
提交Unet模型python和C++代码示例
Showing
3rdParty/InstallRBuild.sh
0 → 100644
File added
File added
File added
File added
File added
File added
CMakeLists.txt
0 → 100644
Doc/Images/Unet_01.png
0 → 100644
{kind=link}
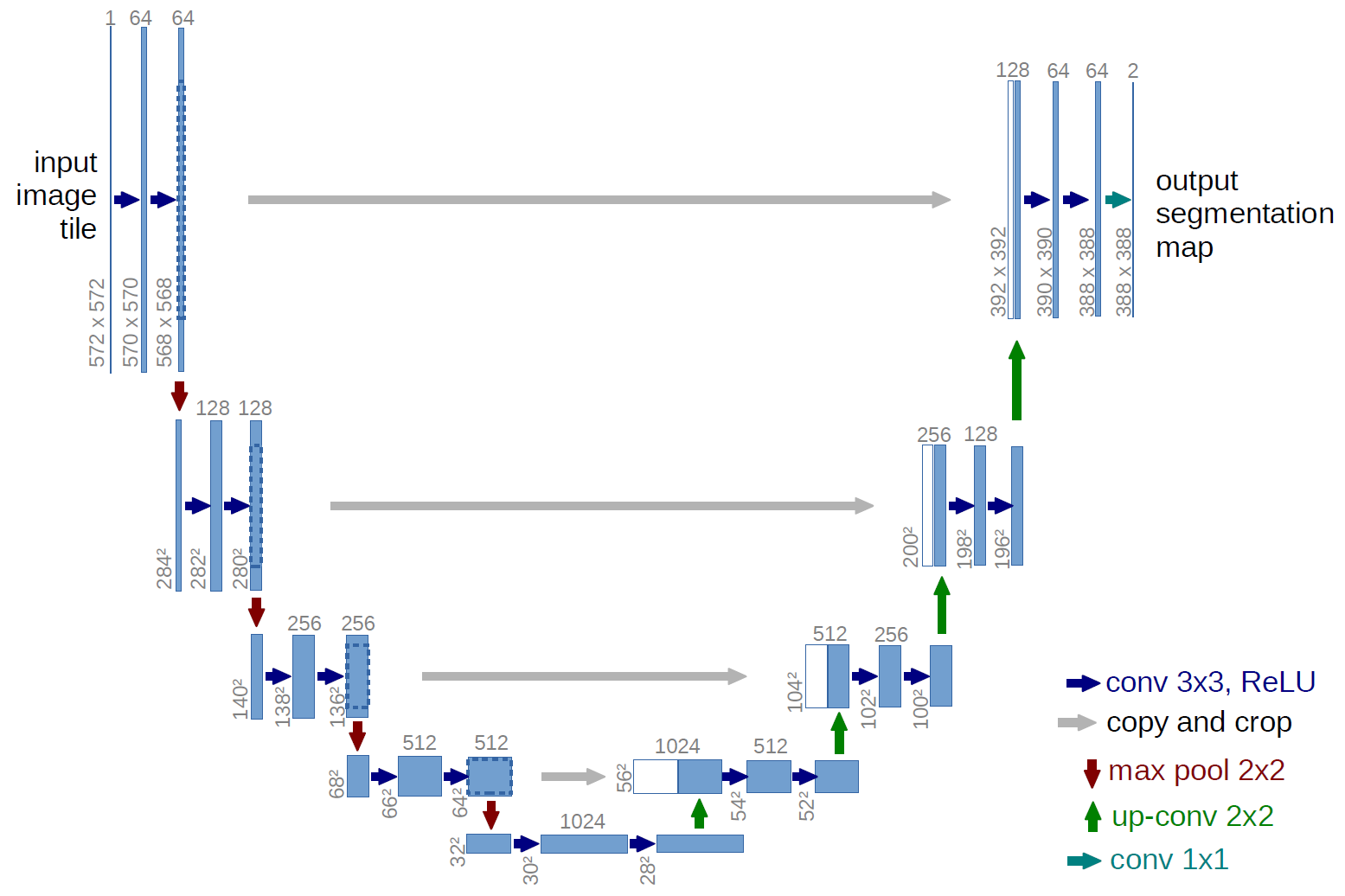
101 KB
Doc/Images/Unet_02.jpg
0 → 100644
{kind=link}

17.2 KB
Doc/Images/Unet_03.jpg
0 → 100644
{kind=link}

17.2 KB
Doc/Tutorial_Cpp/Unet.md
0 → 100644
Doc/Tutorial_Python/Unet.md
0 → 100644
Python/Segmentation/Unet.py
0 → 100644
Resource/Configuration.xml
0 → 100644
Resource/Images/car1.jpeg
0 → 100644
{kind=link}

912 KB
File added