
Initial commit
Showing
.gitignore
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_cn.md
0 → 100644
README_origin.md
0 → 100644
benchmark/README.md
0 → 100644
benchmark/dataset.py
0 → 100644
benchmark/trtexec.md
0 → 100644
benchmark/trtinfer.py
0 → 100644
benchmark/utils.py
0 → 100644
benchmark/yolov8_onnx.py
0 → 100644
datasets/000000033109.jpg
0 → 100644
{kind=link}

209 KB
datasets/url.txt
0 → 100644
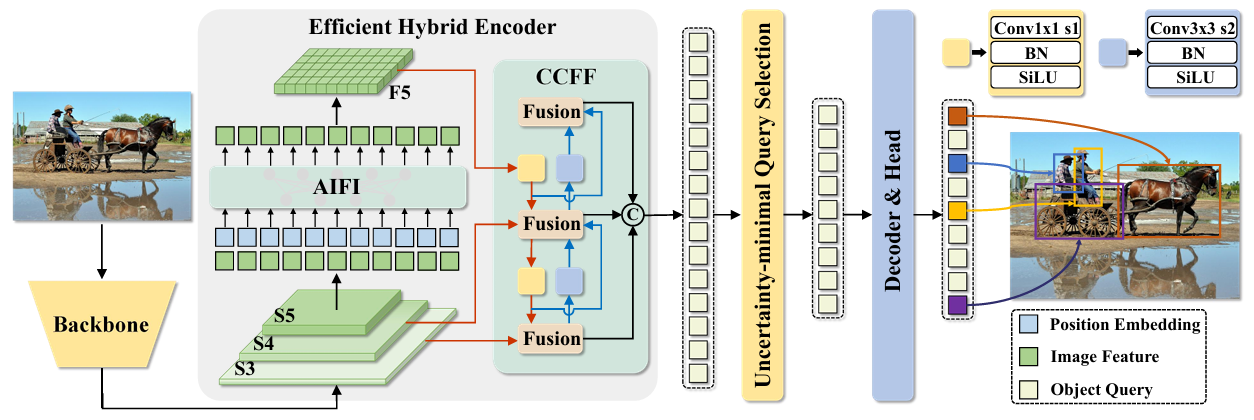
doc/RT-DETR.PNG
0 → 100644
{kind=link}
314 KB
doc/inference_result.jpg
0 → 100644
{kind=link}

78.2 KB
model.properties
0 → 100644
model/url.txt
0 → 100644
onnx_infer.py
0 → 100644
requirements.txt
0 → 100644
| # torch==2.0.1 | ||
| # torchvision==0.15.2 | ||
| onnx==1.14.0 | ||
| onnxruntime==1.15.1 | ||
| pycocotools | ||
| PyYAML | ||
| scipy |
rtdetr_pytorch/README.md
0 → 100644