
Initial commit
Showing
{kind=link}
No preview for this file type
assets/apple_r.jpeg
0 → 100644
{kind=link}

465 KB
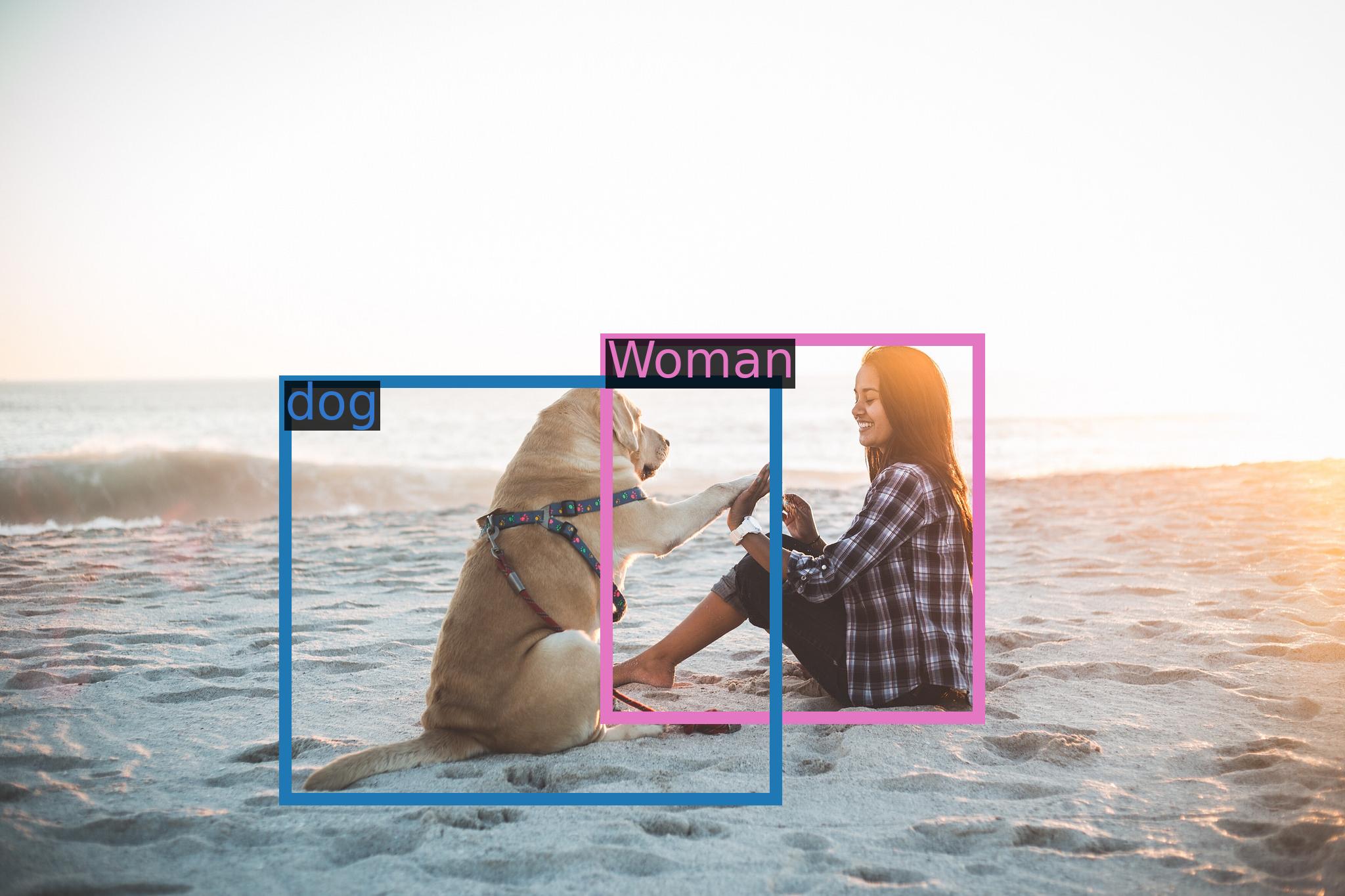
assets/demo_highfive.jpg
0 → 100644
{kind=link}

233 KB
{kind=link}
242 KB
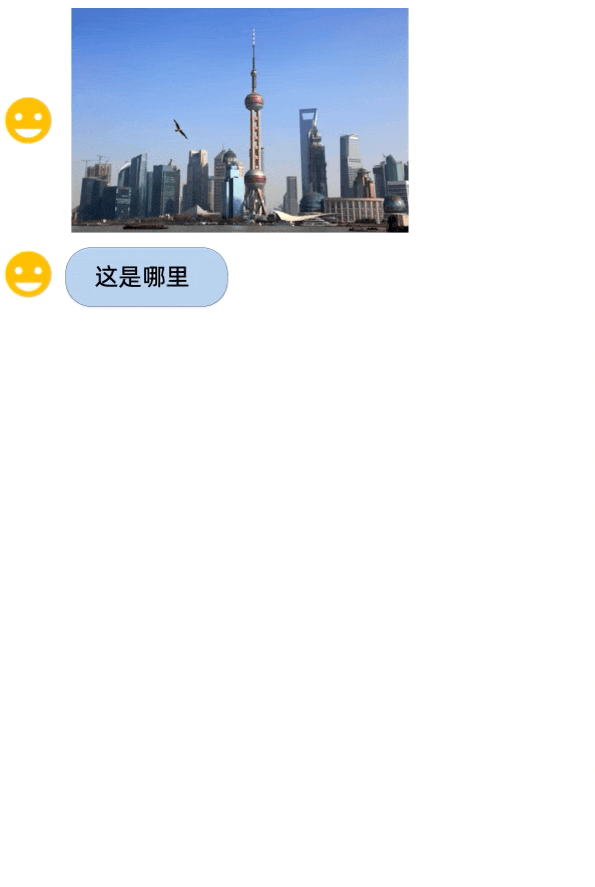