Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
template_xxx
Commits
a0166be0
Commit
a0166be0
authored
Aug 17, 2023
by
chenzk
Browse files
v1.0
parent
0d79aeb5
Changes
6
Hide whitespace changes
Inline
Side-by-side
Showing
6 changed files
with
117 additions
and
177 deletions
+117
-177
ModelZooStd.md
ModelZooStd.md
+29
-103
README.md
README.md
+83
-69
doc/classes.png
doc/classes.png
+0
-0
doc/icon.png
doc/icon.png
+0
-0
doc/readme.png
doc/readme.png
+0
-0
model.properties
model.properties
+5
-5
No files found.
ModelZooStd.md
View file @
a0166be0
# 仓库目录结构
##
除预训练模型外其他文件总大小尽量不要超过50M
*
除预训练模型外其他文件总大小尽量不要超过50M
```
Project
├── imgs
│ ├── xxx.jpg
│ └── xxx.jpg
├── dataset
│ ├── label_1
│ ├── xxx.png
│ ├── xxx.png
│ └── ...
│ └── label_2
│ ├── xxx.png
│ ├── xxx.png
│ └── ...
├── model
│ ├── xxx.pth #预训练模型
│ ├── xxx.onnx #对应的onnx模型
│ └── xxx.mxr #对应的migraphx离线推理模型
├── icon.png
├── doc
│ ├── icon.png
│ ├── xxx.png
│ └── xxx.png
├── README.md
├── requirement.txt
├── model.properties
...
...
@@ -20,105 +29,22 @@
│ ├── code_file4.py
│ ├── code_file5.py
└── └── code_file6.py
### icon.png:模型的图标文件,可到[iconfont](https://www.iconfont.cn/?spm=a313x.7781069.1998910419.d4d0a486a)查找。
### README.md:参照本文件下面部分。
### requirement.txt:模型依赖统一写到此文件。
### model.properties:固定模板如下:
```
*
icon.png:模型的图标文件,可到
[
iconfont
](
https://www.iconfont.cn/?spm=a313x.7781069.1998910419.d4d0a486a
)
查找。

*
README.md:参照下图,
`十二大标题`
为必选项,二级标题以下的标题或内容根据自己的项目灵活增删。

*
requirement.txt:模型依赖统一写到此文件,与深度学习相关的库请注释,以免安装为nv库。
*
model.properties:
`五大属性`
固定模板如下:
```
# 模型唯一标识
modelCode=Project ID
# 模型名称
modelName=模型名称(同项目名称)
modelName=模型名称(同项目名称
:模型名_深度学习框架
)
# 模型描述
modelDescription=简要描述此模型(尽量50字以内)
# 应用场景
appScenario=推理,训练,OCR,
nlp,cv,车牌识别,目标检测
(首先描述推理训练信息,然后描述
领域
信息,多个标签用英文逗号隔开)
appScenario=推理,训练,OCR,
政府,交通,零售,金融,医疗
(首先描述推理
、
训练信息,然后描述
算法类别信息,最后描述应用行业
信息,多个标签用英文逗号隔开
。
)
# 框架类型
frameType=Tensorflow,PyTorch,Migraphx,ONNXRuntime(说明使用的框架类型, 多个标签用英文逗号隔开)
以下是README.md的编写框架:
# 模型名称(此处需修改,用英文全称与简写)
## 模型介绍
此处填写模型介绍。
## 模型结构
此处简要介绍模型结构。
## 数据集
此处介绍使用的数据集
如添加了自己写的数据集处理脚本,在此处说明脚本的使用方法:
python xxx.py \
--args0 xxx \
--args1 xxx \
...
## 训练及推理
### 环境配置
提供
[
光源
](
https://www.sourcefind.cn/#/service-details
)
拉取的训练以及推理的docker镜像:
*
训练镜像:
*
推理镜像:
python依赖安装:
pip install -r requirement.txt
### 训练与Fine-tunning
训练命令:
python train.py \
--args0 xxx \
--args1 xxx \
...
Fine-tunning命令:
python train.py \
--args0 xxx \
--args1 xxx \
...
### 预训练模型
model文件夹提供的预训练模型介绍,例如:
Project
├── model
│ ├── xxx.pth #pytorch预训练模型
│ ├── xxx.onnx #对应的onnx模型
└── └── xxx.mxr #对应的migraphx离线推理模型
### 测试
测试命令:
python test.py \
--args0 xxx \
--args1 xxx
...
### 推理
推理引擎版本:
*
ONNXRuntime(DCU版本) >= x.xx.x
*
Migraphx(DCU版本) >= x.x.x
#### ORT
基于ORT的推理命令:
python ORT_infer.py \
--args0 xxx \
--args1 xxx \
...
#### Migraphx
基于Migraphx的推理命令:
python Migraphx_infer.py \
--args0 xxx \
--args1 xxx \
...
## 性能和准确率数据
测试数据:
[
test data
](
链接
)
,使用的加速卡:xxx。
根据模型情况填写表格:
| xxx | xxx | xxx | xxx | xxx |
| :------: | :------: | :------: | :------: |:------: |
| xxx | xxx | xxx | xxx | xxx |
| xxx | xx | xxx | xxx | xxx |
## 源码仓库及问题反馈
*
仓库的https链接
## 参考
*
链接1
*
链接2
*
......
frameType=paddle(说明使用的算法框架, 多个标签用英文逗号隔开。)
```
README.md
View file @
a0166be0
# 模型名称(此处需修改,用英文全称与简写)
## 模型介绍
此处填写模型介绍。
# 算法名简写(英文简写)
## 论文
`此处填写实现本项目的算法论文名称`
-
此处填写算法论文的在线pdf地址
## 模型结构
此处简要介绍模型结构。
## 数据集
此处介绍使用的数据集
如添加了自己写的数据集处理脚本,在此处说明脚本的使用方法:
python xxx.py \
--args0 xxx \
--args1 xxx \
...
## 训练及推理
### 环境配置
提供
[
光源
](
https://www.sourcefind.cn/#/service-details
)
拉取的训练以及推理的docker镜像:
*
训练镜像:
*
推理镜像:
此处一句话简要介绍模型结构
python依赖安装:

