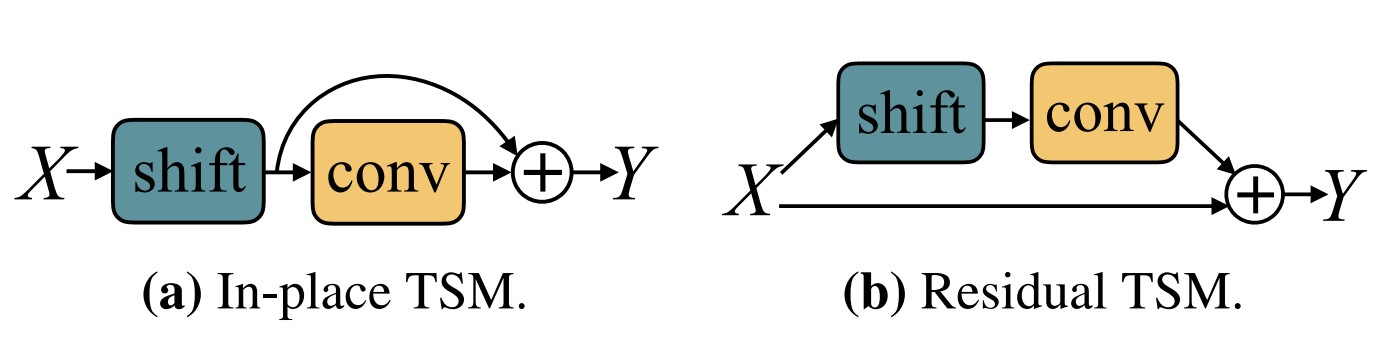Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
TSM_pytorch
Commits
fe2ea1ea
Commit
fe2ea1ea
authored
Nov 20, 2023
by
Sugon_ldc
Browse files
modify readme
parent
3bbeddb7
Changes
9
Hide whitespace changes
Inline
Side-by-side
Showing
9 changed files
with
156 additions
and
183 deletions
+156
-183
README.md
README.md
+142
-81
TSM_model.png
TSM_model.png
+0
-0
TSM_model2.png
TSM_model2.png
+0
-0
docker/Dockerfile
docker/Dockerfile
+2
-28
docker/serve/Dockerfile
docker/serve/Dockerfile
+0
-51
docker/serve/config.properties
docker/serve/config.properties
+0
-5
docker/serve/entrypoint.sh
docker/serve/entrypoint.sh
+0
-12
model.properties
model.properties
+8
-6
train_single.sh
train_single.sh
+4
-0
No files found.
README.md
View file @
fe2ea1ea
# TSM_PyTorch算力测试
# 算法名简写(英文简写大写)
## 论文
## 1.模型介绍
`TSM: Temporal Shift Module for Efficient Video Understanding`
TSM(Temporal Shift Module)是一种用于视频分类的模型,它使用时间平移操作将视频中的不同时间段进行分离,然后使用二维卷积神经网络对这些时间段进行分类。TSM模型采用了时间平移和空间卷积两种模块来实现视频分类。
-
[
TSM: Temporal Shift Module for Efficient Video Understanding
](
https://openaccess.thecvf.com/content_ICCV_2019/html/Lin_TSM_Temporal_Shift_Module_for_Efficient_Video_Understanding_ICCV_2019_paper.html
)
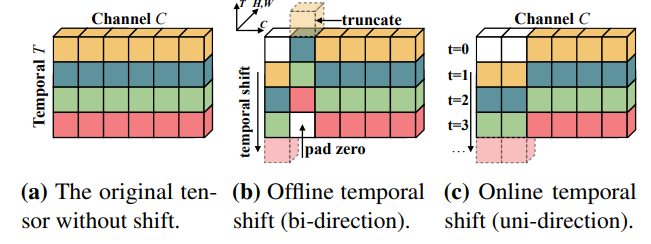
## 模型结构
在时间平移模块中,TSM模型通过将视频的每个时间片段进行平移来实现时间分离。这样,每个时间片段都可以被独立地处理。平移操作通过将视频分成多个时间段,并对这些时间段进行随机平移和拼接而实现。
TSM模型的结构由一个时间偏移模块和一个分类器组成,其中时间偏移模块通过将输入的视频特征序列进行平移来利用不同时间偏移版本的信息,而分类器则用于对经过时间偏移的特征进行分类。
在空间卷积模块中,TSM模型使用了二维卷积神经网络对每个时间片段进行分类。这样,模型可以学习到每个时间片段中的空间特征,并将这些特征用于分类。

TSM模型在视频分类任务上取得了很好的效果,特别是在大规模视频数据集上。
## 算法原理
## 2.模型结构
TSM模型通过在时间维度上应用偏移操作,将输入的视频特征序列进行平移,从而利用时间信息的不同偏移版本来增强模型对视频动态变化的感知能力。
TSM(Temporal Shift Module)模型结构主要由时间平移模块和二维卷积神经网络组成。

时间平移模块使用时间平移操作将视频中的不同时间段进行分离。具体来说,时间平移模块将视频的每个时间片段划分为多个组,然后对每个组进行随机平移和拼接,以实现时间分离。这样,每个时间片段都可以被独立地处理,从而提高了模型的效率和准确率。
## 环境配置
二维卷积神经网络用于对每个时间片段进行分类。具体来说,TSM模型使用了一系列的卷积层、池化层和批归一化层来提取每个时间片段中的空间特征,并将这些特征用于分类。TSM模型中的卷积层通常采用3x3或5x5大小的卷积核,以捕捉不同尺度的空间特征。此外,TSM模型还使用了残差连接和注意力机制等技术来提高模型的效率和准确率。
### Docker(方法一)
此处提供
[
光源
](
https://www.sourcefind.cn/#/service-details
)
拉取docker镜像的地址与使用步骤
总体来说,TSM模型结构是一个深度卷积神经网络,它使用时间平移操作将视频中的不同时间段进行分离,并使用二维卷积神经网络对每个时间片段进行分类。这种结构能够有效地提高模型的效率和准确率,在大规模视频分类任务中取得了很好的效果。
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.10.0-centos7.6-dtk-22.10-py38-latest
docker run -it -v /path/your_code_data/:/path/your_code_data/ --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
