
first
Showing
SenseNova-U1/.python-version
0 → 100644
SenseNova-U1/LICENSE
0 → 100644
SenseNova-U1/README.md
0 → 100644
SenseNova-U1/README_CN.md
0 → 100644
{kind=link}
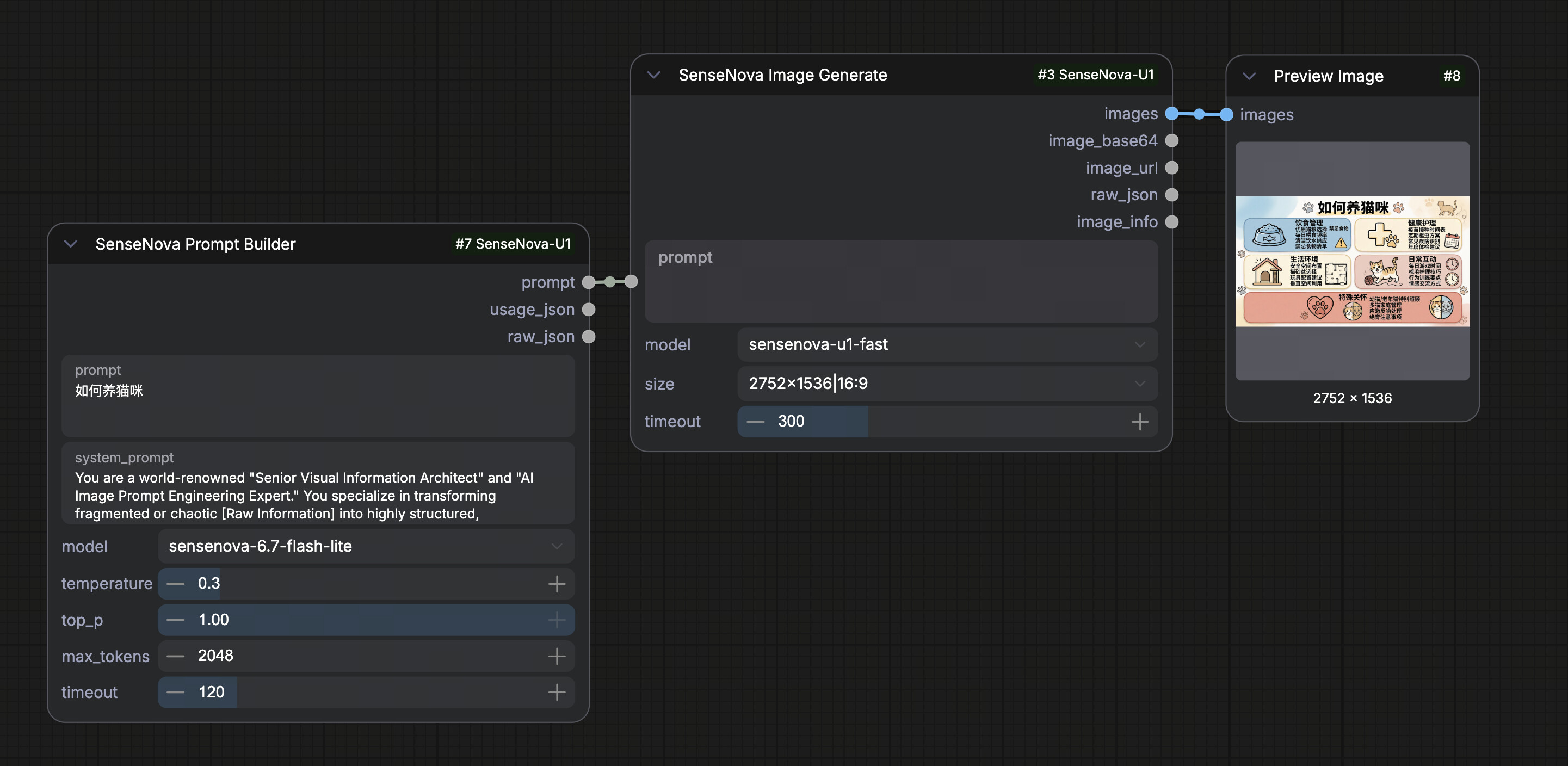
414 KB
{kind=link}

580 KB
{kind=link}

1.24 MB
{kind=link}
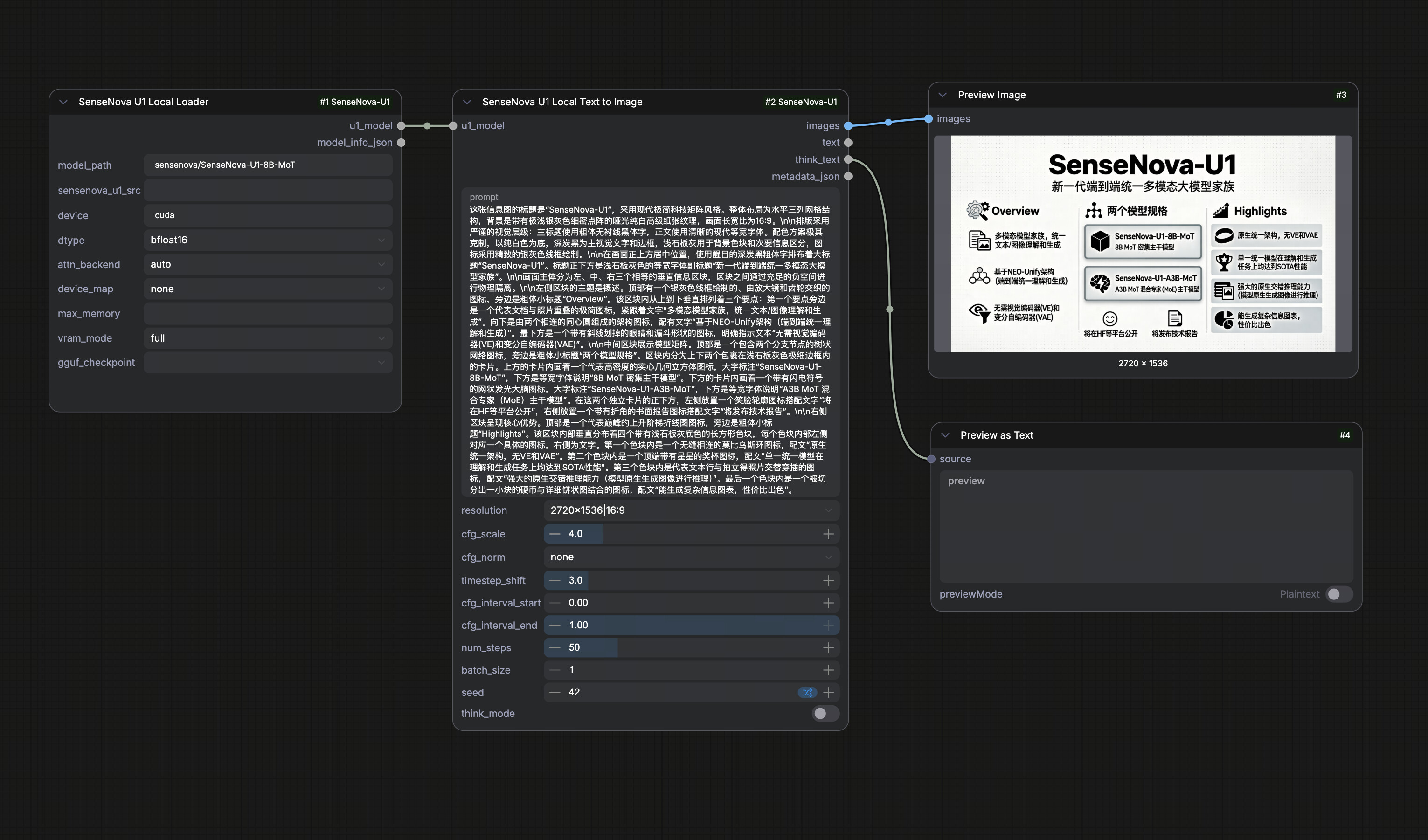
791 KB