## 算法原理
此处一句话简要介绍算法原理
pip install -r requirement.txt
### 训练与Fine-tunning
训练命令:

## 环境配置
python train.py \
--args0 xxx \
--args1 xxx \
...
1、此处提供
[
光源
](
https://www.sourcefind.cn/#/service-details
)
拉取docker镜像的地址与使用步骤
```
docker pull image.xxx
```
2、此处提供dockerfile的使用方法
```
docker build --no-cache -t xxx:latest .
```
3、此处提供本地配置、编译的详细步骤
Fine-tunning命令:
关于本项目DCU显卡所需的特殊深度学习库可从
[
光合
](
https://developer.hpccube.com/tool/
)
开发者社区下载安装。
```
DTK驱动:dtk23.04
python:python3.8
paddle:2.4.2
```
`Tips:以上dtk驱动、python、paddle等DCU相关工具版本需要严格一一对应`
python train.py \
--args0 xxx \
--args1 xxx \
...
### 预训练模型
model文件夹提供的预训练模型介绍,例如:
Project
├── model
│ ├── xxx.pth #pytorch预训练模型
│ ├── xxx.onnx #对应的onnx模型
└── └── xxx.mxr #对应的migraphx离线推理模型
### 测试
测试命令:
python test.py \
--args0 xxx \
--args1 xxx
...
其它非深度学习库参照requirements.txt安装:
```
pip install -r requirements.txt
```
## 数据集
`此处填写公开数据集名称`
-
此处填写公开数据集下载地址
### 推理
推理引擎版本:
*
ONNXRuntime(DCU版本) >= x.xx.x
*
Migraphx(DCU版本) >= x.x.x
#### ORT
基于ORT的推理命令:
此处提供数据预处理脚本的使用方法
```
python xxx.py
```
项目中需要提供可训练的迷你数据集,整理完成后的数据目录结构如下:
```
── dataset
│ ├── label_1
│ ├── xxx.png
│ ├── xxx.png
│ └── ...
│ └── label_2
│ ├── xxx.png
│ ├── xxx.png
│ └── ...
```
## 训练
### 单机多卡
```
sh xxx.sh
```
python ORT_infer.py \
--args0 xxx \
--args1 xxx \
...
#### Migraphx
基于Migraphx的推理命令:
### 多机多卡
```
sbatch xxx.sh
```
## 推理
```
python xxx.py
```
## result
此处填算法效果测试图
python Migraphx_infer.py \
--args0 xxx \
--args1 xxx \
...

