
init commit
Showing
astro_horse.jpg
0 → 100644
{kind=link}

30.8 KB
requirements.txt
0 → 100644
| accelerate | ||
| diffusers | ||
| optimum[onnxruntime] | ||
| transformers | ||
| \ No newline at end of file |
sd_model.png
0 → 100644
{kind=link}
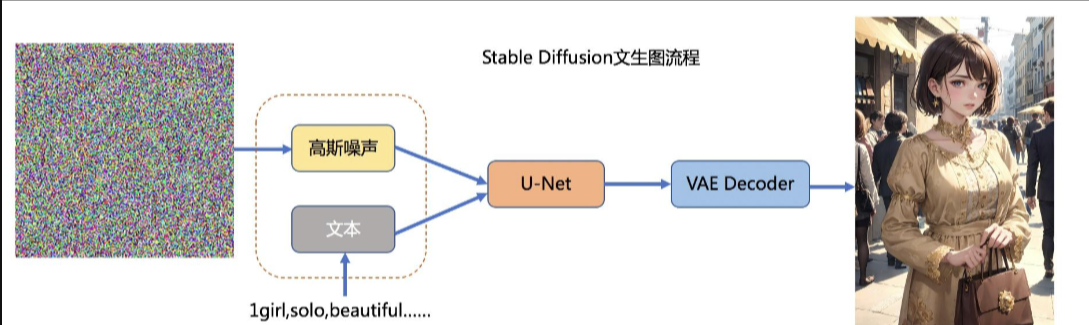
377 KB