
"Initial commit"
parents
Showing
.gitignore
0 → 100644
Figures/1p_abs_generated.wav
0 → 100644
File added
{kind=link}

301 KB
Figures/MOS-preference.png
0 → 100644
{kind=link}
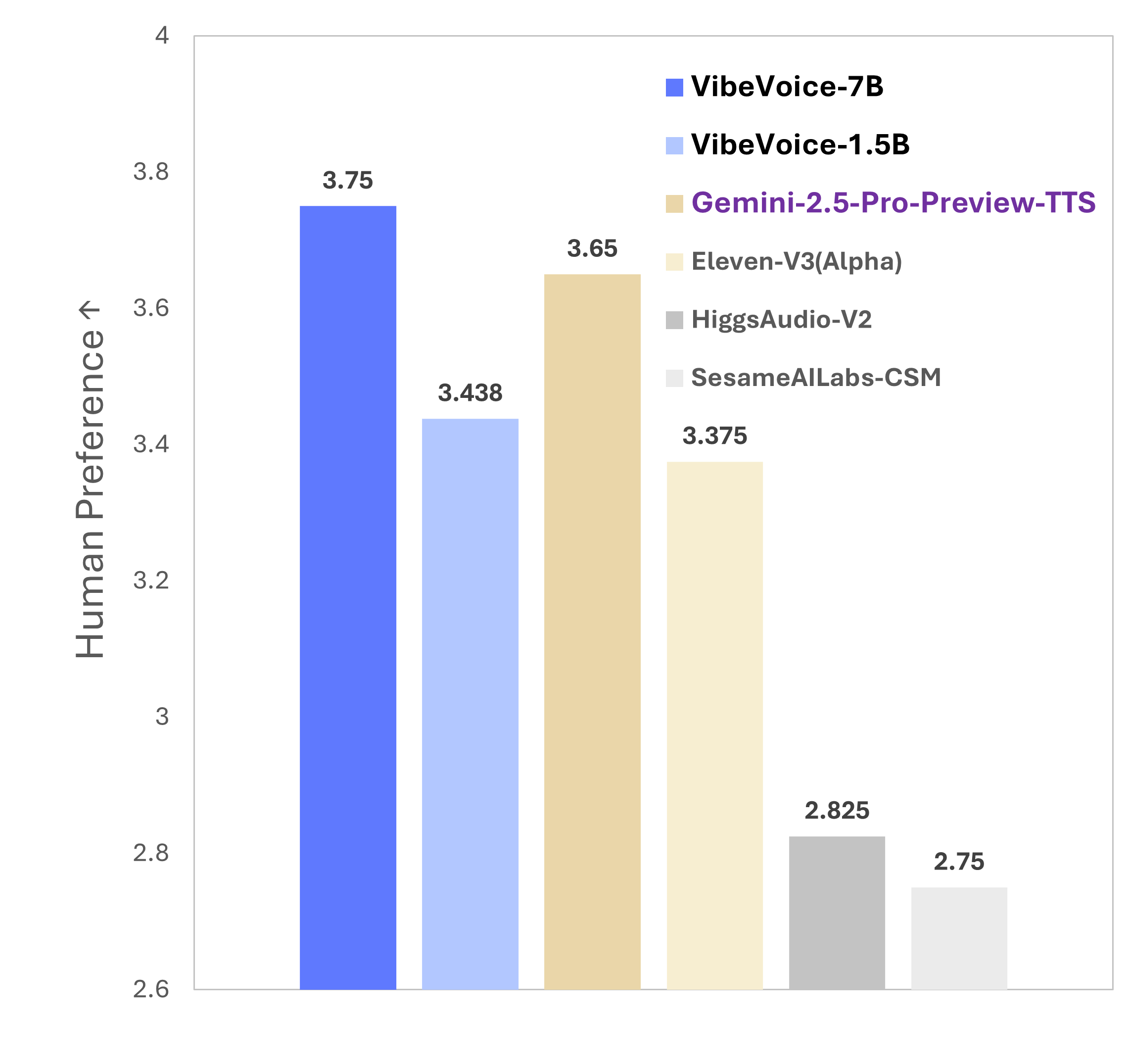
65.6 KB
Figures/VibeVoice.jpg