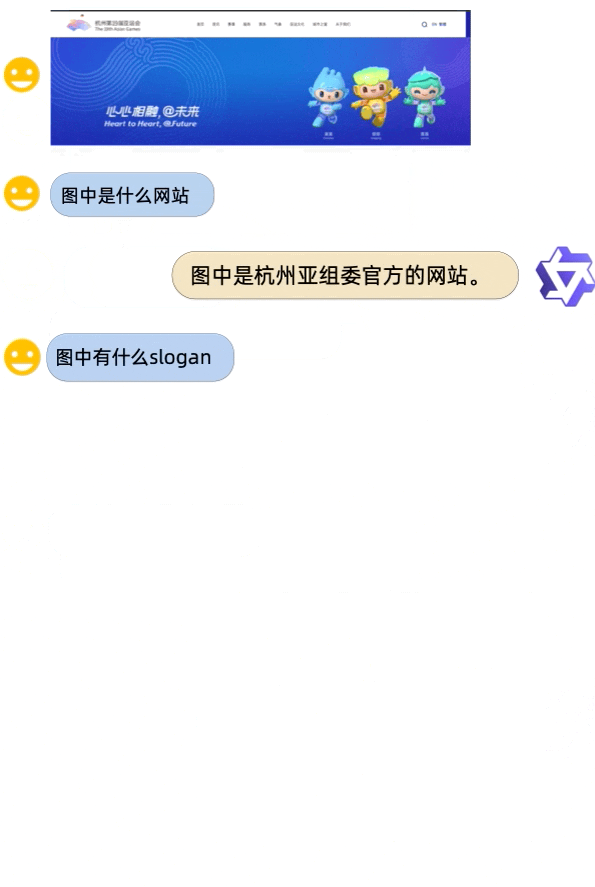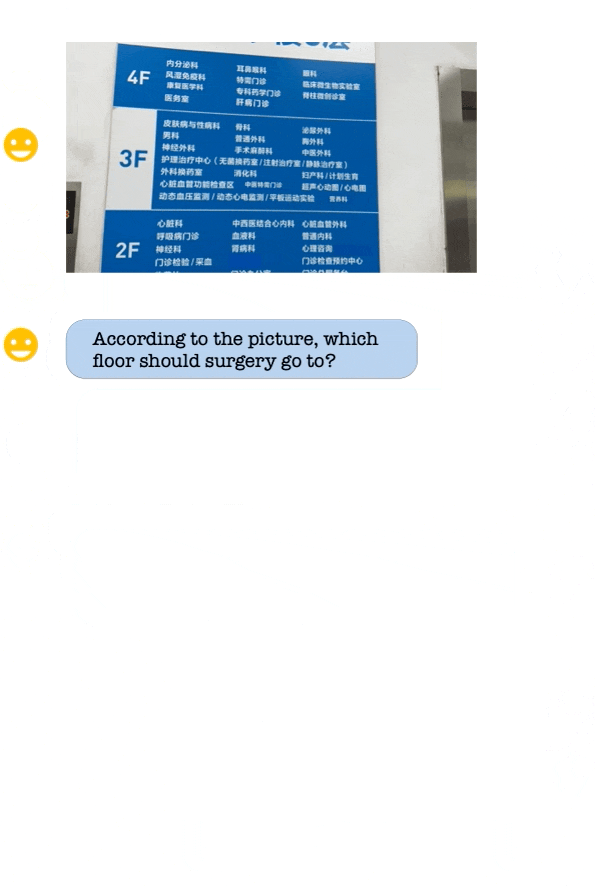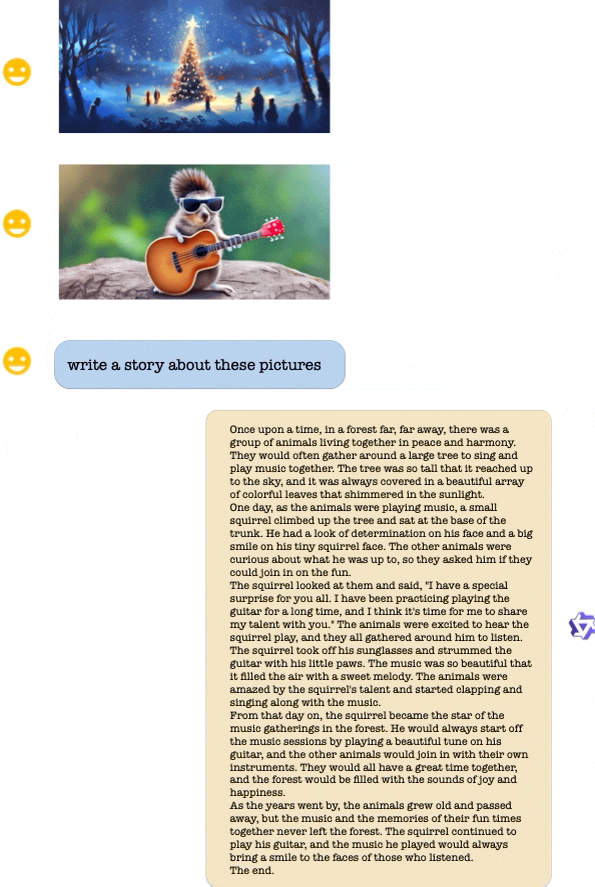
assets/demo_vl.gif
0 → 100644
{kind=link}
2.07 MB
assets/logo.jpg
0 → 100644
{kind=link}
61.9 KB
{kind=link}

8.8 MB
{kind=link}

179 KB
{kind=link}

1.62 MB
{kind=link}

344 KB
{kind=link}

399 KB
{kind=link}

53.6 KB
assets/mm_tutorial/Menu.jpeg
0 → 100644
{kind=link}

46.6 KB
.jpeg){kind=link}
.jpeg)
1.26 MB
_Small.jpeg){kind=link}
_Small.jpeg)
18.4 KB
{kind=link}

777 KB
{kind=link}

1.14 MB
{kind=link}

24.5 KB
{kind=link}

43.6 KB