
Initial commit
Showing
.gitattributes
0 → 100644
.gitignore
0 → 100644
Contributors.md
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
docs/T5_structure.png
0 → 100644
{kind=link}
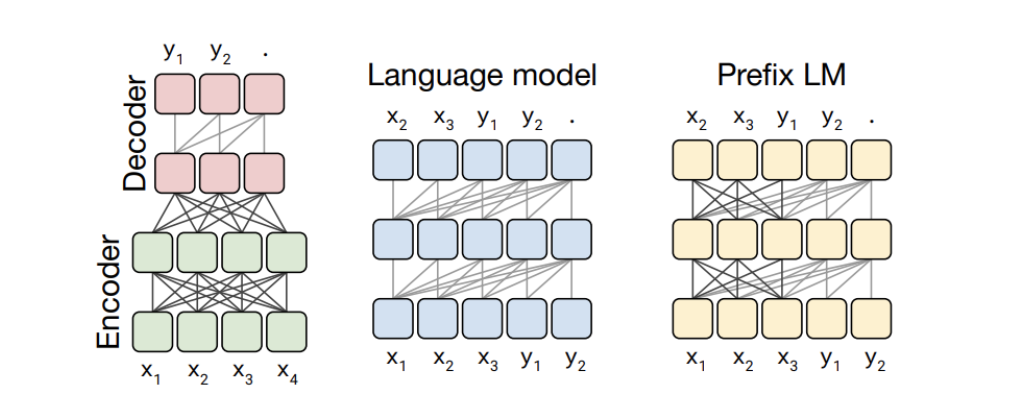
118 KB
docs/T5_task.png
0 → 100644
{kind=link}
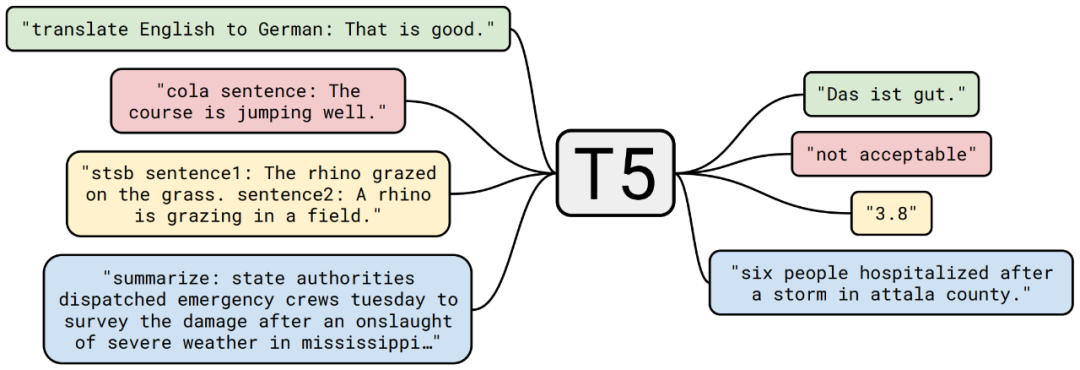
142 KB
docs/equation1.png
0 → 100644
{kind=link}
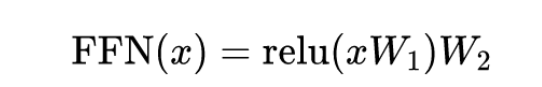
9.63 KB
docs/euqation2.png
0 → 100644
{kind=link}
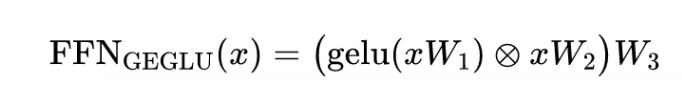
12.5 KB
docs/result.png
0 → 100644
{kind=link}

136 KB
docs/t5transformer.png
0 → 100644
{kind=link}
79 KB
model.properties
0 → 100644
multi_dcu_test.py
0 → 100644
multi_dcu_train.py
0 → 100644
requirements.txt
0 → 100644
| numpy>=1.25.0 | |||
| tqdm>=4.65.0 | |||
| peft>=0.8.0 | |||
| transformers>=4.28.1 | |||
| accelerate | |||
| loralib | |||
| evaluate | |||
| tqdm | |||
| datasets | |||
| torch | |||
| scikit-learn | |||
| protobuf>=3.20 | |||
| sentencepiece | |||
| sacrebleu | |||
| rouge | |||
| \ No newline at end of file |
umt5_base/CONTRIBUTING.md
0 → 100644
umt5_base/LICENSE
0 → 100644
umt5_base/README.md
0 → 100644