
init
Showing
.gitignore
0 → 100644
LICENSE
0 → 100755
README.md
0 → 100644
README_origin.md
0 → 100755
app_sadtalker.py
0 → 100755
cog.yaml
0 → 100755
dataset/bus_chinese.wav
0 → 100755
File added
dataset/image.png
0 → 100755
{kind=link}

134 KB
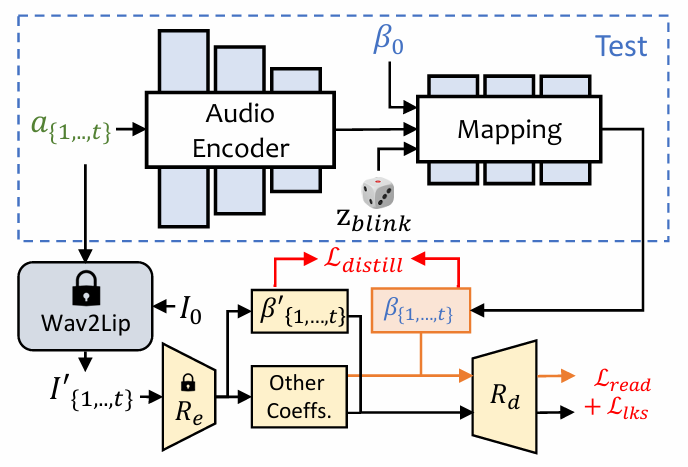
doc/ExpNet.PNG
0 → 100644
{kind=link}
42.4 KB
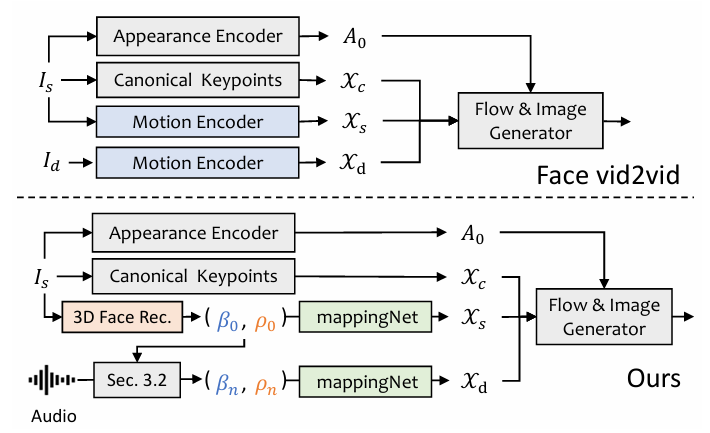
doc/FaceRender.PNG
0 → 100644
{kind=link}
52.8 KB
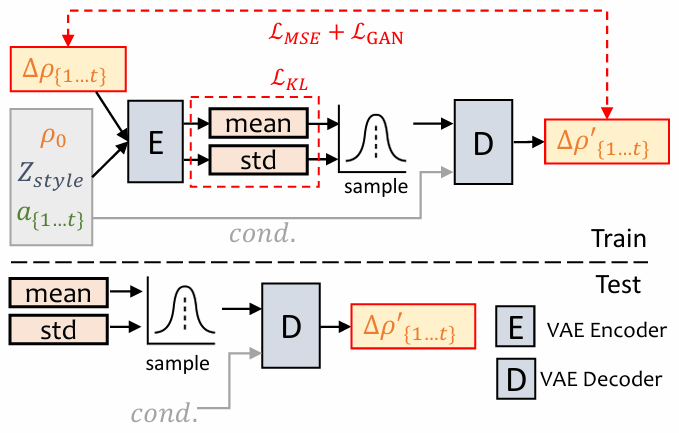
doc/PoseVAE.PNG
0 → 100644
{kind=link}
42.2 KB
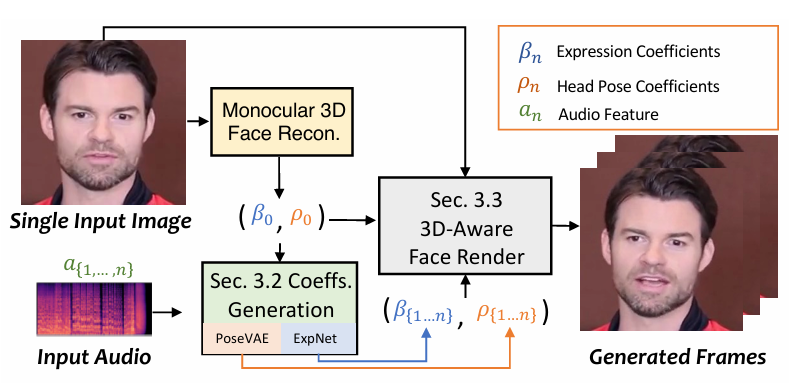
doc/SadTalker.PNG
0 → 100644
{kind=link}
198 KB
doc/inference_result.mp4
0 → 100644
File added
docs/FAQ.md
0 → 100755
docs/best_practice.md
0 → 100755
docs/changlelog.md
0 → 100755
docs/example_crop.gif
0 → 100755
{kind=link}

1.48 MB
docs/example_crop_still.gif
0 → 100755
{kind=link}

1.19 MB
docs/example_full.gif
0 → 100755
{kind=link}

1.39 MB
docs/example_full_crop.gif
0 → 100755
{kind=link}

817 KB