## 3.数据集
```
### Dockerfile(方法二)
使用Something-Something V2数据集,Something-Something V2是一个大规模的视频动作识别数据集,由纽约大学、谷歌、MIT等机构联合发布。该数据集包含220,847个视频剪辑,每个视频剪辑由一系列手势动作组成,这些手势动作可以是简单的动作,例如“拍手”、“摆手”等,也可以是复杂的动作,例如“穿衣服”、“打扫卫生”等。每个动作剪辑的平均长度为2.75秒,总时长为600小时,这些视频剪辑都是在真实场景下拍摄的,包括不同的光照、背景和物体等。
此处提供dockerfile的使用方法
```
Something-Something V2数据集是一个挑战性的数据集,需要模型具备对复杂场景下的手势动作进行准确分类的能力。该数据集可以用于视频动作识别、行为分析、视频检索等任务的研究和评估。
cd ./docker
docker build --no-cache -t yolov5:6.0 .
## 4.训练
docker run -it -v /path/your_code_data/:/path/your_code_data/ --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
```
### 环境配置
### Anaconda(方法三)
此处提供本地配置、编译的详细步骤,例如:
提供光源拉取的训练镜像
关于本项目DCU显卡所需的特殊深度学习库可从
[
光合
](
https://developer.hpccube.com/tool/
)
开发者社区下载安装。
```
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.10.0-centos7.6-dtk-22.10-py38-latest
DTK驱动:dtk22.10
```
python:python3.8
torch:1.10
### 数据预处理
torchvision:0.10
mmcv-full:1.6.1+gitdebbc80.dtk2210
在/workspace/mmaction2目录下创建data子目录,进入data目录,创建软链接指向数据集实际路径:
```
`Tips:以上dtk驱动、python、paddle等DCU相关工具版本需要严格一一对应`
```
ln -s /dataset/ sthv2
## 数据集
```
`something v2`
使用如下指令进行解压
-
百度网盘:
```
https://pan.baidu.com/s/1NCqL7JVoFZO6D131zGls-A#list/path=%2F&parentPath=%2Fsharelink3725532333-553839935448680 密码:07ka
cat 20bn-something-something-v2-?? | tar zx
```
### 数据预处理
解压完成后使用如下命令抽取RGB帧
进入工程目录后,创建data子目录,进入data目录,创建软链接指向数据集实际路径:
```
```
cd tsm_pytorch
bash extract_rgb_frames_opencv.sh
mkdir data
```
cd data
ln -s /dataset/ sthv2
```
使用如下指令进行解压
## 准确率数据
```
| 卡数 | 准确率 |
cat 20bn-something-something-v2-?? | tar zx
| :--: | :----: |
```
| 4 | 59.14% |
解压完成后使用如下命令抽取RGB帧
```
## 源码仓库及问题反馈
bash extract_rgb_frames_opencv.sh
```
http://developer.hpccube.com/codes/modelzoo/tsm_pytorch.git
预处理之后,目录结构如下:
```
## 参考
├── 20bn-something-something-v2-00
├── 20bn-something-something-v2-01
https://github.com/open-mmlab/mmaction2
├── 20bn-something-something-v2-02
├── 20bn-something-something-v2-03
https://download.openmmlab.com/mmaction/recognition/tsm/tsm_r50_1x1x8_50e_sthv2_rgb/20210816_224310.log
├── 20bn-something-something-v2-04
├── 20bn-something-something-v2-05
├── 20bn-something-something-v2-06
├── 20bn-something-something-v2-07
├── 20bn-something-something-v2-08
├── 20bn-something-something-v2-09
├── 20bn-something-something-v2-10
├── 20bn-something-something-v2-11
├── 20bn-something-something-v2-12
