
vgg16-qat
Showing
.gitignore
0 → 100644
README.md
0 → 100644
evaluate.py
0 → 100644
main.py
0 → 100644
model.properties
0 → 100644
models.py
0 → 100644
readme_imgs/image-1.png
0 → 100644
{kind=link}
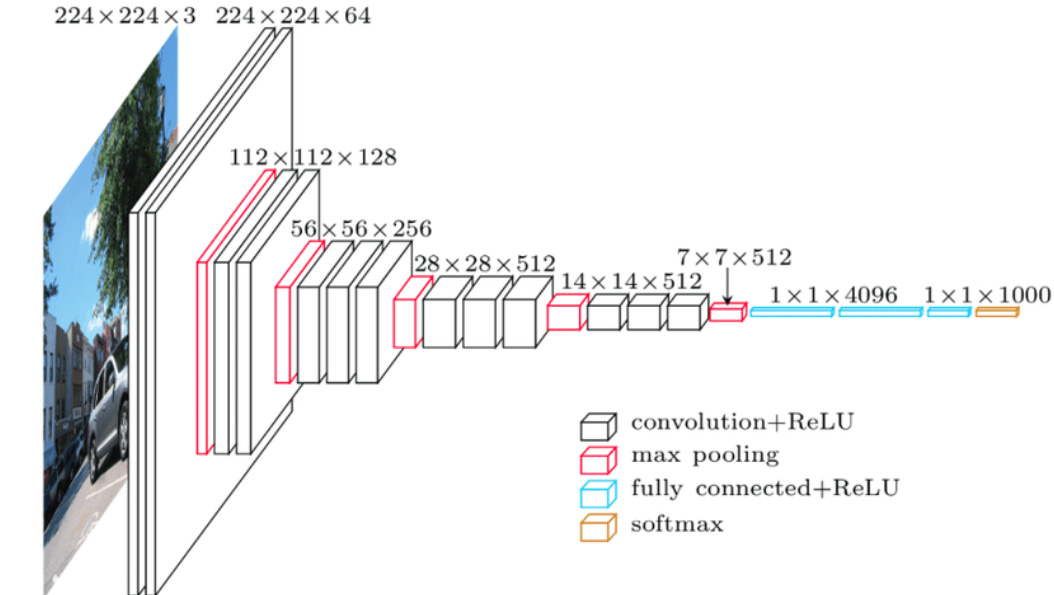
288 KB
readme_imgs/image-2.png
0 → 100644
{kind=link}
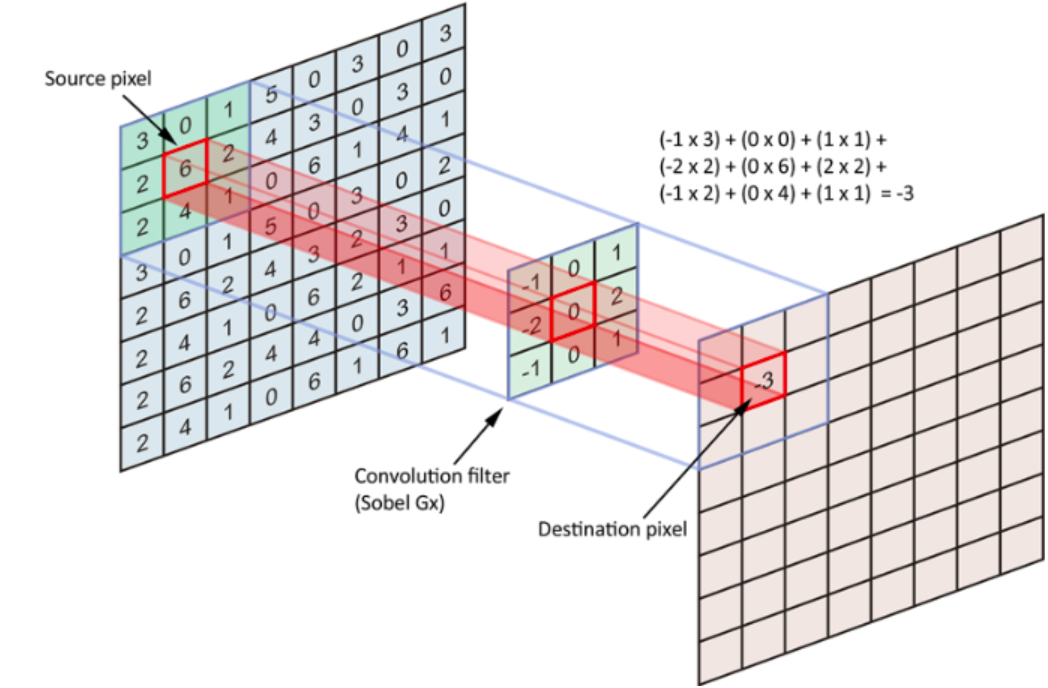
359 KB
readme_imgs/image-3.png
0 → 100644
{kind=link}

551 KB
requirements.txt
0 → 100755
| absl-py==2.0.0 | |||
| aiohttp==3.9.3 | |||
| aiosignal==1.3.1 | |||
| anyio==4.2.0 | |||
| appdirs==1.4.4 | |||
| argon2-cffi==23.1.0 | |||
| argon2-cffi-bindings==21.2.0 | |||
| arrow==1.3.0 | |||
| asttokens==2.4.1 | |||
| async-lru==2.0.4 | |||
| async-timeout==4.0.3 | |||
| attrs==23.2.0 | |||
| Babel==2.14.0 | |||
| beautifulsoup4==4.12.3 | |||
| bleach==6.1.0 | |||
| certifi==2023.11.17 | |||
| cffi==1.16.0 | |||
| charset-normalizer==3.3.2 | |||
| cmake==3.28.1 | |||
| coloredlogs==15.0.1 | |||
| comm==0.2.1 | |||
| contourpy==1.2.0 | |||
| cycler==0.12.1 | |||
| debugpy==1.8.0 | |||
| decorator==5.1.1 | |||
| defusedxml==0.7.1 | |||
| exceptiongroup==1.2.0 | |||
| executing==2.0.1 | |||
| fastjsonschema==2.19.1 | |||
| filelock==3.13.1 | |||
| flatbuffers==23.5.26 | |||
| fonttools==4.47.2 | |||
| fqdn==1.5.1 | |||
| frozenlist==1.4.1 | |||
| fsspec==2024.2.0 | |||
| gitdb==4.0.11 | |||
| GitPython==3.1.41 | |||
| hub-sdk==0.0.3 | |||
| humanfriendly==10.0 | |||
| idna==3.6 | |||
| importlib-metadata==7.0.1 | |||
| importlib-resources==6.1.1 | |||
| ipykernel==6.29.0 | |||
| ipython==8.18.1 | |||
| isoduration==20.11.0 | |||
| jedi==0.19.1 | |||
| Jinja2==3.1.3 | |||
| json5==0.9.14 | |||
| jsonpointer==2.4 | |||
| jsonschema==4.21.1 | |||
| jsonschema-specifications==2023.12.1 | |||
| jupyter-events==0.9.0 | |||
