
v1.0
Showing
.gitignore
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_origin.md
0 → 100644
audio.wav
0 → 100644
File added
audios/audio0.wav
0 → 100644
File added
audios/audio1.wav
0 → 100644
File added
audios/audio2.wav
0 → 100644
File added
audios/audio3.wav
0 → 100644
File added
audios/audio4.wav
0 → 100644
File added
audios/audio5.wav
0 → 100644
File added
audios/audio6.wav
0 → 100644
File added
checkpoints/.keep
0 → 100644
File added
config.py
0 → 100644
datas/__init__.py
0 → 100644
datas/dataset.py
0 → 100644
datas/sampler.py
0 → 100644
doc/algorithm.png
0 → 100644
{kind=link}
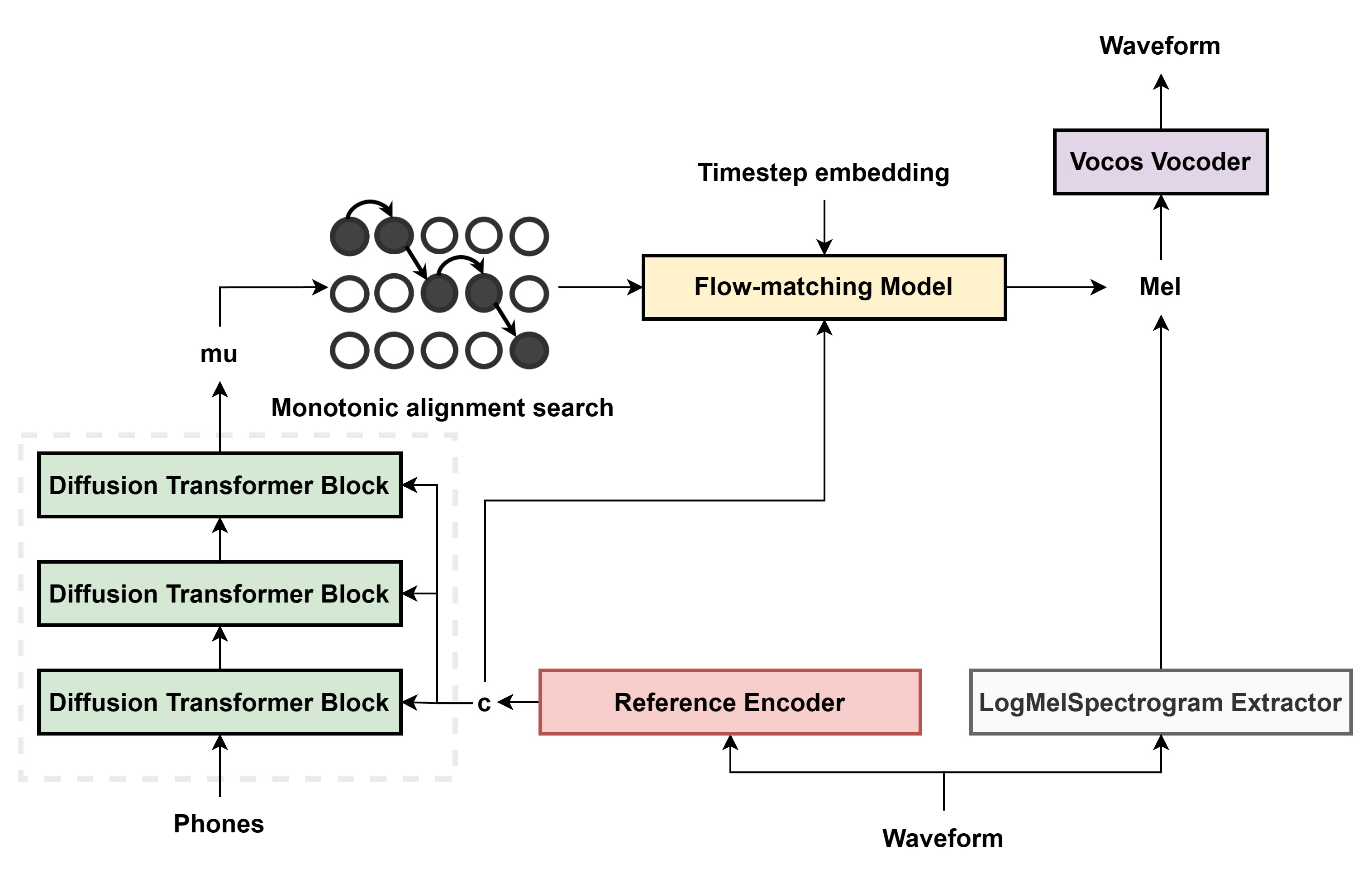
617 KB
doc/structure.png
0 → 100644
{kind=link}
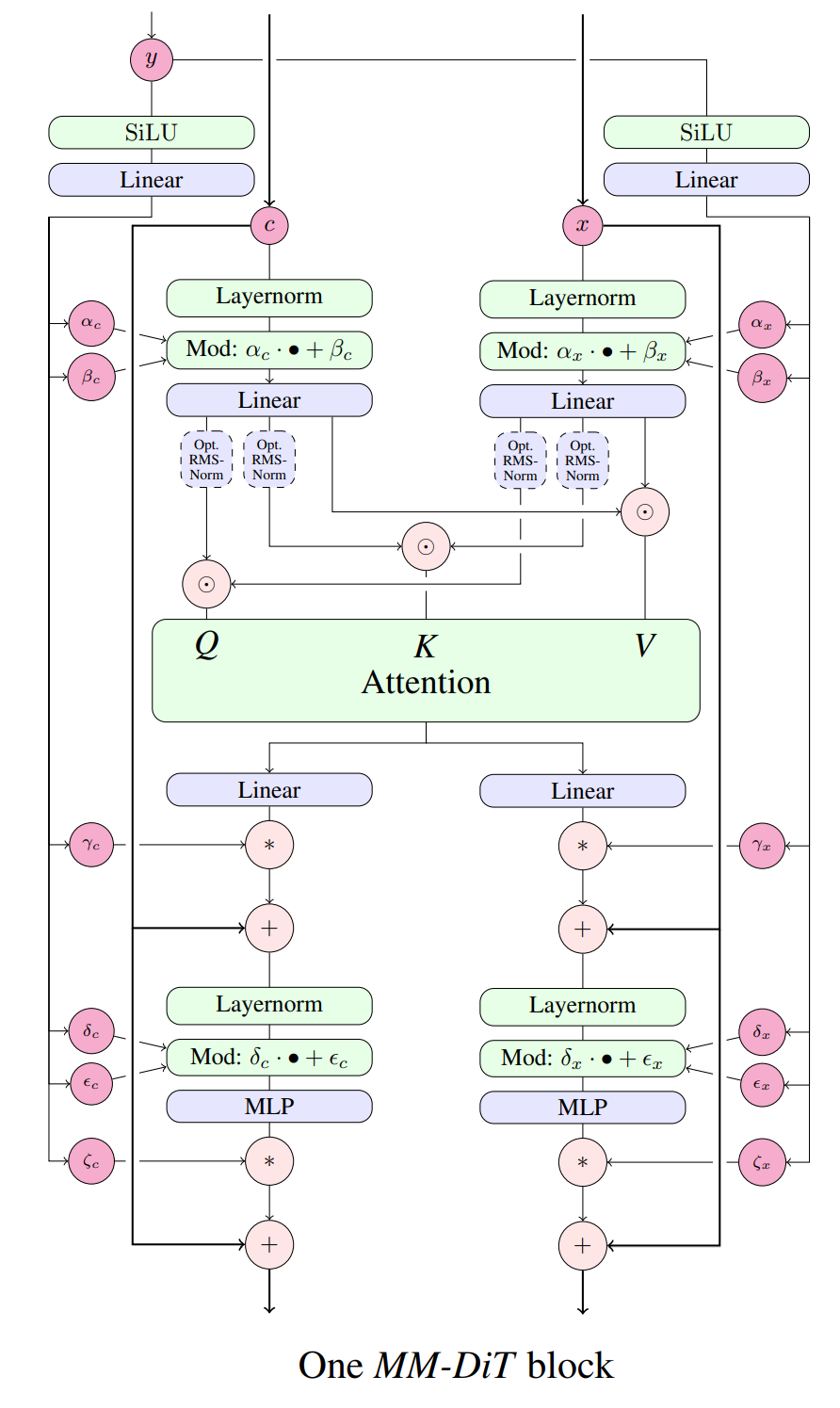
167 KB