├── 20bn-something-something-v2-13
├── 20bn-something-something-v2-14
├── 20bn-something-something-v2-15
├── 20bn-something-something-v2-16
├── 20bn-something-something-v2-17
├── 20bn-something-something-v2-18
├── 20bn-something-something-v2-19
├── annotations
├── rawframes
├── something-something-v2-labels.json
├── something-something-v2-test.json
├── something-something-v2-train.json
├── something-something-v2-validation.json
├── sthv2_train_list_rawframes.txt
├── sthv2_val_list_rawframes.txt
└── videos
```
## 训练
一般情况下,ModelZoo上的项目提供单机训练的启动方法即可,单机多卡、单机单卡至少提供其一训练方法。
### 单机多卡
```
bash train.sh
```
### 单机单卡
```
bash train_single.sh
```
## result
测试的日志会以tsm_dcu_date.log的形式保存在工程的根目录中
### 精度
测试数据:something v2,使用的加速卡:Z100L。
根据测试结果情况填写表格:
| 卡数 | 准确率 |
| :------: | :------: |
| 4 | 59.14% |
## 应用场景
### 算法类别
`视频分析,动作识别`
### 热点应用行业
`交通,政府,家居`
## 源码仓库及问题反馈
-
http://developer.hpccube.com/codes/modelzoo/tsm_pytorch.git
## 参考资料
-
https://github.com/open-mmlab/mmaction2
TSM_model.png
0 → 100644
View file @
fe2ea1ea
48.9 KB
TSM_model2.png
0 → 100644
View file @
fe2ea1ea
59 KB
docker/Dockerfile
View file @
fe2ea1ea
ARG
PYTORCH="1.6.0"
FROM
image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.10.0-centos7.6-dtk-22.10-py38-latest
ARG
CUDA="10.1"
RUN
source
/opt/dtk/env.sh
ARG
CUDNN="7"
FROM
pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
ENV
TORCH_CUDA_ARCH_LIST="6.0 6.1 7.0+PTX"
ENV
TORCH_NVCC_FLAGS="-Xfatbin -compress-all"
ENV
CMAKE_PREFIX_PATH="$(dirname $(which conda))/../"
# To fix GPG key error when running apt-get update
RUN
apt-key adv
--fetch-keys
https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/3bf863cc.pub
RUN
apt-key adv
--fetch-keys
https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/7fa2af80.pub
RUN
apt-get update
&&
apt-get
install
-y
git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 ffmpeg
\
&&
apt-get clean
\
&&
rm
-rf
/var/lib/apt/lists/
*
# Install MMCV
RUN
pip
install
--no-cache-dir
--upgrade
pip wheel setuptools
RUN
pip
install
--no-cache-dir
mmcv-full
-f
https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/index.html
# Install MMAction2
RUN
conda clean
--all
RUN
git clone https://github.com/open-mmlab/mmaction2.git /mmaction2
WORKDIR
/mmaction2
RUN
mkdir
-p
/mmaction2/data
ENV
FORCE_CUDA="1"
RUN
pip
install
cython
--no-cache-dir
RUN
pip
install
--no-cache-dir
-e
.
