
"Initial commit"
Showing
.gitignore
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_orgin.md
0 → 100644
api/call_remote_server.py
0 → 100644
assets/Step-Video-T2V.pdf
0 → 100644
File added
assets/dcvae.png
0 → 100644
{kind=link}
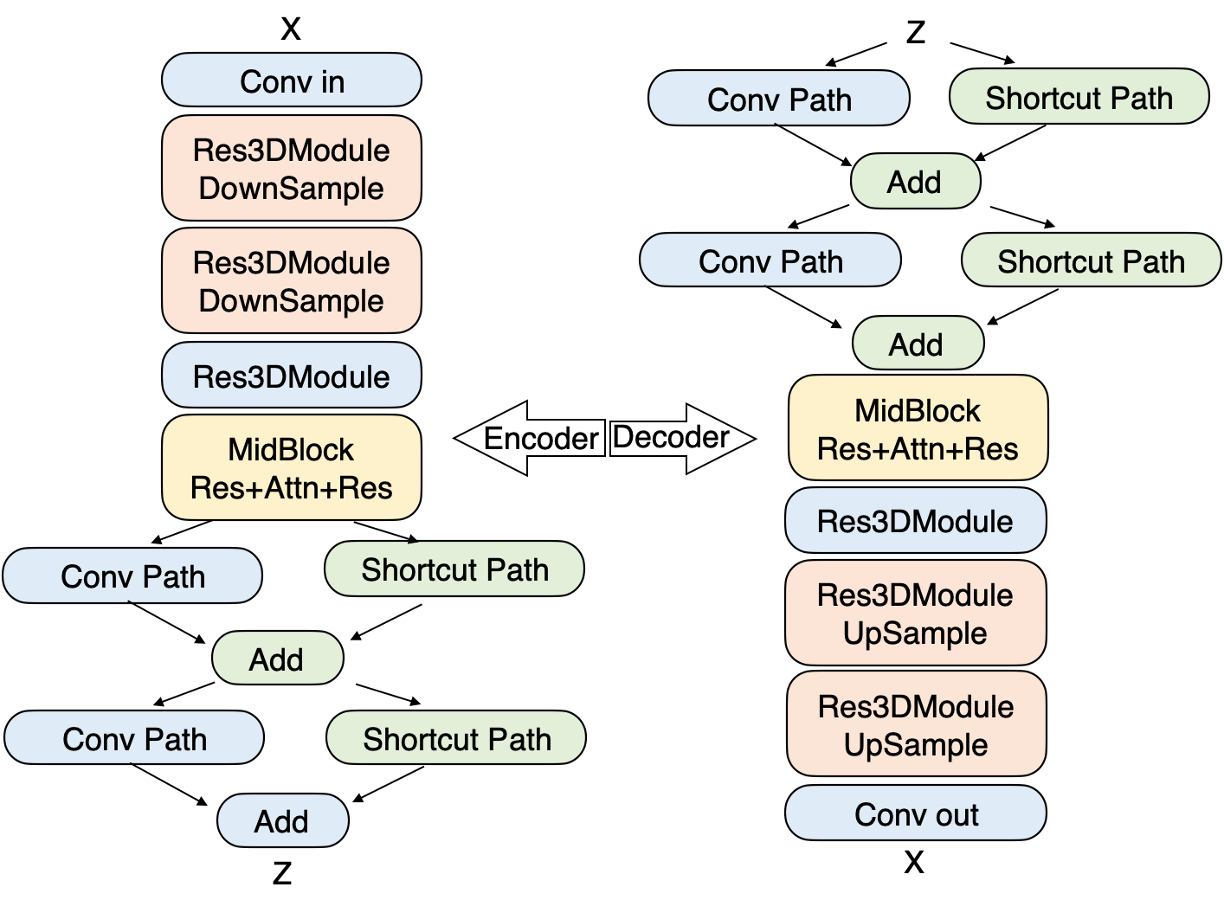
285 KB
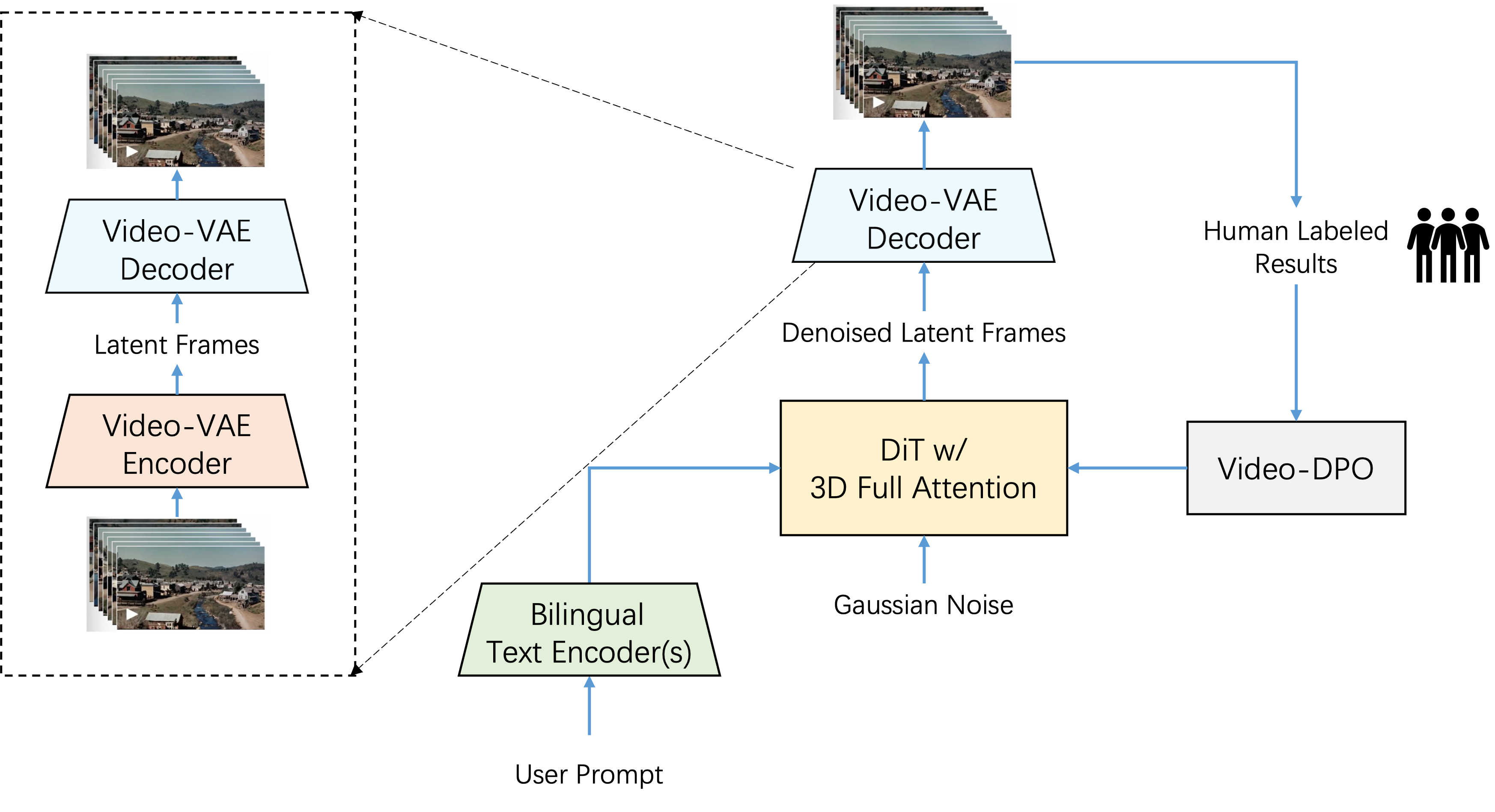
assets/dit.png
0 → 100644
{kind=link}
1.8 MB
assets/dpo_pipeline.png
