
Initial commit
Showing
.gitignore
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_origin.md
0 → 100644
demo_sample.ipynb
0 → 100644
dist.py
0 → 100644
doc/VAR.PNG
0 → 100644
{kind=link}
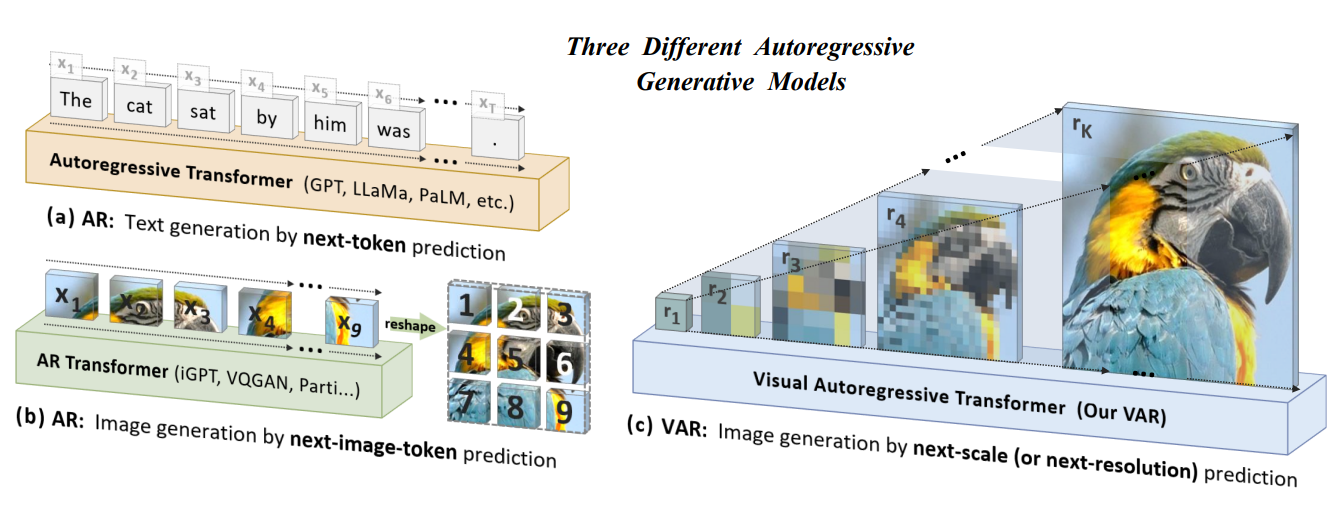
513 KB
doc/VAR_detail.PNG
0 → 100644
{kind=link}
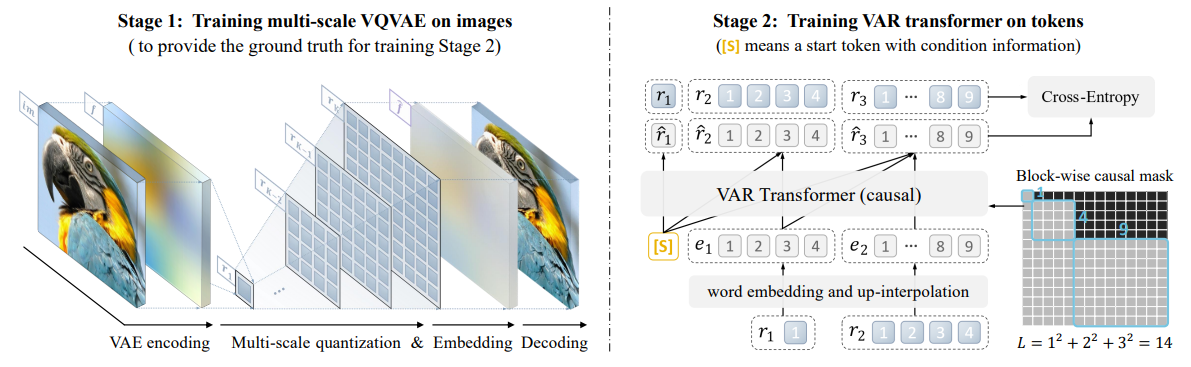
303 KB
doc/imagenet_classes.txt
0 → 100644
doc/imagenet_synsets.txt
0 → 100644
This diff is collapsed.
doc/inference.png
0 → 100644
{kind=link}

908 KB
icon.png
0 → 100644
{kind=link}
64.5 KB
model.properties
0 → 100644
models/__init__.py
0 → 100644
models/basic_vae.py
0 → 100644
models/basic_var.py
0 → 100644
models/helpers.py
0 → 100644
models/quant.py
0 → 100644
models/var.py
0 → 100644
models/vqvae.py
0 → 100644