##
性能和准确率数据
##
# 速度与精度
测试数据:
[
test data
](
链接
)
,使用的加速卡:xxx。
根据
模型
情况填写表格:
根据
测试结果
情况填写表格:
| xxx | xxx | xxx | xxx | xxx |
| :------: | :------: | :------: | :------: |:------: |
| xxx | xxx | xxx | xxx | xxx |
| xxx | xx | xxx | xxx | xxx |
## 应用场景
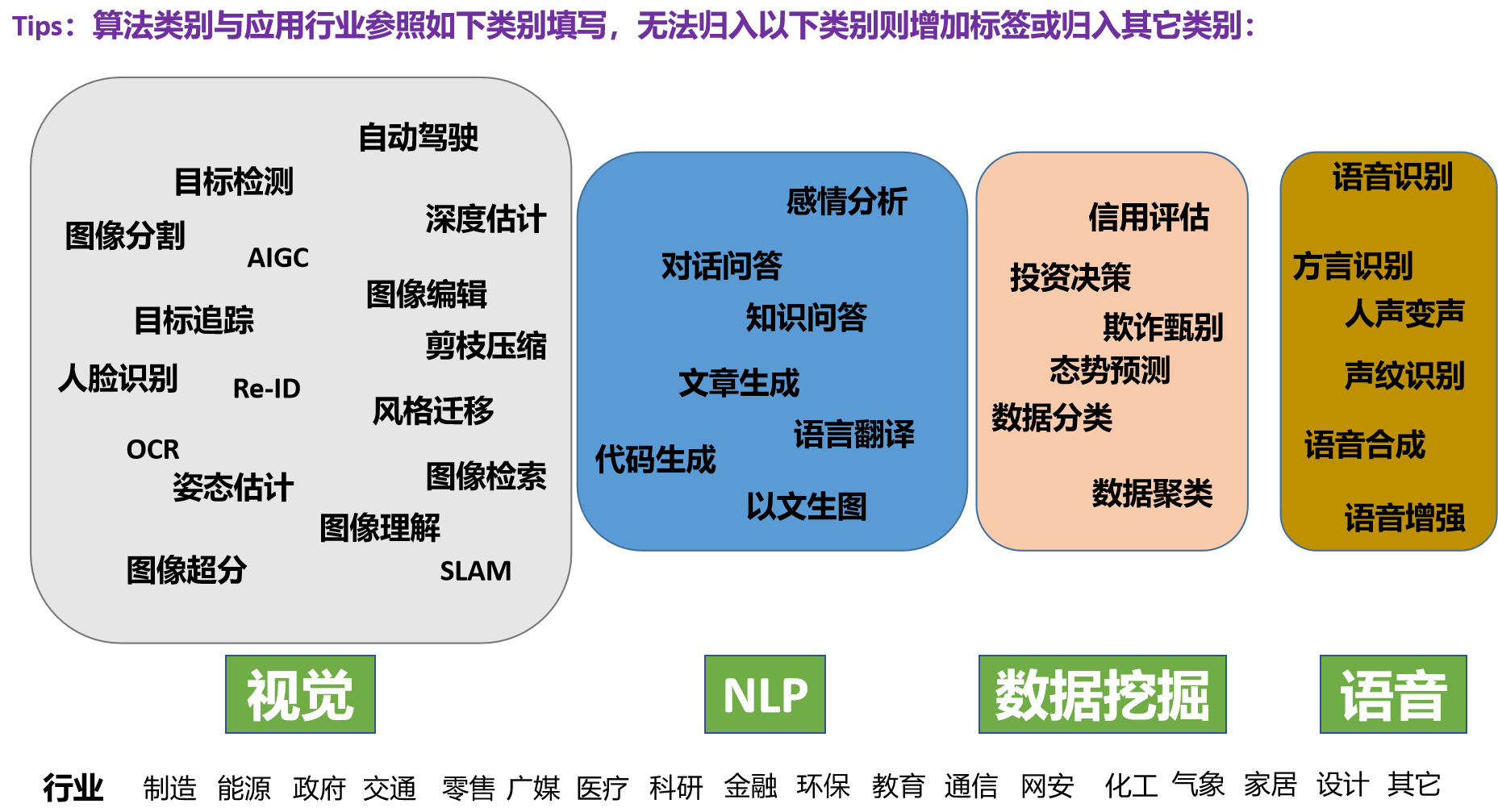
### 算法类别
参考此分类方法(上传时请去除参考图片):

`此处填算法类别`
### 应用行业
`此处填应用行业`
### 算法框架
`此处填算法框架`
## 预训练权重
`(若为github原预训练权重此标题可去除。)`
## 源码仓库及问题反馈
*
仓库的https链接
## 参考
*
链接1
*
链接2
*
......
-
此处填本项目gitlab地址
## 参考
资料
-
此处填源github地址
-
此处填参考项目或教程网址
-
......
doc/classes.png
0 → 100644
View file @
a0166be0
199 KB
icon.png
→
doc/
icon.png
View file @
a0166be0
File moved
doc/readme.png
0 → 100644
View file @
a0166be0
230 KB
model.properties
View file @
a0166be0
# 模型
编码
modelCode
=
Project ID(
模型唯一标识,GitLab项目
名称下面
查看
Project ID
,细节可查询GitLab api说明,例如100
)
# 模型
唯一标识
modelCode
=
Project ID(
GitLab创建项目后查看
名称下面
的
Project ID
即可,注意此ID为hpccube下GitLab生成的ID,不可编造。例如:359
)
# 模型名称
modelName
=
模型名称(同项目名称,模型
_
框架,全部采用小写,例如ocr_paddle,resnet50_tensorflow2)
modelName
=
模型名称(同项目名称,模型
名_深度学习
框架,全部采用小写,例如ocr_paddle,resnet50_tensorflow2)
# 模型描述
modelDescription
=
简要描述此模型(尽量50字以内)
# 应用场景
appScenario
=
推理,训练,OCR,
nlp,cv,车牌识别,目标检测
(首先描述推理训练信息,然后描述
领域
信息,多个标签用英文逗号隔开)
appScenario
=
推理,训练,OCR,
政府,交通,零售,金融,医疗
(首先描述推理
、
训练信息,然后描述
算法类别信息,最后描述应用行业
信息,多个标签用英文逗号隔开
。
)
# 框架类型
frameType
=
Tensorflow,PyTorch,Migraphx,ONNXRuntim
e(说明使用的框架
类型
, 多个标签用英文逗号隔开)
frameType
=
paddl
e(说明使用的
算法
框架, 多个标签用英文逗号隔开
。
)
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}
{kind=link}
