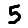| [Gradient Boosted Trees](boosted_trees) | A gradient boosted trees model to classify higgs boson process from HIGGS dataset | [Link](https://en.wikipedia.org/wiki/Gradient_boosting) |
| [MNIST](mnist) | A basic model to classify digits from the MNIST dataset | [Link](http://yann.lecun.com/exdb/mnist/) |
| [ResNet](resnet) | A deep residual network for image recognition | [arXiv:1512.03385](https://arxiv.org/abs/1512.03385) |
| [Transformer](transformer) | A transformer model to translate the WMT English to German dataset | [arXiv:1706.03762](https://arxiv.org/abs/1706.03762) |
| [Wide & Deep Learning](wide_deep) | A model that combines a wide linear model and deep neural network for recommender systems | [arXiv:1606.07792](https://arxiv.org/abs/1606.07792) |

# Classifying Higgs boson processes in the HIGGS Data Set
## Overview
The [HIGGS Data Set](https://archive.ics.uci.edu/ml/datasets/HIGGS) contains 11 million samples with 28 features, and is for the classification problem to distinguish between a signal process which produces Higgs bosons and a background process which does not.
We use Gradient Boosted Trees algorithm to distinguish the two classes.
---
The code sample uses the high level `tf.estimator.Estimator` and `tf.data.Dataset`. These APIs are great for fast iteration and quickly adapting models to your own datasets without major code overhauls. It allows you to move from single-worker training to distributed training, and makes it easy to export model binaries for prediction. Here, for further simplicity and faster execution, we use a utility function `tf.contrib.estimator.boosted_trees_classifier_train_in_memory`. This utility function is especially effective when the input is provided as in-memory data sets like numpy arrays.
An input function for the `Estimator` typically uses `tf.data.Dataset` API, which can handle various data control like streaming, batching, transform and shuffling. However `boosted_trees_classifier_train_in_memory()` utility function requires that the entire data is provided as a single batch (i.e. without using `batch()` API). Thus in this practice, simply `Dataset.from_tensors()` is used to convert numpy arrays into structured tensors, and `Dataset.zip()` is used to put features and label together.
For further references of `Dataset`, [Read more here](https://www.tensorflow.org/guide/datasets).
## Running the code
First make sure you've [added the models folder to your Python path](/official/#running-the-models); otherwise you may encounter an error like `ImportError: No module named official.boosted_trees`.
### Setup
The [HIGGS Data Set](https://archive.ics.uci.edu/ml/datasets/HIGGS) that this sample uses for training is hosted by the [UC Irvine Machine Learning Repository](https://archive.ics.uci.edu/ml/datasets/). We have provided a script that downloads and cleans the necessary files.
```
python data_download.py
```
This will download a file and store the processed file under the directory designated by `--data_dir` (defaults to `/tmp/higgs_data/`). To change the target directory, set the `--data_dir` flag. The directory could be network storages that Tensorflow supports (like Google Cloud Storage, `gs://<bucket>/<path>/`).
The file downloaded to the local temporary folder is about 2.8 GB, and the processed file is about 0.8 GB, so there should be enough storage to handle them.
### Training
This example uses about 3 GB of RAM during training.
You can run the code locally as follows:
```
python train_higgs.py
```
The model is by default saved to `/tmp/higgs_model`, which can be changed using the `--model_dir` flag.
Note that the model_dir is cleaned up before every time training starts.
Model parameters can be adjusted by flags, like `--n_trees`, `--max_depth`, `--learning_rate` and so on. Check out the code for details.
The final accuracy will be around 74% and loss will be around 0.516 over the eval set, when trained with the default parameters.
By default, the first 1 million examples among 11 millions are used for training, and the last 1 million examples are used for evaluation.
The training/evaluation data can be selected as index ranges by flags `--train_start`, `--train_count`, `--eval_start`, `--eval_count`, etc.
### TensorBoard
Run TensorBoard to inspect the details about the graph and training progression.
```
tensorboard --logdir=/tmp/higgs_model # set logdir as --model_dir set during training.
```
## Inference with SavedModel
You can export the model into Tensorflow [SavedModel](https://www.tensorflow.org/guide/saved_model) format by using the argument `--export_dir`:
After the model finishes training, use [`saved_model_cli`](https://www.tensorflow.org/guide/saved_model#cli_to_inspect_and_execute_savedmodel) to inspect and execute the SavedModel.