| jupyter-lsp==2.2.2 | |||
| jupyter_client==8.6.0 | |||
| jupyter_core==5.7.1 | |||
| jupyter_server==2.12.5 | |||
| jupyter_server_terminals==0.5.1 | |||
| jupyterlab==4.0.11 | |||
| jupyterlab_pygments==0.3.0 | |||
| jupyterlab_server==2.25.2 | |||
| kiwisolver==1.4.5 | |||
| lit==17.0.6 | |||
| Mako==1.3.2 | |||
| MarkupSafe==2.1.3 | |||
| matplotlib==3.8.2 | |||
| matplotlib-inline==0.1.6 | |||
| mistune==3.0.2 | |||
| mpmath==1.3.0 | |||
| multidict==6.0.5 | |||
| nbclient==0.9.0 | |||
| nbconvert==7.14.2 | |||
| nbformat==5.9.2 | |||
| nest-asyncio==1.6.0 | |||
| networkx==3.2.1 | |||
| notebook==7.0.7 | |||
| notebook_shim==0.2.3 | |||
| numpy==1.23.2 | |||
| nvidia-cublas-cu11==11.10.3.66 | |||
| # nvidia-cublas-cu12==12.3.4.1 | |||
| nvidia-cuda-cupti-cu11==11.7.101 | |||
| nvidia-cuda-nvrtc-cu11==11.7.99 | |||
| # nvidia-cuda-nvrtc-cu12==12.3.107 | |||
| nvidia-cuda-runtime-cu11==11.7.99 | |||
| # nvidia-cuda-runtime-cu12==12.3.101 | |||
| nvidia-cudnn-cu11==8.5.0.96 | |||
| # nvidia-cudnn-cu12==8.9.7.29 | |||
| nvidia-cufft-cu11==10.9.0.58 | |||
| nvidia-curand-cu11==10.2.10.91 | |||
| nvidia-cusolver-cu11==11.4.0.1 | |||
| nvidia-cusparse-cu11==11.7.4.91 | |||
| nvidia-nccl-cu11==2.14.3 | |||
| nvidia-nvtx-cu11==11.7.91 | |||
| onnx==1.15.0 | |||
| onnx-graphsurgeon==0.3.27 | |||
| onnxoptimizer==0.3.2 | |||
| onnxruntime-gpu==1.17.1 | |||
| opencv-python==4.9.0.80 | |||
| opencv-python-headless==4.9.0.80 | |||
| overrides==7.6.0 | |||
| packaging==23.2 | |||
| pandas==2.1.4 | |||
| pandocfilters==1.5.1 | |||
| parso==0.8.3 | |||
| pexpect==4.9.0 | |||
| pillow==10.2.0 | |||
| platformdirs==4.1.0 | |||
| prettytable==3.9.0 | |||
| prometheus-client==0.19.0 | |||
| prompt-toolkit==3.0.43 | |||
| protobuf==4.25.2 | |||