0 → 100644
{kind=link}

334 KB
Figures/VibeVoice_logo.png
0 → 100644
{kind=link}
1.35 MB
{kind=link}
311 KB
Figures/arch.png
0 → 100644
{kind=link}
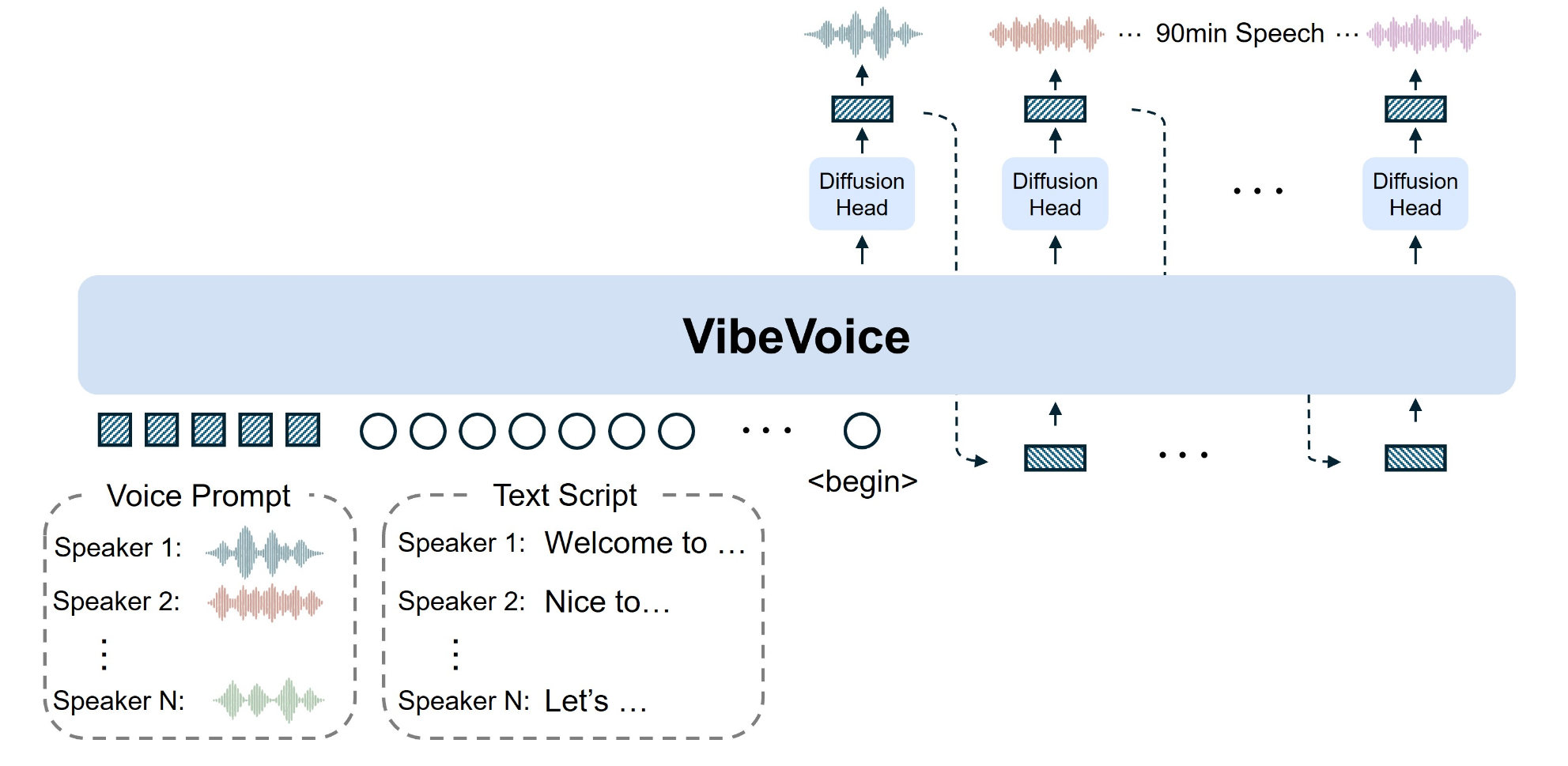
401 KB
Figures/results.png
0 → 100644
{kind=link}
