
add new
Showing
LICENSE
0 → 100644
README.md
0 → 100644
data/enwik8/test.txt
0 → 100644
data/enwik8/train.txt
0 → 100644
data/enwik8/valid.txt
0 → 100644
doc/rusult.png
0 → 100644
{kind=link}
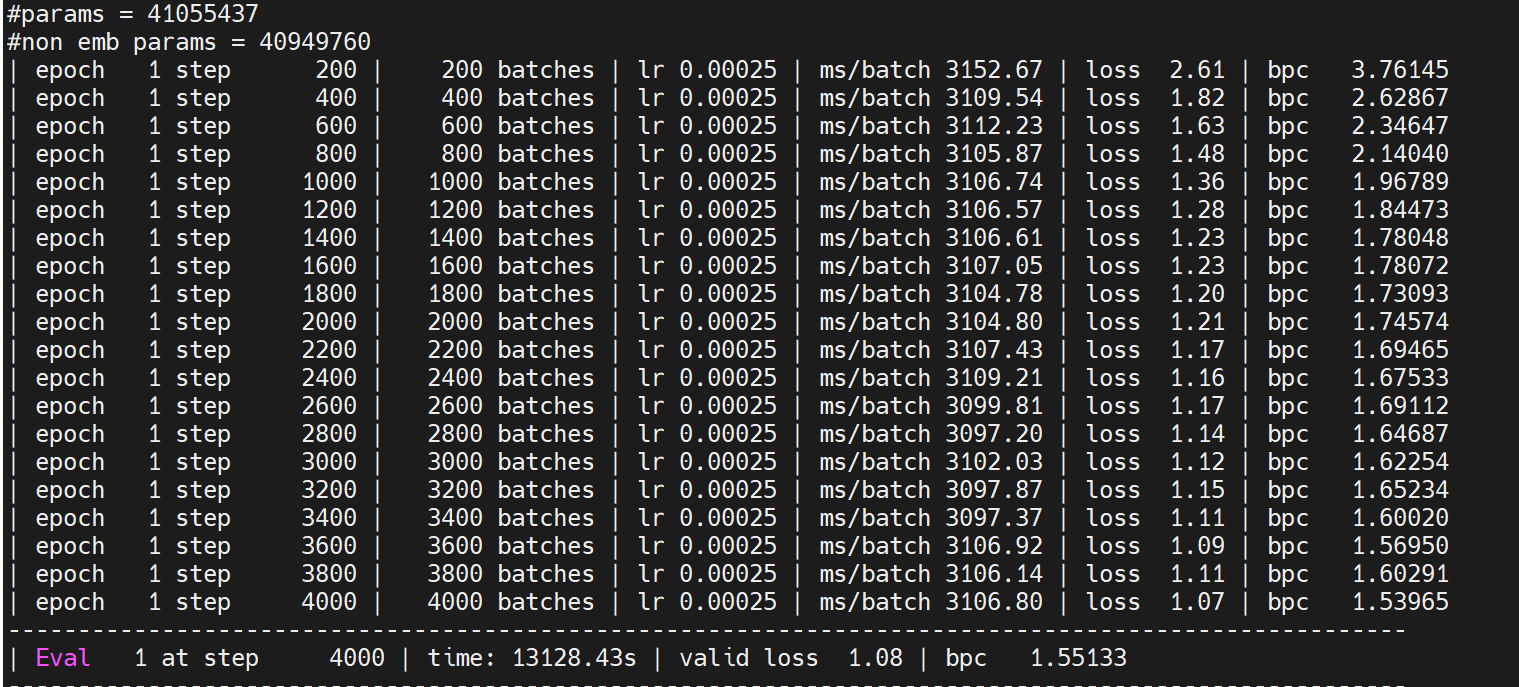
109 KB
doc/transformer的训练与评估.png
0 → 100644
{kind=link}
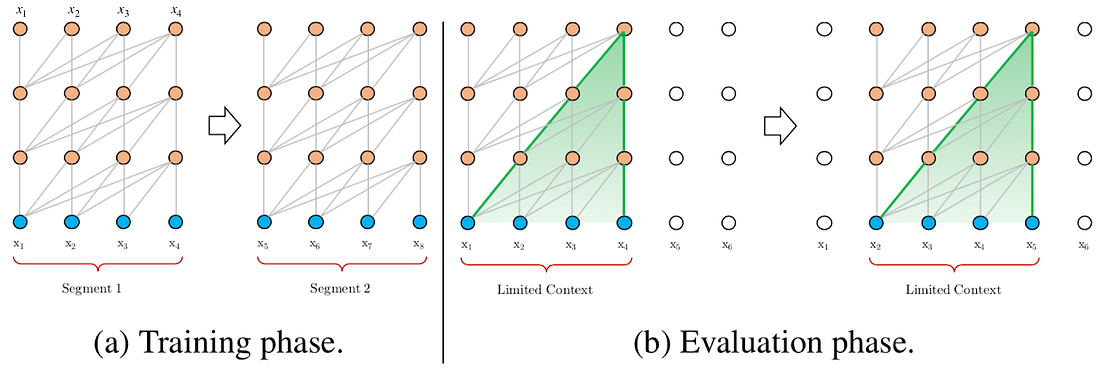
165 KB
doc/xl的训练与评估.png
0 → 100644
{kind=link}
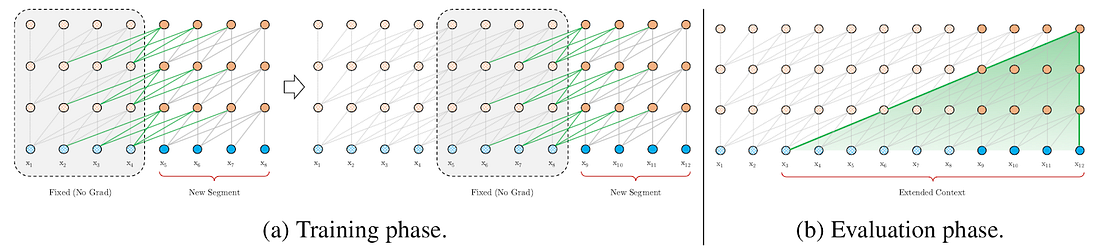