docker/serve/Dockerfile
deleted
100644 → 0
View file @
3bbeddb7
ARG
PYTORCH="1.9.0"
ARG
CUDA="10.2"
ARG
CUDNN="7"
FROM
pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
ARG
MMCV="1.3.8"
ARG
MMACTION="0.24.0"
ENV
PYTHONUNBUFFERED TRUE
RUN
apt-get update
&&
\
DEBIAN_FRONTEND
=
noninteractive apt-get
install
--no-install-recommends
-y
\
ca-certificates
\
g++
\
openjdk-11-jre-headless
\
# MMDET Requirements
ffmpeg libsm6 libxext6 git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 \
libsndfile1 libturbojpeg \
&& rm -rf /var/lib/apt/lists/*
ENV
PATH="/opt/conda/bin:$PATH"
RUN
export
FORCE_CUDA
=
1
# TORCHSEVER
RUN
pip
install
torchserve torch-model-archiver
# MMLAB
ARG
PYTORCH
ARG
CUDA
RUN
[
"/bin/bash"
,
"-c"
,
"pip install mmcv-full==
${
MMCV
}
-f https://download.openmmlab.com/mmcv/dist/cu
${
CUDA
//./
}
/torch
${
PYTORCH
}
/index.html"
]
# RUN pip install mmaction2==${MMACTION}
RUN
pip
install
git+https://github.com/open-mmlab/mmaction2.git
RUN
useradd
-m
model-server
\
&&
mkdir
-p
/home/model-server/tmp
COPY
entrypoint.sh /usr/local/bin/entrypoint.sh
RUN
chmod
+x /usr/local/bin/entrypoint.sh
\
&&
chown
-R
model-server /home/model-server
COPY
config.properties /home/model-server/config.properties
RUN
mkdir
/home/model-server/model-store
&&
chown
-R
model-server /home/model-server/model-store
EXPOSE
8080 8081 8082
USER
model-server
WORKDIR
/home/model-server
ENV
TEMP=/home/model-server/tmp
ENTRYPOINT
["/usr/local/bin/entrypoint.sh"]
CMD
["serve"]
docker/serve/config.properties
deleted
100644 → 0
View file @
3bbeddb7
inference_address
=
http://0.0.0.0:8080
management_address
=
http://0.0.0.0:8081
metrics_address
=
http://0.0.0.0:8082
model_store
=
/home/model-server/model-store
load_models
=
all
docker/serve/entrypoint.sh
deleted
100644 → 0
View file @
3bbeddb7
#!/bin/bash
set
-e
if
[[
"
$1
"
=
"serve"
]]
;
then
shift
1
torchserve
--start
--ts-config
/home/model-server/config.properties
else
eval
"
$@
"
fi
# prevent docker exit
tail
-f
/dev/null
model.properties
View file @
fe2ea1ea
# 模型唯一标识
modelCode
=
177
# 模型名称
# 模型名称
modelName
=
TSM_PyT
orch
modelName
=
tsm_pyt
orch
# 模型描述
# 模型描述
modelDescription
=
TSM
(Temporal Shift Module)是一种用于视频分类的模型
modelDescription
=
TSM
模型是一种基于时序建模的深度学习算法,利用时间偏移增强视频帧序列的表示能力,用于提高视频动作识别的准确性和鲁棒性。
# 应用场景
(多个标签以英文逗号分割)
# 应用场景
appScenario
=
训练,
pytroch,视频分类
appScenario
=
训练,
交通,政府,家居
# 框架类型
(多个标签以英文逗号分割)
# 框架类型
frameType
=
PyT
orch
frameType
=
pyt
orch
train_single.sh
0 → 100755
View file @
fe2ea1ea
#!/usr/bin/env bash
export
HIP_VISIBLE_DEVICES
=
0
./tools/dist_train.sh configs/recognition/tsm/tsm_r50_1x1x8_50e_sthv2_rgb.py 1
--validate
--seed
0
--cfg-options
model.backbone.pretrained
=
/jiutiandata/7.4/resnet50_8xb32_in1k_20210831-ea4938fc.pth optimizer.lr
=
0.005 data.videos_per_gpu
=
8 data.val_dataloader.videos_per_gpu
=
16 data.test_dataloader.videos_per_gpu
=
3 data.workers_per_gpu
=
4 evaluation.interval
=
1
--log_dir
pid.txt 2>&1 |
tee
tsm_dcu_
`
date
+%Y%m%d%H%M%S
`
.log
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}