"docs/vscode:/vscode.git/clone" did not exist on "3ff5bb3e6763af92dea8aae0ca2d5745a8b9043c"

First add
Showing
.gitignore
0 → 100644
.pre-commit-config.yaml
0 → 100644
LICENSE
0 → 100644
Makefile
0 → 100644
ModelZooStd.md
0 → 100644
NOTICE.txt
0 → 100644
README.md
0 → 100644
README_ori.md
0 → 100644
This source diff could not be displayed because it is too large. You can view the blob instead.
This source diff could not be displayed because it is too large. You can view the blob instead.
This source diff could not be displayed because it is too large. You can view the blob instead.
datasets/tmp.txt
0 → 100644
doc/example.png
0 → 100644
{kind=link}

40.3 KB
doc/image.png
0 → 100644
{kind=link}
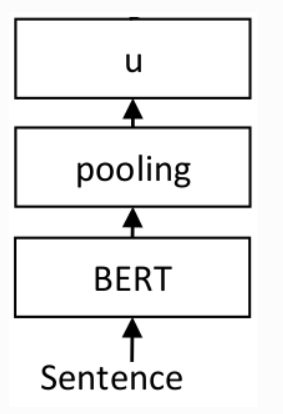
19 KB
doc/infer.png
0 → 100644
{kind=link}
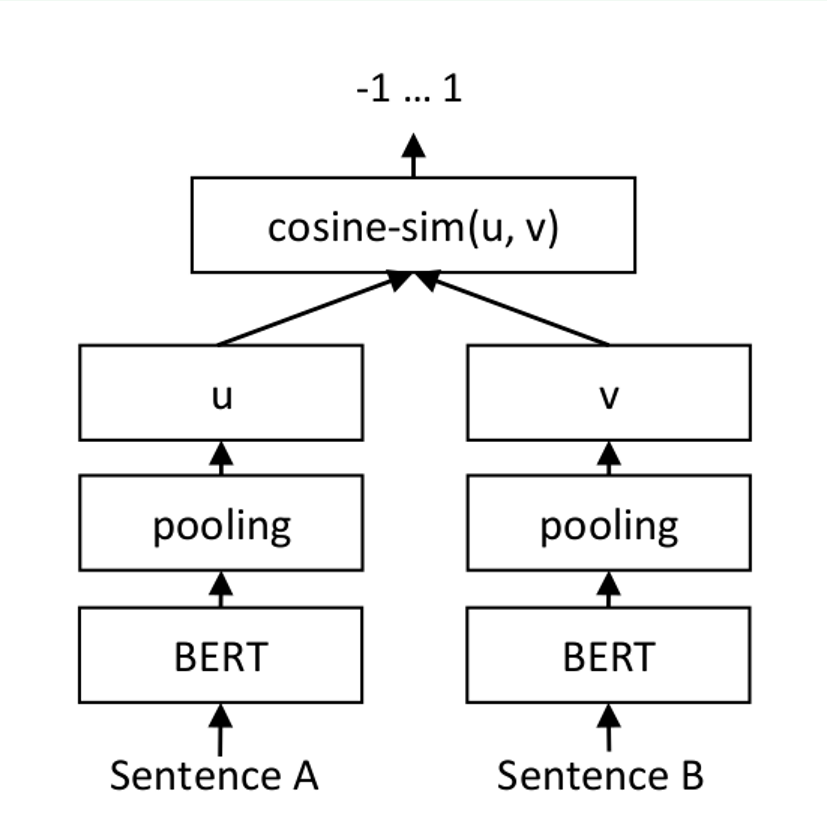
72.7 KB
doc/model.png
0 → 100644
{kind=link}
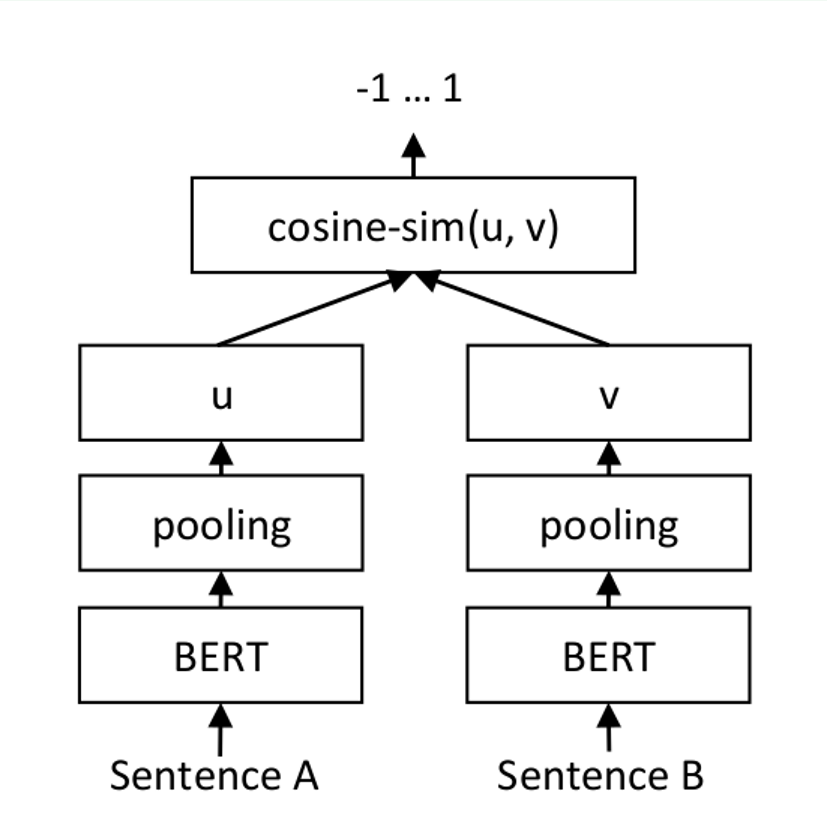
72.7 KB
doc/results.png
0 → 100644
{kind=link}

31.6 KB
docker/Dockerfile
0 → 100644
docs/Makefile
0 → 100644