
添加README等
Showing
README.md
0 → 100644
doc/vit.png
0 → 100644
{kind=link}
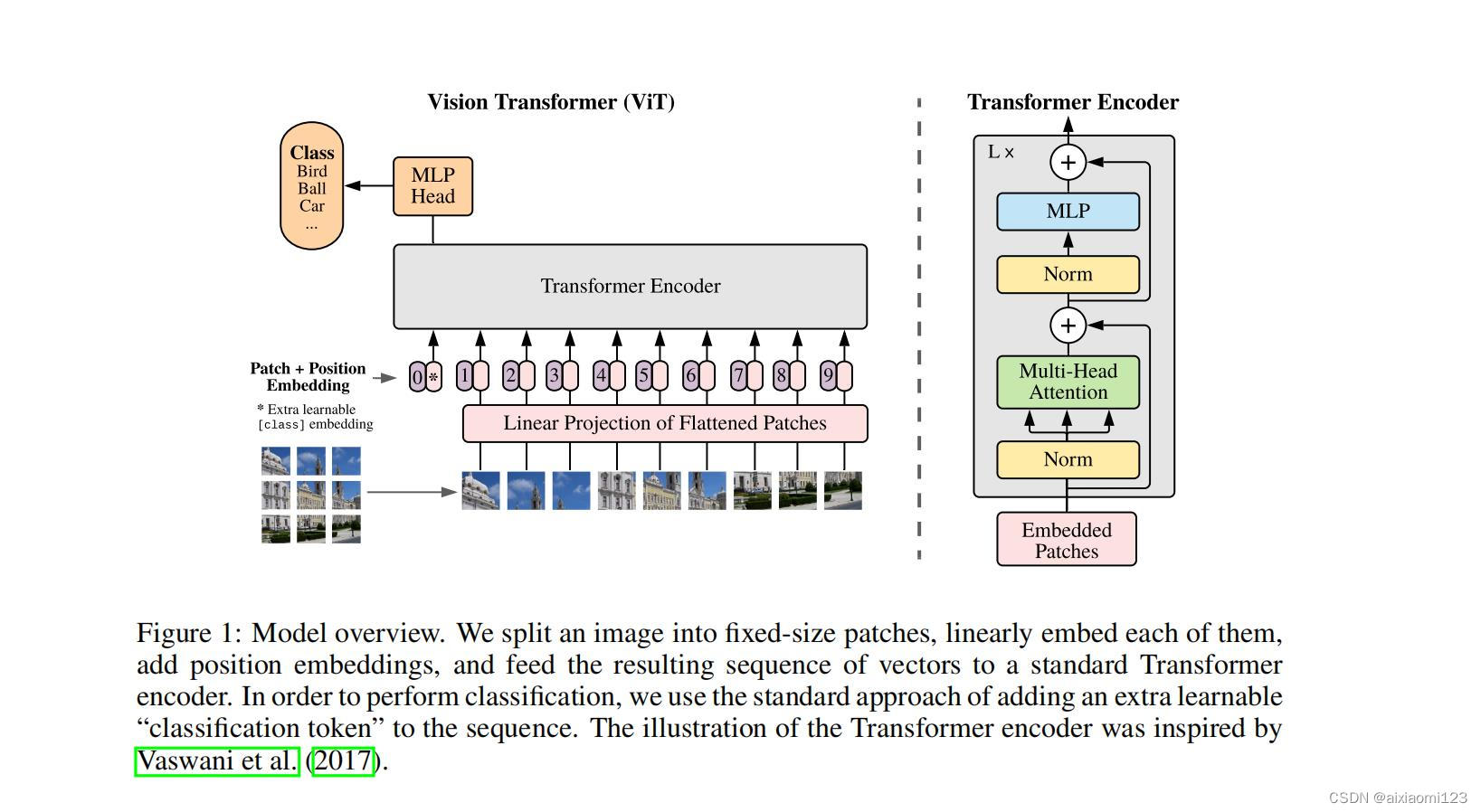
604 KB
model.properties
0 → 100644
| ... | ... | @@ -10,7 +10,7 @@ git+https://github.com/google/flaxformer |
| ml-collections>=0.1.0 | ||
| numpy>=1.19.5 | ||
| pandas>=1.1.0 | ||
| tensorflow-cpu>=2.13.0 # tensorflow-cpu>=2.4.0 # Using tensorflow-cpu to have all GPU memory for JAX. | ||
| tensorflow-cpu==2.13.1 # tensorflow-cpu>=2.4.0 # Using tensorflow-cpu to have all GPU memory for JAX. | ||
| tensorflow-datasets>=4.0.1 | ||
| tensorflow-probability>=0.11.1 | ||
| # tensorflow-text>=2.9.0 | ||
| ... | ... |