
toolace
Showing
.gitignore
0 → 100644
Dockerfile
0 → 100644
README.md
0 → 100644
datasets/data_1.json
0 → 100644
This diff is collapsed.
icon.png
0 → 100644
{kind=link}
53.8 KB
inference.py
0 → 100644
model.properties
0 → 100644
readme_imgs/alg.png
0 → 100644
{kind=link}
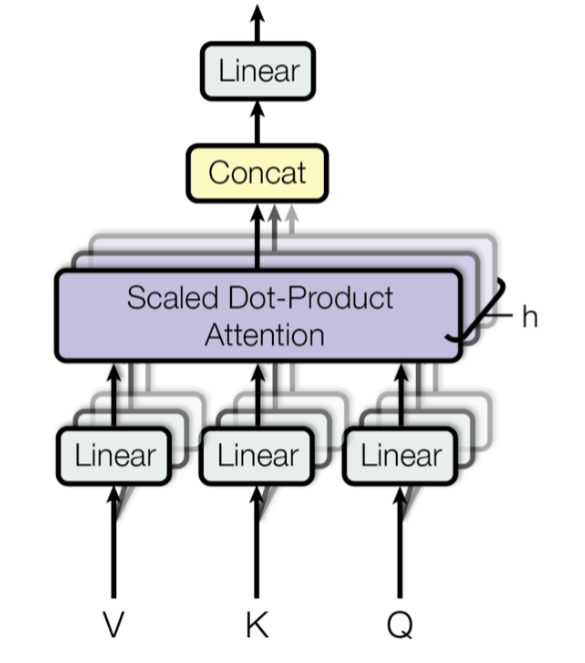
95 KB
readme_imgs/arch.png
0 → 100644
{kind=link}
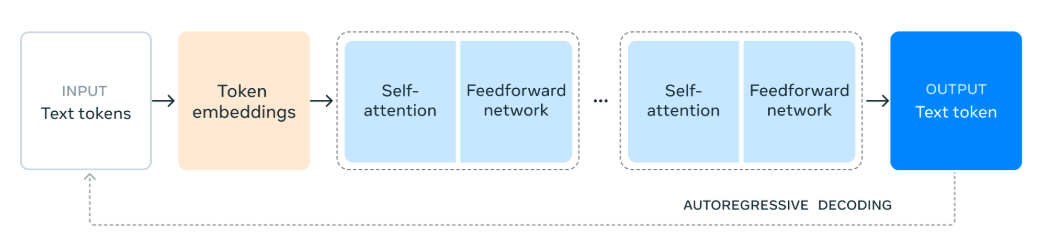
55.9 KB
readme_imgs/result.png
0 → 100644
{kind=link}
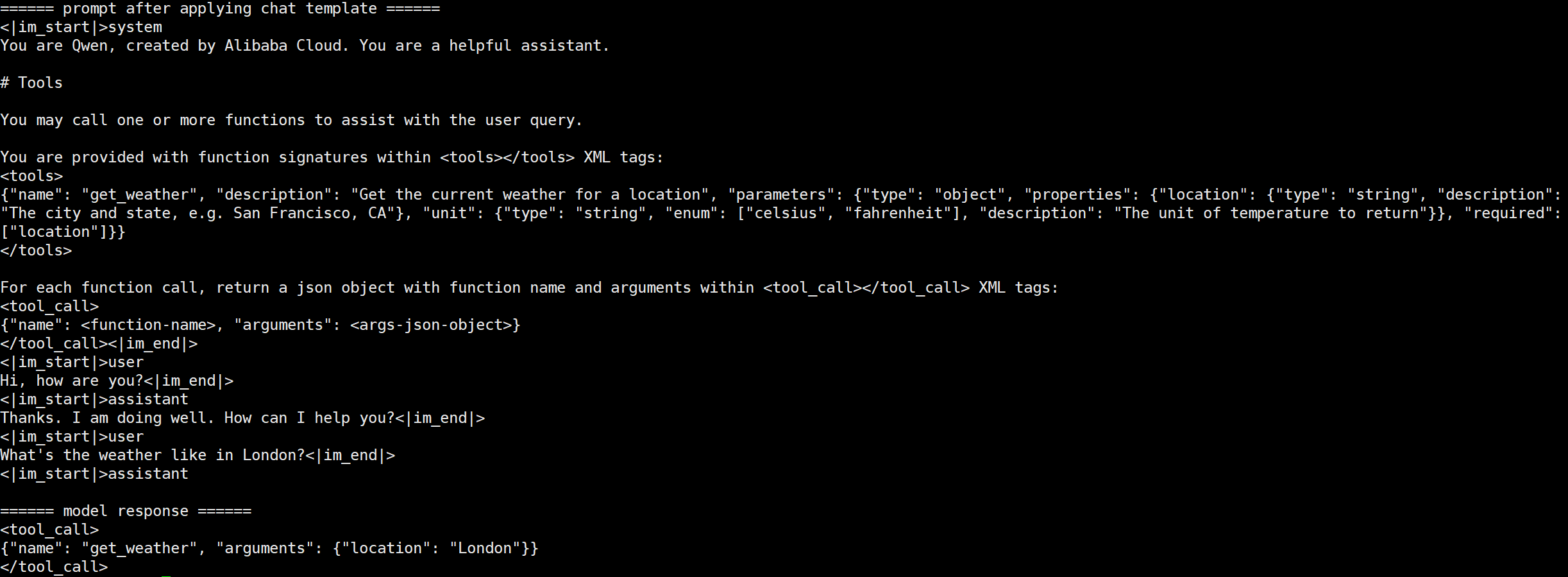
82.8 KB
scripts/data_process.py
0 → 100644