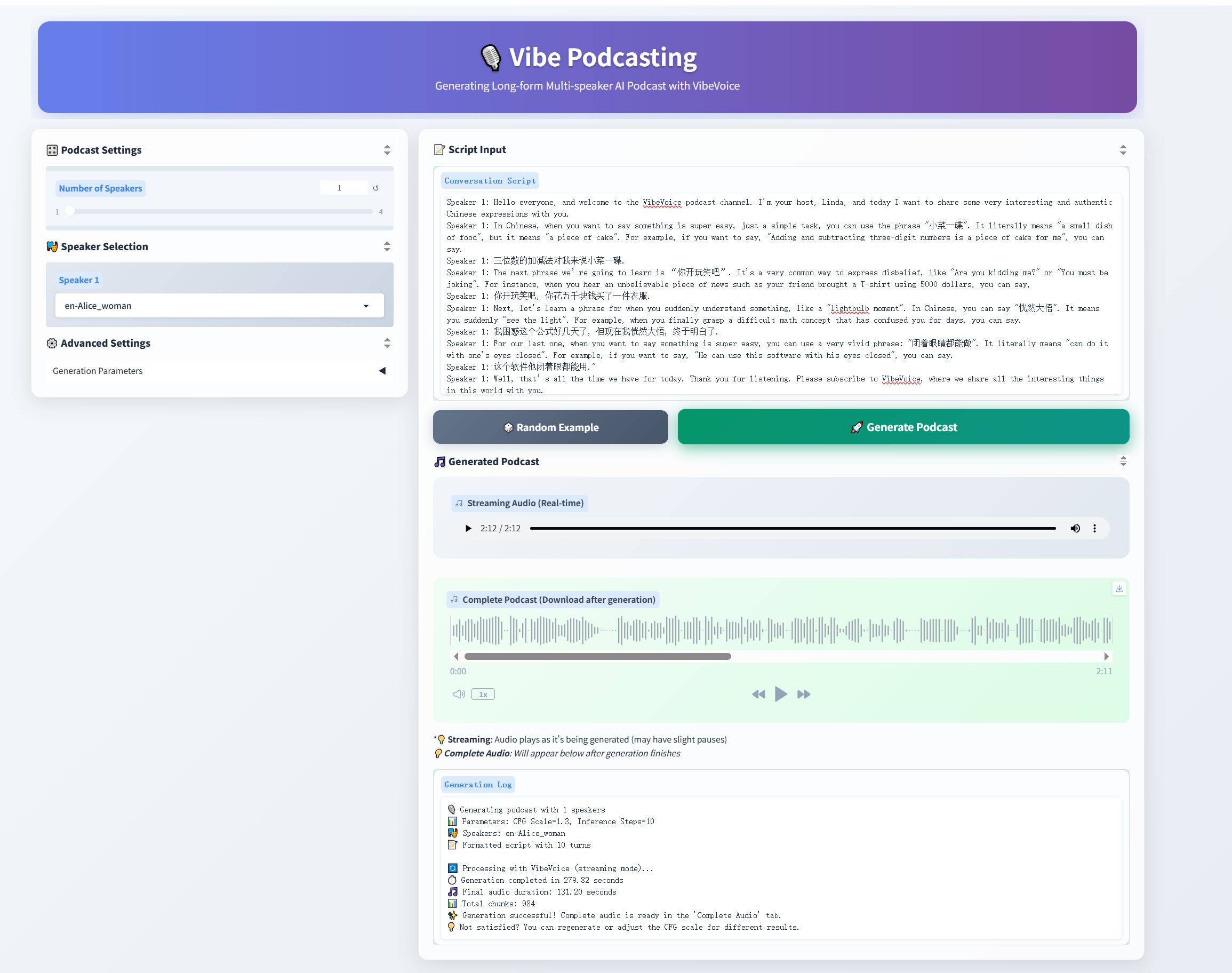
628 KB
LICENSE
0 → 100644
README.md
0 → 100644
README_ori.md
0 → 100644
SECURITY.md
0 → 100644
demo/VibeVoice_colab.ipynb
0 → 100644
demo/gradio_demo.py
0 → 100644
This diff is collapsed.
demo/inference_from_file.py
0 → 100644