
modify readme
Showing
docker/Dockerfile
0 → 100644
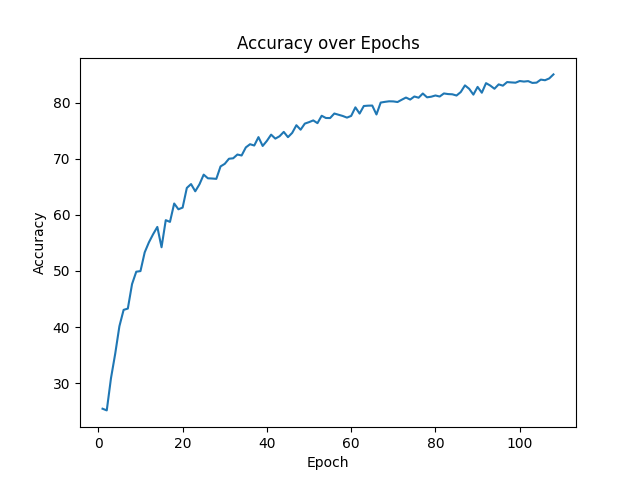
img/accuracy.png
0 → 100644
{kind=link}
24.1 KB
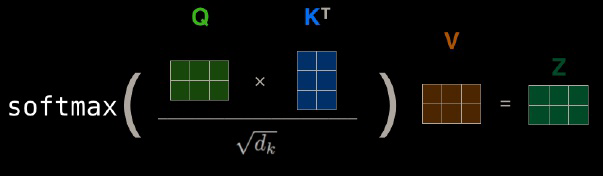
img/attention.png
0 → 100644
{kind=link}
28.4 KB
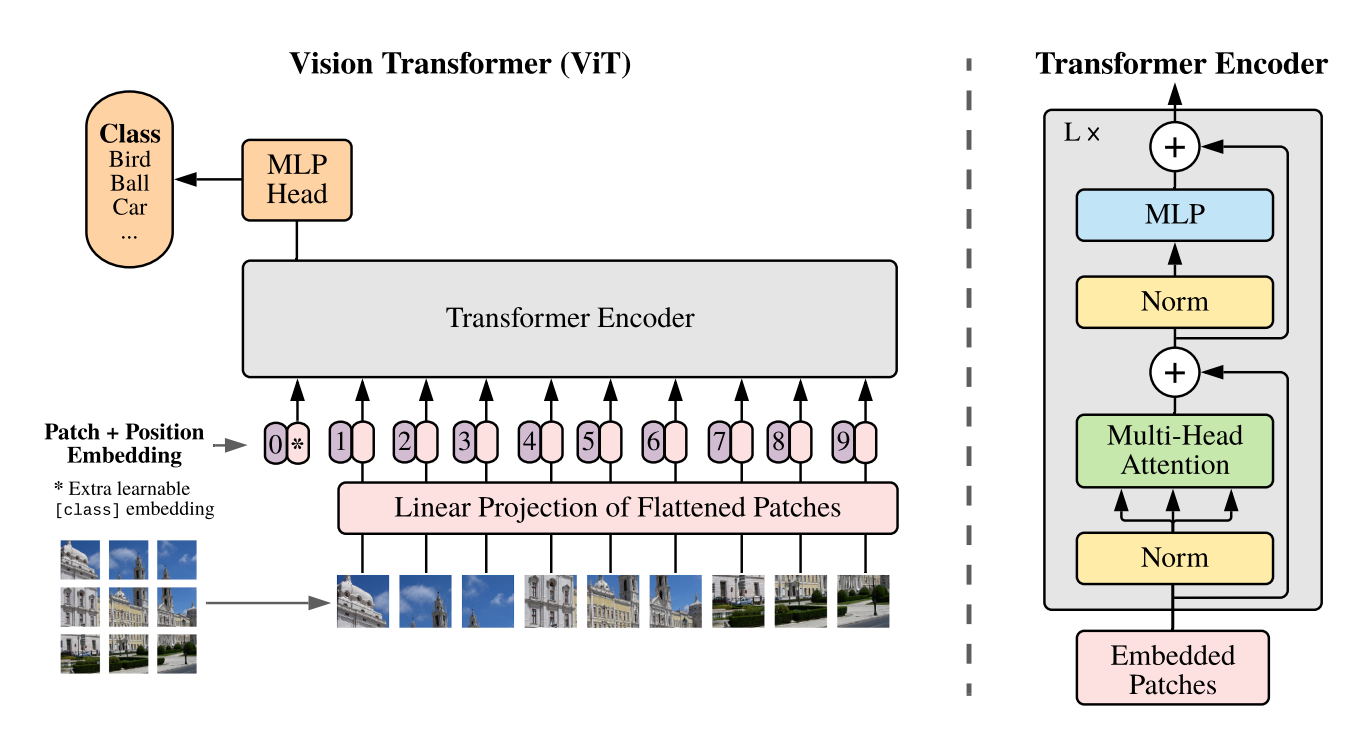
img/vit.png
0 → 100644
{kind=link}
223 KB
24.1 KB
28.4 KB
223 KB