Try the following commands to inspect the SavedModel:
**Replace `${TIMESTAMP}` with the folder produced (e.g. 1524249124)**
```
# List possible tag_sets. Only one metagraph is saved, so there will be one option.
saved_model_cli show --dir /tmp/higgs_boosted_trees_saved_model/${TIMESTAMP}/
# Show SignatureDefs for tag_set=serve. SignatureDefs define the outputs to show.
saved_model_cli show --dir /tmp/higgs_boosted_trees_saved_model/${TIMESTAMP}/ \
--tag_set serve --all
```
### Inference
Let's use the model to predict the income group of two examples.
Note that this model exports SavedModel with the custom parsing module that accepts csv lines as features. (Each line is an example with 28 columns; be careful to not add a label column, unlike in the training data.)
```
saved_model_cli run --dir /tmp/boosted_trees_higgs_saved_model/${TIMESTAMP}/ \
This will print out the predicted classes and class probabilities. Something like:
```
Result for output key class_ids:
[[1]
[0]]
Result for output key classes:
[['1']
['0']]
Result for output key logistic:
[[0.6440273 ]
[0.10902369]]
Result for output key logits:
[[ 0.59288704]
[-2.1007526 ]]
Result for output key probabilities:
[[0.3559727 0.6440273]
[0.8909763 0.1090237]]
```
Please note that "predict" signature_def gives out different (more detailed) results than "classification" or "serving_default".
## Additional Links
If you are interested in distributed training, take a look at [Distributed TensorFlow](https://www.tensorflow.org/deploy/distributed).
You can also [train models on Cloud ML Engine](https://cloud.google.com/ml-engine/docs/getting-started-training-prediction), which provides [hyperparameter tuning](https://cloud.google.com/ml-engine/docs/getting-started-training-prediction#hyperparameter_tuning) to maximize your model's results and enables [deploying your model for prediction](https://cloud.google.com/ml-engine/docs/getting-started-training-prediction#deploy_a_model_to_support_prediction).
The SavedModel will be saved in a timestamped directory under `/tmp/mnist_saved_model/` (e.g. `/tmp/mnist_saved_model/1513630966/`).
**Getting predictions with SavedModel**
Use [`saved_model_cli`](https://www.tensorflow.org/guide/saved_model#cli_to_inspect_and_execute_savedmodel) to inspect and execute the SavedModel.
```
saved_model_cli run --dir /tmp/mnist_saved_model/TIMESTAMP --tag_set serve --signature_def classify --inputs image=examples.npy
```
`examples.npy` contains the data from `example5.png` and `example3.png` in a numpy array, in that order. The array values are normalized to values between 0 and 1.

# ResNet in TensorFlow
Deep residual networks, or ResNets for short, provided the breakthrough idea of
identity mappings in order to enable training of very deep convolutional neural
networks. This folder contains an implementation of ResNet for the ImageNet
dataset written in TensorFlow.
See the following papers for more background:
[1] [Deep Residual Learning for Image Recognition](https://arxiv.org/pdf/1512.03385.pdf) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, Dec 2015.
[2] [Identity Mappings in Deep Residual Networks](https://arxiv.org/pdf/1603.05027.pdf) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, Jul 2016.
In code, v1 refers to the ResNet defined in [1] but where a stride 2 is used on
the 3x3 conv rather than the first 1x1 in the bottleneck. This change results
in higher and more stable accuracy with less epochs than the original v1 and has
shown to scale to higher batch sizes with minimal degradation in accuracy.
There is no originating paper. The first mention we are aware of was in the
torch version of [ResNetv1](https://github.com/facebook/fb.resnet.torch). Most
popular v1 implementations are this implementation which we call ResNetv1.5.
In testing we found v1.5 requires ~12% more compute to train and has 6% reduced
throughput for inference compared to ResNetv1. CIFAR-10 ResNet does not use the
bottleneck and is thus the same for v1 as v1.5.
v2 refers to [2]. The principle difference between the two versions is that v1
applies batch normalization and activation after convolution, while v2 applies
batch normalization, then activation, and finally convolution. A schematic
comparison is presented in Figure 1 (left) of [2].
