
modify readme
Showing
README_origin.md
0 → 100644
ResNet50.png
0 → 100644
{kind=link}
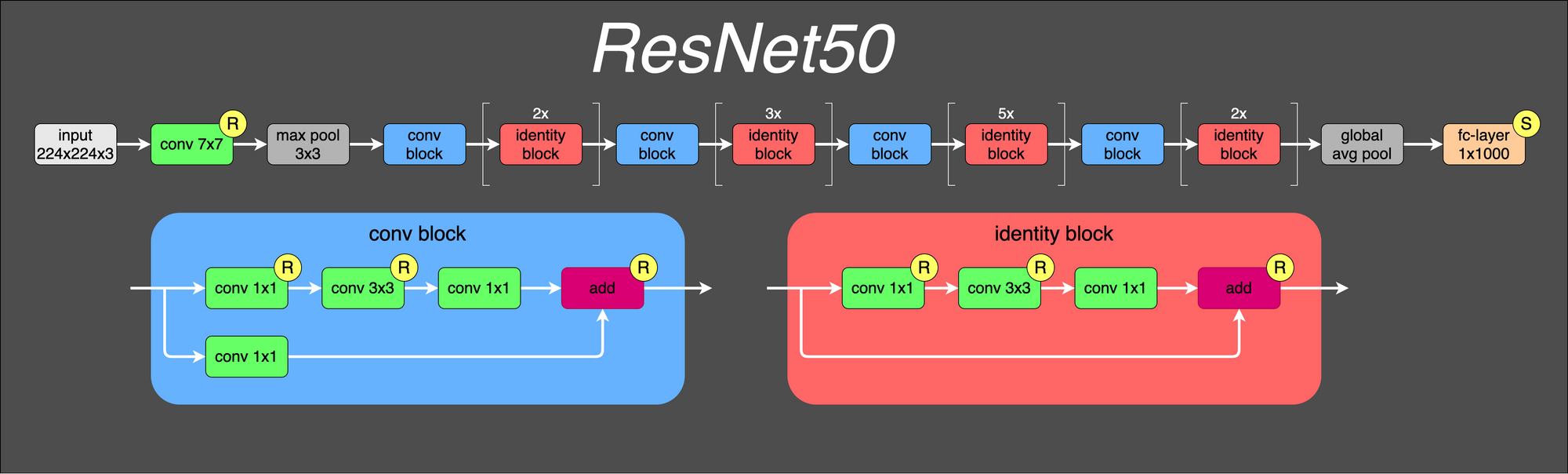
158 KB
Residual_Block.png
0 → 100644
{kind=link}
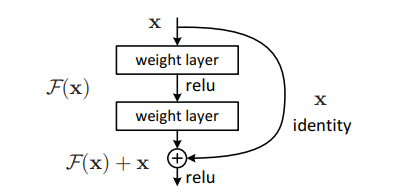
14.9 KB
result.png
0 → 100644
{kind=link}

4.7 MB
train_multi_fp16.sh
0 → 100755
train_multi_fp32.sh
0 → 100755
train_single_fp32.sh
0 → 100755