0 → 100644
{kind=link}
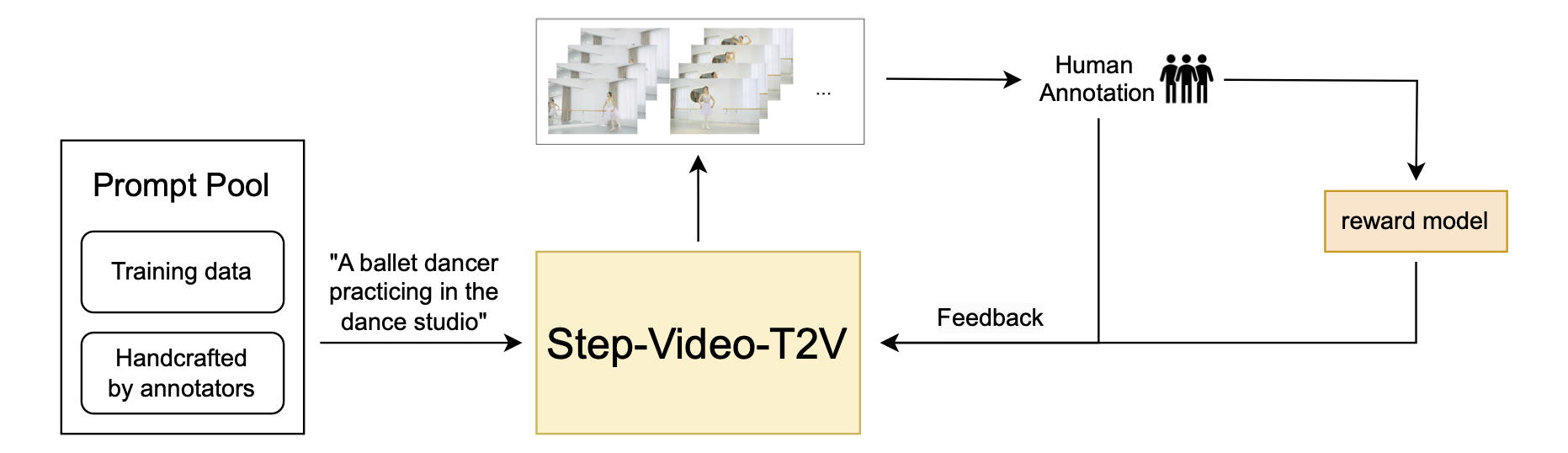
136 KB
assets/logo.png
0 → 100644
{kind=link}
6.71 KB
{kind=link}
960 KB
assets/一名宇航员在月球上.mp4
0 → 100644
File added
File added
File added
This diff is collapsed.
benchmark/evaluation.py
0 → 100644
docker/Dockerfile
0 → 100644
fix.sh
0 → 100644
icon.png
0 → 100644
{kind=link}
70.5 KB
model.properties
0 → 100644