md
+9
-2
doc/Former.png
doc/Former.png
+0
-0
model.properties
model.properties
+1
-1
No files found.
README.md
View file @
2f487cb5
...
@@ -4,15 +4,18 @@
...
@@ -4,15 +4,18 @@
无
无
## 模型结构
## 模型结构
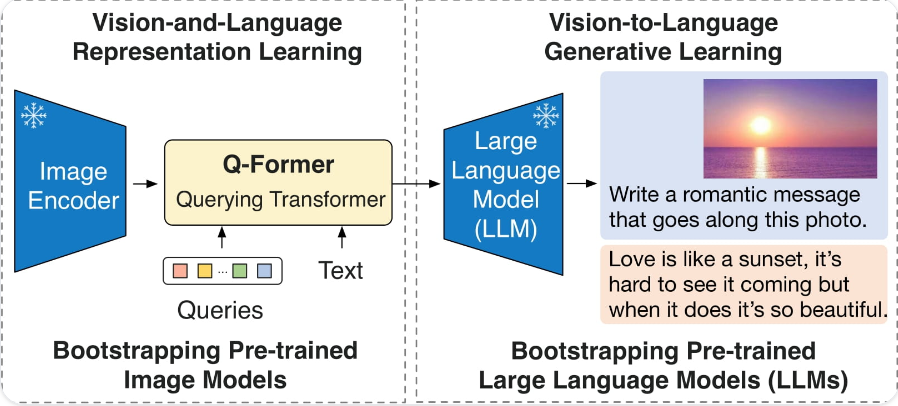
VisualGLM 模型架构是 ViT + QFormer + ChatGLM,在预训练阶段对 QFormer 和 ViT LoRA 进行训练,在微调阶段对 QFormer 和 ChatGLM LoRA 进行训练,训练目标是自回归损失(根据图像生成正确的文本)和对比损失(输入 ChatGLM 的视觉特征与对应文本的语义特征对齐)
VisualGLM 模型架构是 ViT + QFormer + ChatGLM,在预训练阶段对 QFormer 和 ViT LoRA 进行训练,在微调阶段对 QFormer 和 ChatGLM LoRA 进行训练,训练目标是自回归损失(根据图像生成正确的文本)和对比损失(输入 ChatGLM 的视觉特征与对应文本的语义特征对齐)
<div
align=
center
>
<div
align=
center
>
<img
src=
"./doc/image.png"
/>
<img
src=
"./doc/image.png"
/>
</div>
</div>
## 算法原理
## 算法原理
VisualGLM-6B 是一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。
VisualGLM-6B 是一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。
VisualGLM-6B 由 SwissArmyTransformer(简称sat) 库训练,这是一个支持Transformer灵活修改、训练的工具库,支持Lora、P-tuning等参数高效微调方法。本项目提供了符合用户习惯的huggingface接口,也提供了基于sat的接口。
VisualGLM-6B 由 SwissArmyTransformer(简称sat) 库训练,这是一个支持Transformer灵活修改、训练的工具库,支持Lora、P-tuning等参数高效微调方法。本项目提供了符合用户习惯的huggingface接口,也提供了基于sat的接口。
<div
align=
center
>
<img
src=
"./doc/Former.png"
/>
</div>
## 环境配置
## 环境配置
### Docker(方法一)
### Docker(方法一)
...
@@ -80,6 +83,10 @@ curl -X POST -H "Content-Type: application/json" -d @temp.json http://127.0.0.1:
...
@@ -80,6 +83,10 @@ curl -X POST -H "Content-Type: application/json" -d @temp.json http://127.0.0.1:
以目录中examples/1.jpeg图片进行推理为例,推理后的结果为:
以目录中examples/1.jpeg图片进行推理为例,推理后的结果为:
"泰坦尼克号,男女主角在船头拥抱。海水翻涌,他们的爱情如海浪般澎湃。 夕阳余晖下,两人的身影渐渐消失。"
"泰坦尼克号,男女主角在船头拥抱。海水翻涌,他们的爱情如海浪般澎湃。 夕阳余晖下,两人的身影渐渐消失。"
<div
align=
center
>
<img
src=
"./examples/1.jpeg"
/>
</div>
### 精度
### 精度
无
无
## 应用场景
## 应用场景
...
...
doc/Former.png
0 → 100644
View file @
2f487cb5
248 KB
model.properties
View file @
2f487cb5
...
@@ -4,6 +4,6 @@ modelCode = 525
...
@@ -4,6 +4,6 @@ modelCode = 525
modelName
=
visualglm6b_pytorch
modelName
=
visualglm6b_pytorch
modelDescription
=
VisualGLM-6B 是一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数
modelDescription
=
VisualGLM-6B 是一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数
# 应用场景
# 应用场景
appScenario
=
推理,
多模态推理,
零售,广媒,科研,图像理解
appScenario
=
推理,零售,广媒,科研,图像理解
frameType
=
pytorch
frameType
=
pytorch
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}