
update
parents
Showing
LICENSE
0 → 100644
MFD/README.md
0 → 100644

547 KB

1.12 MB
309 KB

512 KB
MFD/demo.py
0 → 100644
README-ja.md
0 → 100644
README-zh_CN.md
0 → 100644
README.md
0 → 100644
asset/.DS_Store
0 → 100644
File added
96.1 KB
6.04 KB
asset/papers/fig1_bleu.jpg
0 → 100644
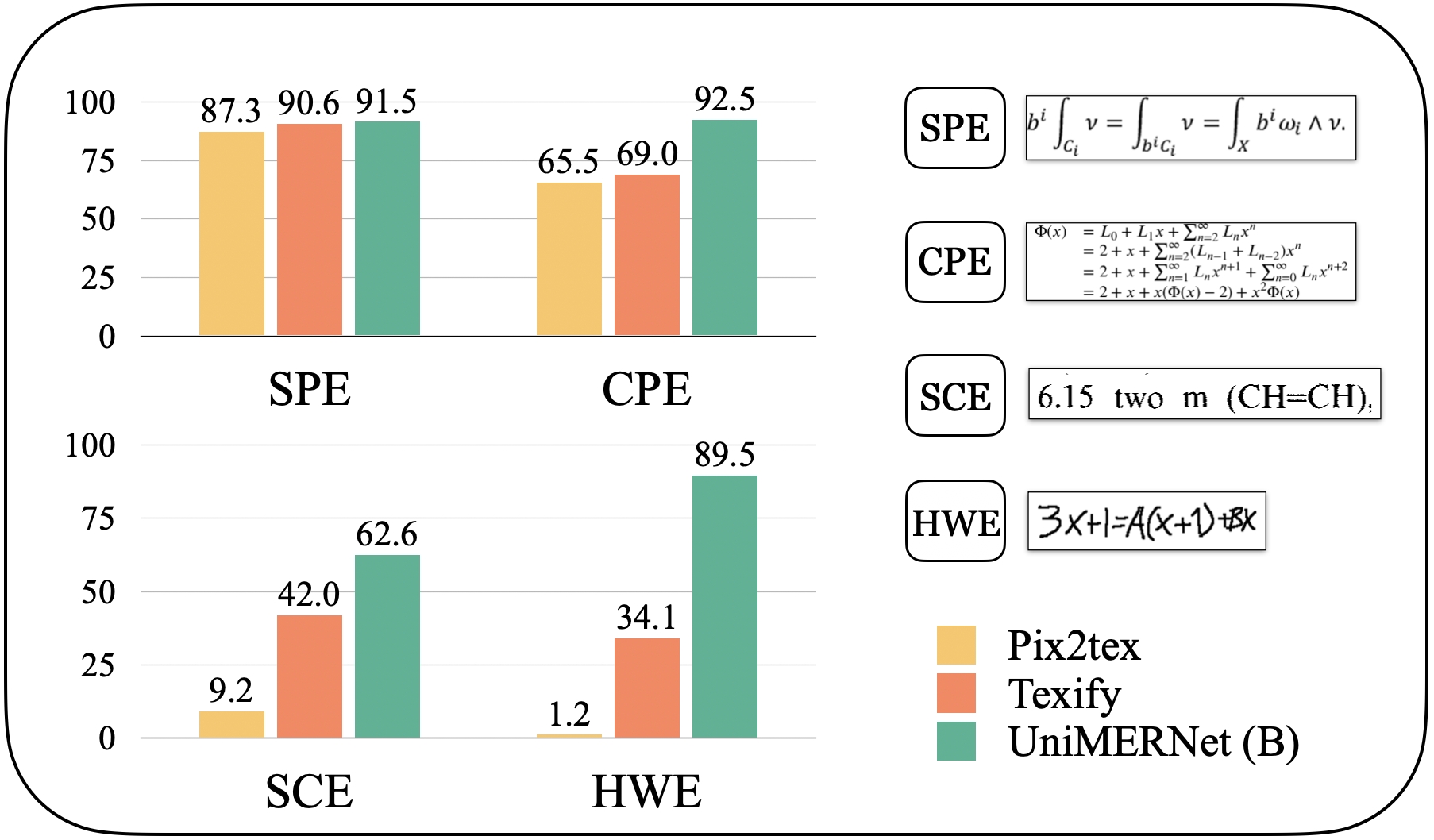
304 KB
asset/papers/fig2_cdm.jpg
0 → 100644
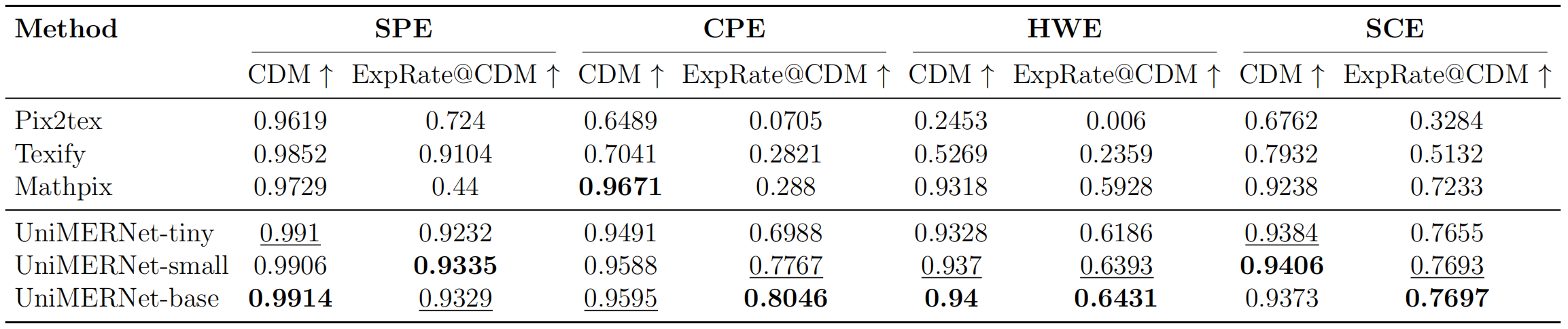
136 KB
asset/papers/fig5_demo.png
0 → 100644
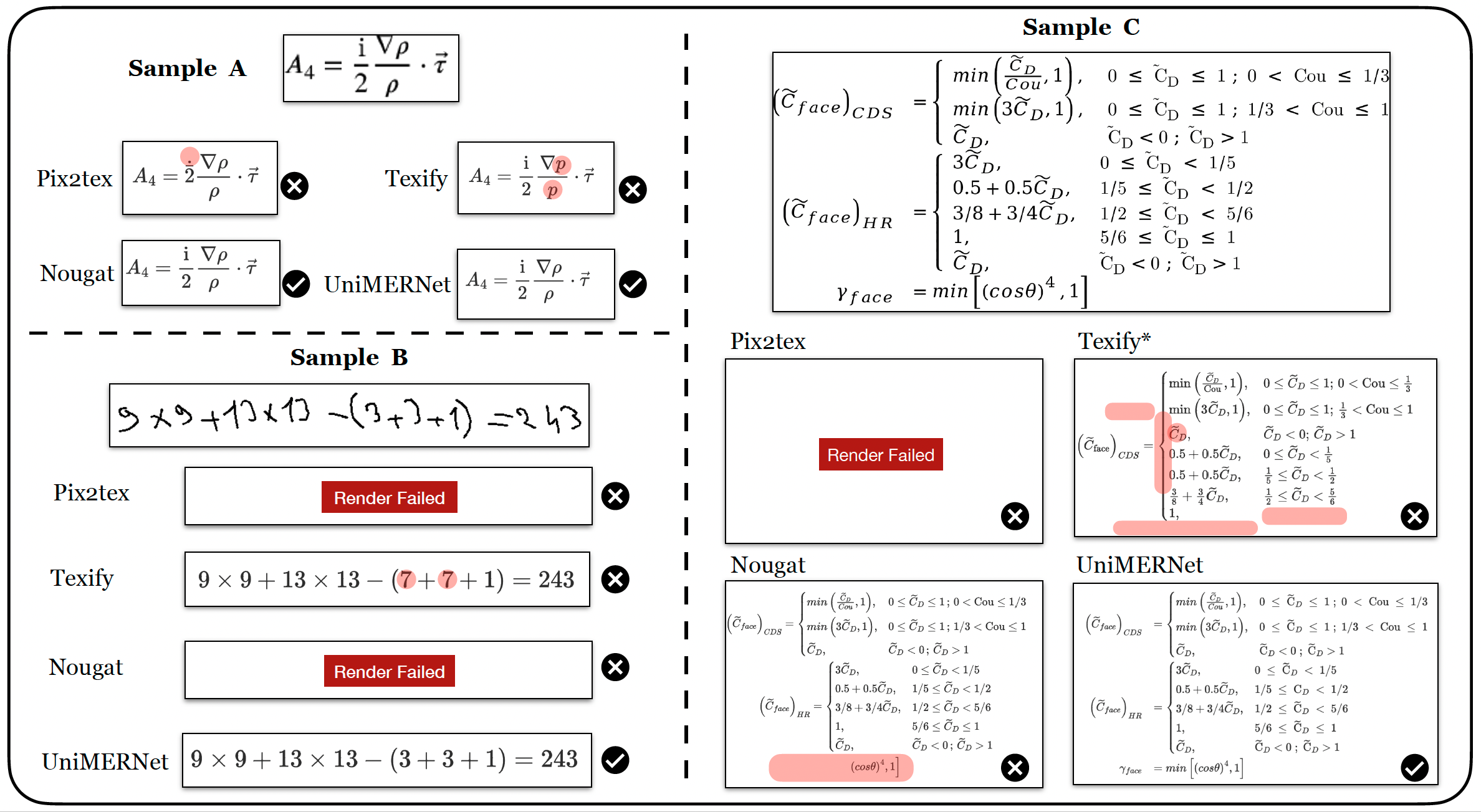
1.12 MB
File added
7.11 KB
12.8 KB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}