
Initial commit
Showing
File added
File added
Data/test.txt
0 → 100644
LICENSE
0 → 100644
README-old.md
0 → 100644
README.md
0 → 100644
assets/feature_space.png
0 → 100644
{kind=link}
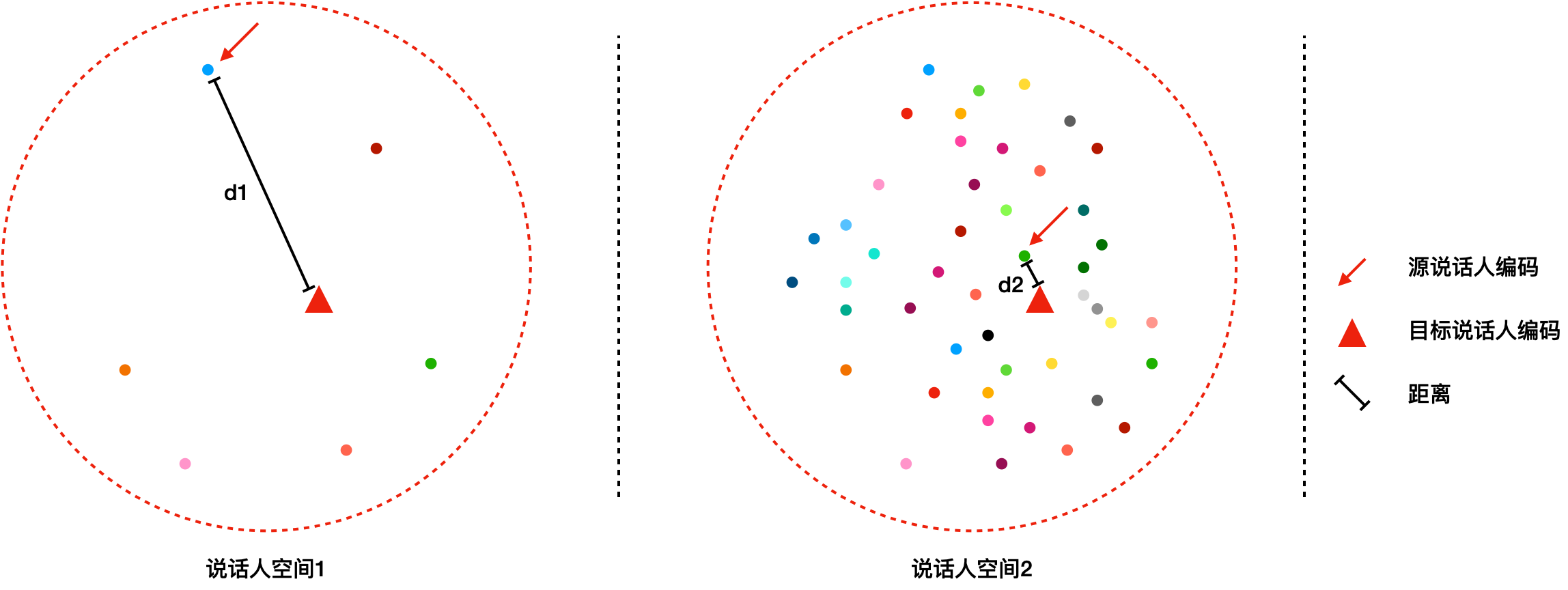
151 KB
assets/ptts.png
0 → 100644
{kind=link}
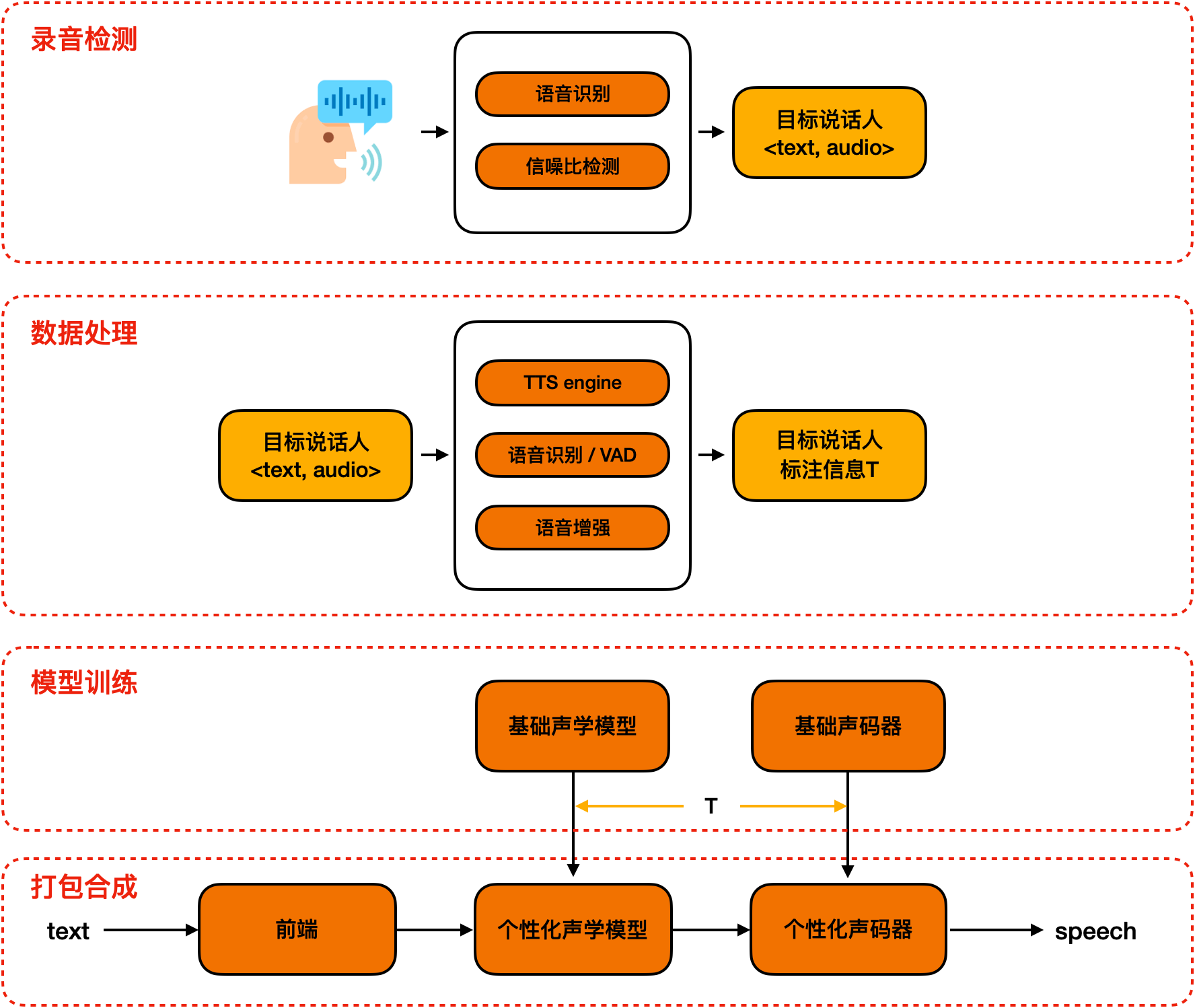
