
uitars
Showing
data/test_messages_07.json
0 → 100644
data/training_example.json
0 → 100644
{kind=link}
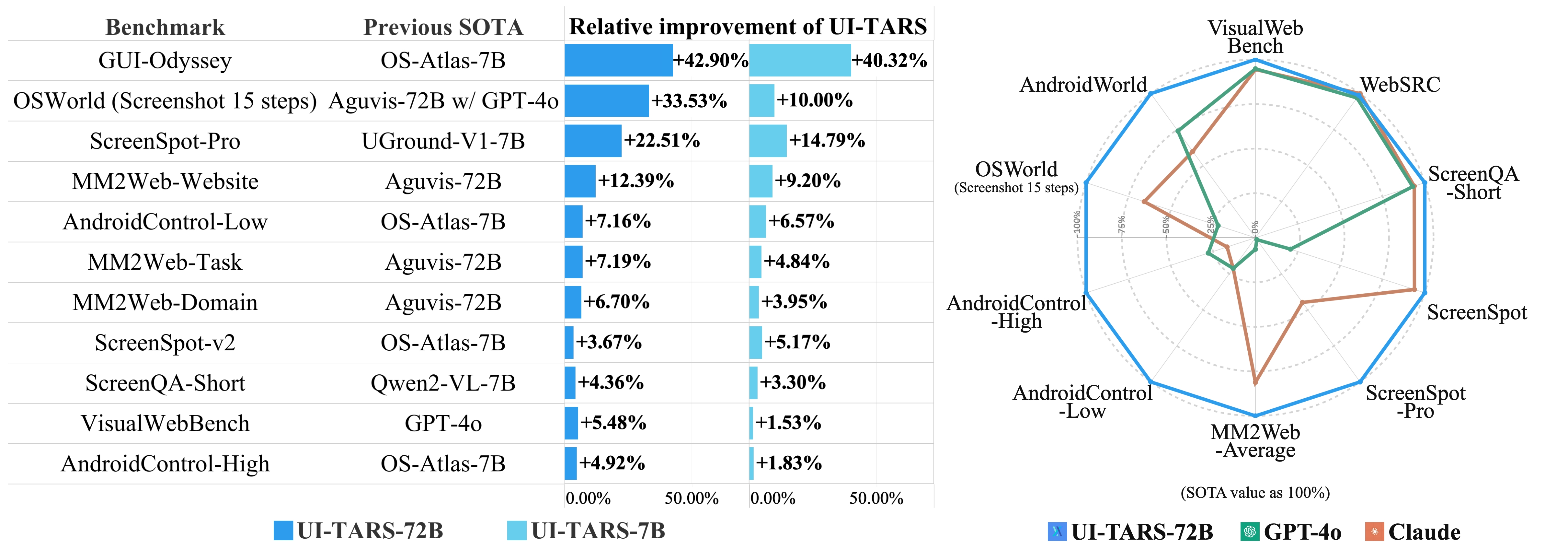
1.29 MB
figures/UI-TARS.png
0 → 100644
{kind=link}
647 KB
figures/icon.png
0 → 100644
{kind=link}
82.9 KB
figures/writer.png
0 → 100644
{kind=link}

