
v1.0
Showing
.gitignore
0 → 100644
EVAL.md
0 → 100644
LICENSE
0 → 100644
PRETRAIN.md
0 → 100644
{kind=link}
132 Bytes
This diff is collapsed.
File added
README.md
0 → 100644
README_origin.md
0 → 100644
README_zh-CN.md
0 → 100644
chat_gradio/README.md
0 → 100644
chat_gradio/app.py
0 → 100644
chat_gradio/requirements.txt
0 → 100644
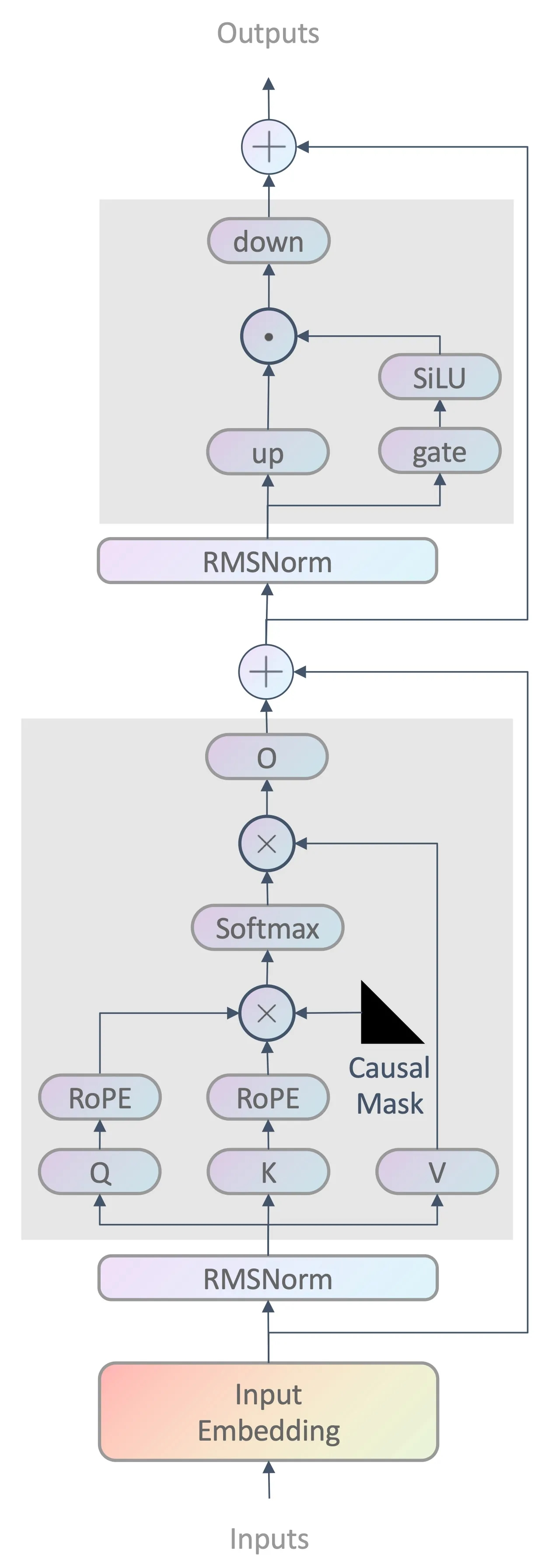
doc/bockbone.png
0 → 100644
{kind=link}
757 KB