Please proceed according to which dataset you would like to train/evaluate on:
## CIFAR-10
### Setup
You need to have the latest version of TensorFlow installed.
First, make sure [the models folder is in your Python path](/official/#running-the-models); otherwise you may encounter `ImportError: No module named official.resnet`.
Then, download and extract the CIFAR-10 data from Alex's website, specifying the location with the `--data_dir` flag. Run the following:
Use `--data_dir` to specify the location of the CIFAR-10 data used in the previous step. There are more flag options as described in `cifar10_main.py`.
To export a `SavedModel` from the trained checkpoint:
Note: The `<EXPORT_DIR>` must be present. You might want to run `mkdir <EXPORT_DIR>` beforehand.
The `SavedModel` can then be [loaded](https://www.tensorflow.org/guide/saved_model#loading_a_savedmodel_in_python) in order to use the ResNet for prediction.
## ImageNet
### Setup
To begin, you will need to download the ImageNet dataset and convert it to
TFRecord format. The following [script](https://github.com/tensorflow/tpu/blob/master/tools/datasets/imagenet_to_gcs.py)
and [README](https://github.com/tensorflow/tpu/tree/master/tools/datasets#imagenet_to_gcspy)
provide a few options.
Once your dataset is ready, you can begin training the model as follows:
The model will begin training and will automatically evaluate itself on the
validation data roughly once per epoch.
Note that there are a number of other options you can specify, including
`--model_dir` to choose where to store the model and `--resnet_size` to choose
the model size (options include ResNet-18 through ResNet-200). See
[`resnet_run_loop.py`](resnet_run_loop.py) for the full list of options.
## Compute Devices
Training is accomplished using the DistributionStrategies API. (https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/distribute/README.md)
The appropriate distribution strategy is chosen based on the `--num_gpus` flag.
By default this flag is one if TensorFlow is compiled with CUDA, and zero
otherwise.
num_gpus:
+ 0: Use OneDeviceStrategy and train on CPU.
+ 1: Use OneDeviceStrategy and train on GPU.
+ 2+: Use MirroredStrategy (data parallelism) to distribute a batch between devices.
### Pre-trained model
You can download pre-trained versions of ResNet-50. Reported accuracies are top-1 single-crop accuracy for the ImageNet validation set.
Models are reported as both checkpoints produced by Estimator during training, and as SavedModels which are more portable. Checkpoints are fragile,
and these are not guaranteed to work with future versions of the code. Both ResNet v1
and ResNet v2 have been trained in both fp16 and fp32 precision. (Here v1 refers to "v1.5". See the note above.) Furthermore, SavedModels
are generated to accept either tensor or JPG inputs, and with channels_first (NCHW) and channels_last (NHWC) convolutions. NCHW is generally
better for GPUs, while NHWC is generally better for CPUs. See the TensorFlow [performance guide](https://www.tensorflow.org/performance/performance_guide#data_formats)
You can use a pretrained model to initialize a training process. In addition you are able to freeze all but the final fully connected layers to fine tune your model. Transfer Learning is useful when training on your own small datasets. For a brief look at transfer learning in the context of convolutional neural networks, we recommend reading these [short notes](http://cs231n.github.io/transfer-learning/).
To fine tune a pretrained resnet you must make three changes to your training procedure:
1) Build the exact same model as previously except we change the number of labels in the final classification layer.
2) Restore all weights from the pre-trained resnet except for the final classification layer; this will get randomly initialized instead.
3) Freeze earlier layers of the network
We can perform these three operations by specifying two flags: ```--pretrained_model_checkpoint_path``` and ```--fine_tune```. The first flag is a string that points to the path of a pre-trained resnet model. If this flag is specified, it will load all but the final classification layer. A key thing to note: if both ```--pretrained_model_checkpoint_path``` and a non empty ```model_dir``` directory are passed, the tensorflow estimator will load only the ```model_dir```. For more on this please see [WarmStartSettings](https://www.tensorflow.org/versions/master/api_docs/python/tf/estimator/WarmStartSettings) and [Estimators](https://www.tensorflow.org/guide/estimators).
The second flag ```--fine_tune``` is a boolean that indicates whether earlier layers of the network should be frozen. You may set this flag to false if you wish to continue training a pre-trained model from a checkpoint. If you set this flag to true, you can train a new classification layer from scratch.

{kind=link}
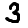
{kind=link}