201 KB
doc/模型结构.png
0 → 100644
{kind=link}
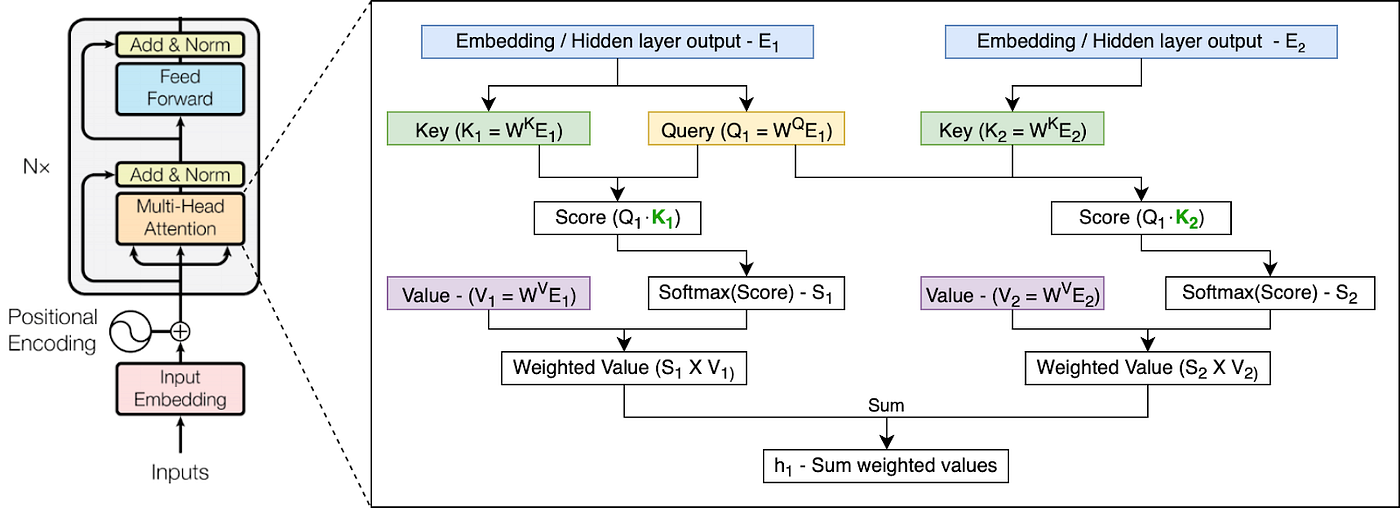
173 KB
getdata.sh
0 → 100644
prep_text8.py
0 → 100644
File added
File added
pytorch/data_utils.py
0 → 100644
pytorch/eval.py
0 → 100644
pytorch/mem_transformer.py
0 → 100644
This diff is collapsed.
pytorch/run_enwik8_base.sh
0 → 100644
pytorch/run_enwik8_large.sh
0 → 100644
pytorch/run_lm1b_base.sh
0 → 100644