| psutil==5.9.7 | |||
| ptyprocess==0.7.0 | |||
| pure-eval==0.2.2 | |||
| py-cpuinfo==9.0.0 | |||
| pycocotools==2.0.7 | |||
| pycparser==2.21 | |||
| pycuda==2020.1 | |||
| Pygments==2.17.2 | |||
| pyparsing==3.1.1 | |||
| python-dateutil==2.8.2 | |||
| python-json-logger==2.0.7 | |||
| pytools==2023.1.1 | |||
| pytorch-lightning==2.2.0.post0 | |||
| pytorch-quantization==2.1.3 | |||
| pytz==2023.3.post1 | |||
| PyYAML==6.0.1 | |||
| pyzmq==25.1.2 | |||
| referencing==0.32.1 | |||
| requests==2.31.0 | |||
| rfc3339-validator==0.1.4 | |||
| rfc3986-validator==0.1.1 | |||
| rpds-py==0.17.1 | |||
| scipy==1.11.4 | |||
| seaborn==0.13.1 | |||
| Send2Trash==1.8.2 | |||
| six==1.16.0 | |||
| smmap==5.0.1 | |||
| sniffio==1.3.0 | |||
| soupsieve==2.5 | |||
| sphinx-glpi-theme==0.5 | |||
| stack-data==0.6.3 | |||
| sympy==1.12 | |||
| # tensorrt @ file:///home/qat/TensorRT-8.5.3.1/python/tensorrt-8.5.3.1-cp39-none-linux_x86_64.whl#sha256=ee25152809c09fd22057681ff24dfcf2dc2a1e7aad50dcb2658e0a1c0b32e768 | |||
| terminado==0.18.0 | |||
| thop==0.1.1.post2209072238 | |||
| tinycss2==1.2.1 | |||
| tomli==2.0.1 | |||
| torch==2.0.1 | |||
| torchaudio==2.0.2 | |||
| torchmetrics==1.3.1 | |||
| torchvision==0.15.2 | |||
| tornado==6.4 | |||
| tqdm==4.66.1 | |||
| traitlets==5.14.1 | |||
| triton==2.0.0 | |||
| types-python-dateutil==2.8.19.20240106 | |||
| typing_extensions==4.9.0 | |||
| tzdata==2023.4 | |||
| ultralytics==8.1.1 | |||
| uri-template==1.3.0 | |||
| urllib3==2.1.0 | |||
| wcwidth==0.2.13 | |||
| webcolors==1.13 | |||
| webencodings==0.5.1 | |||
| websocket-client==1.7.0 | |||
| yarl==1.9.4 | |||
| zipp==3.17.0 |
utils/__init__.py
0 → 100644
utils/calibrate.py
0 → 100644
utils/data.py
0 → 100644
utils/trt.py
0 → 100644