123 KB
inference.py
0 → 100644
inference_15.py
0 → 100644
model.properties
0 → 100644
prompts.py
0 → 100644
readme_imgs/alg.png
0 → 100644
{kind=link}
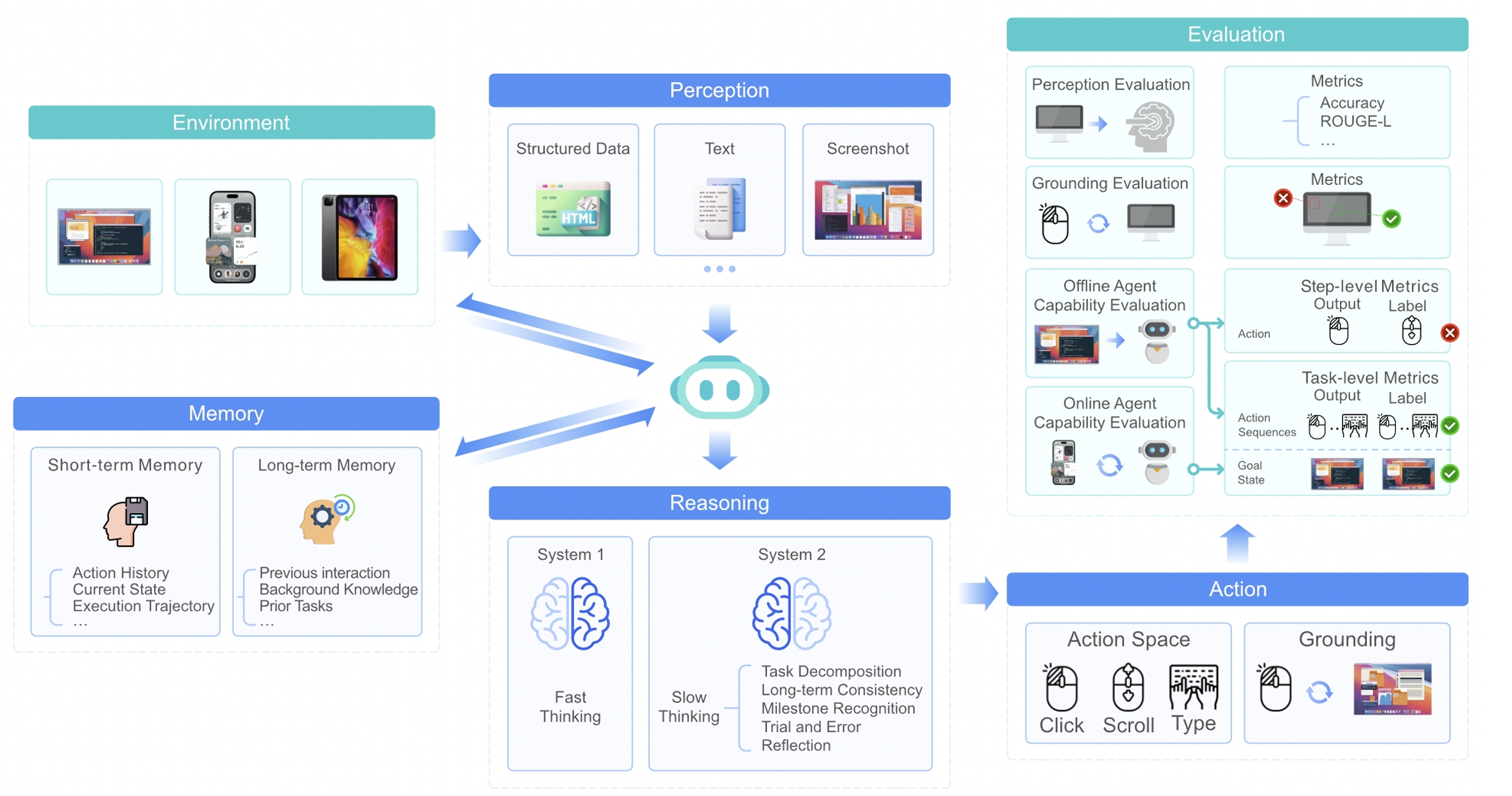
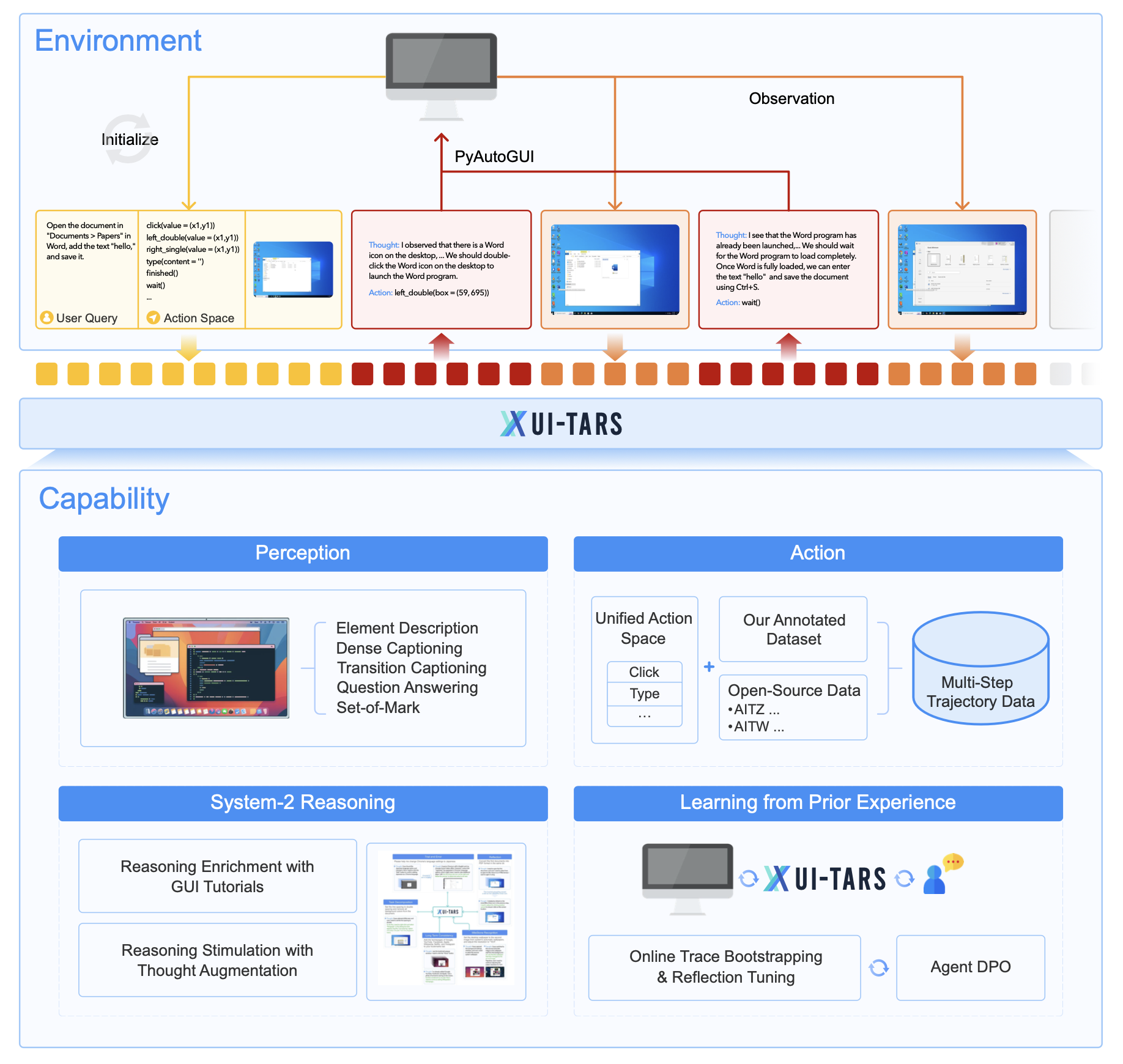
1.47 MB
readme_imgs/arch.png
0 → 100644
{kind=link}
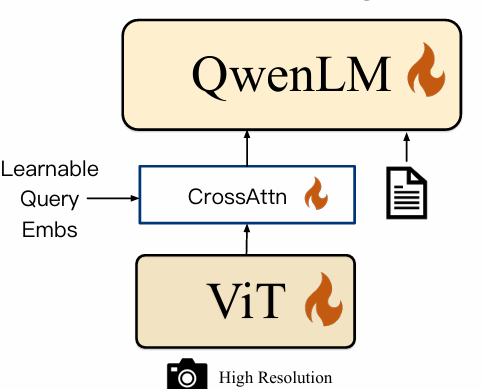
30.8 KB
readme_imgs/result.png
0 → 100644
{kind=link}

25.6 KB
readme_imgs/result1.png
0 → 100644
{kind=link}
1.02 MB
test.py
0 → 100644
utils/coordinate_extract.py
0 → 100644
utils/generate_new_data.py
0 → 100644
utils/plot_image.py
0 → 100644