226 KB
assets/sambert.jpg
0 → 100644
{kind=link}
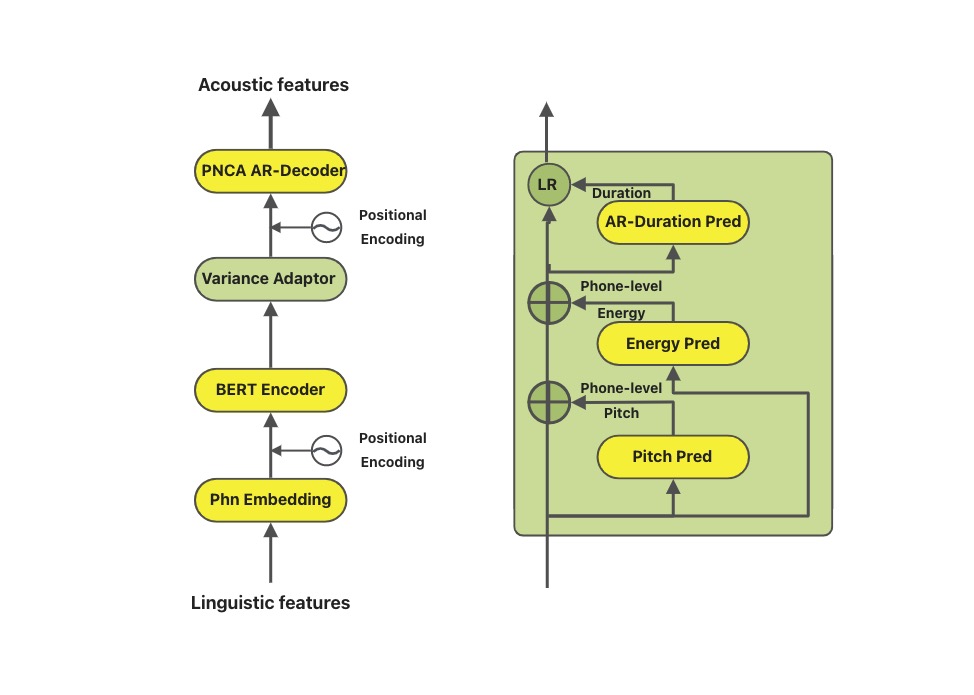
67.1 KB
feats_extract.sh
0 → 100644
kantts/__init__.py
0 → 100644
File added
kantts/bin/__init__.py
0 → 100644
File added
File added
File added
File added
File added
File added
kantts/bin/infer_hifigan.py
0 → 100644