
taming-transformer
Showing
.gitignore
0 → 100644
Dockerfile
0 → 100644
License.txt
0 → 100644
README.md
0 → 100644
README_official.md
0 → 100644
This diff is collapsed.
assets/birddrawnbyachild.png
0 → 100644
{kind=link}

1.53 MB
{kind=link}
This diff is collapsed.
assets/drin.jpg
0 → 100644
{kind=link}

279 KB
assets/faceshq.jpg
0 → 100644
{kind=link}

300 KB
{kind=link}

1.29 MB
{kind=link}

1.36 MB
assets/imagenet.png
0 → 100644
{kind=link}

1000 KB
{kind=link}

552 KB
assets/mountain.jpeg
0 → 100644
{kind=link}

426 KB
{kind=link}
This diff is collapsed.
assets/stormy.jpeg
0 → 100644
{kind=link}

701 KB
assets/sunset_and_ocean.jpg
0 → 100644
{kind=link}

314 KB
assets/teaser.png
0 → 100644
{kind=link}
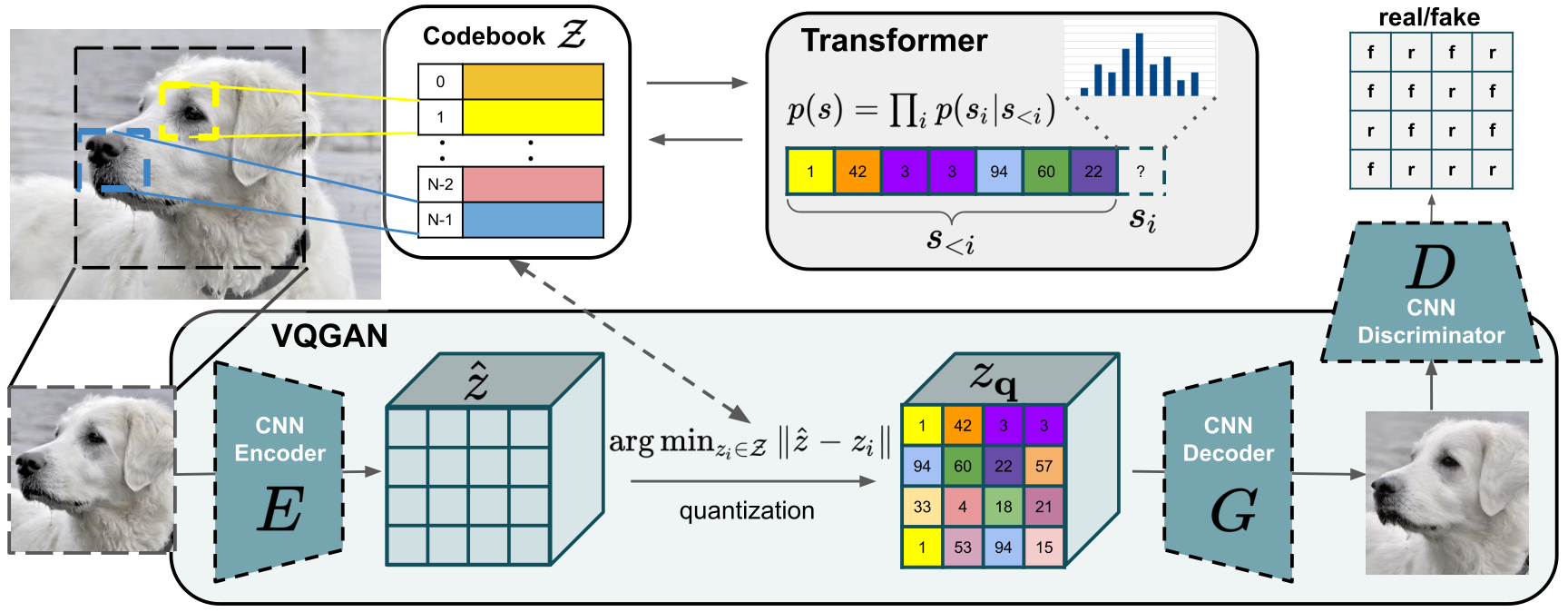
350 KB
configs/coco_cond_stage.yaml
0 → 100644